Transformer
Transformer sind neuronale Netzwerke, die Attention-Mechanismen nutzen, um sequenzielle Daten effizient zu verarbeiten, und überzeugen in den Bereichen NLP, Spracherkennung, Genomik und mehr.
Ein Transformer-Modell ist eine Art von neuronalen Netzwerk, das speziell für die Verarbeitung von sequenziellen Daten wie Text, Sprache oder Zeitreihendaten entwickelt wurde. Im Gegensatz zu traditionellen Modellen wie Recurrent Neural Networks (RNNs) und Convolutional Neural Networks (CNNs) nutzen Transformer einen Mechanismus namens „Attention“ oder „Self-Attention“, um die Bedeutung verschiedener Elemente in der Eingabesequenz zu gewichten. Dadurch kann das Modell langreichweitige Abhängigkeiten und Beziehungen innerhalb der Daten erfassen, was es für eine Vielzahl von Anwendungen besonders leistungsfähig macht.
Wie funktionieren Transformer-Modelle?
Attention-Mechanismus
Im Zentrum eines Transformer-Modells steht der Attention-Mechanismus, der es dem Modell ermöglicht, sich beim Treffen von Vorhersagen auf verschiedene Teile der Eingabesequenz zu konzentrieren. Dieser Mechanismus bewertet die Relevanz jedes Elements in der Sequenz und erlaubt es dem Modell, komplexe Muster und Abhängigkeiten zu erfassen, die traditionelle Modelle möglicherweise übersehen.
Self-Attention
Self-Attention ist eine spezielle Form des Attention-Mechanismus, die innerhalb von Transformern verwendet wird. Sie ermöglicht es dem Modell, die gesamte Eingabesequenz gleichzeitig zu betrachten, anstatt sie sequenziell zu verarbeiten. Diese Fähigkeit zur parallelen Verarbeitung verbessert nicht nur die Recheneffizienz, sondern steigert auch das Verständnis des Modells für komplexe Zusammenhänge in den Daten.
Architekturübersicht
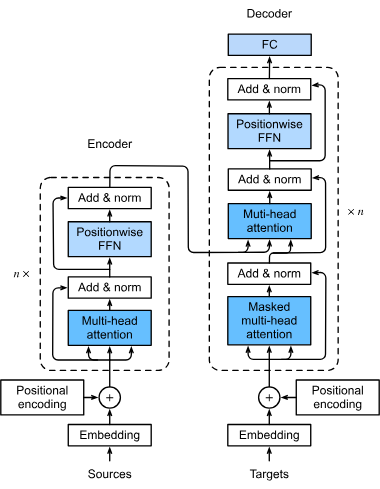
Ein typisches Transformer-Modell besteht aus einem Encoder und einem Decoder:
- Encoder: Verarbeitet die Eingabesequenz und erfasst deren Kontextinformationen.
- Decoder: Generiert die Ausgabesequenz basierend auf den kodierten Informationen.
Sowohl Encoder als auch Decoder bestehen aus mehreren Schichten von Self-Attention und Feedforward-Neuronalen Netzwerken, die übereinandergestapelt werden, um ein tiefes, leistungsstarkes Modell zu schaffen.
Anwendungsbereiche von Transformer-Modellen
Verarbeitung natürlicher Sprache (NLP)
Transformer sind das Rückgrat moderner NLP-Aufgaben. Sie werden eingesetzt für:
- Maschinelle Übersetzung: Übersetzen von Texten zwischen verschiedenen Sprachen.
- Textzusammenfassung: Komprimieren langer Artikel zu prägnanten Zusammenfassungen.
- Sentimentanalyse: Bestimmen der Stimmung in einem Textabschnitt.
Spracherkennung und -synthese
Transformer ermöglichen Echtzeit-Sprachübersetzung und -transkription und machen Meetings sowie Unterricht für verschiedene und hörgeschädigte Teilnehmer zugänglicher.
Genomik und Wirkstoffforschung
Durch die Analyse von Sequenzen von Genen und Proteinen beschleunigen Transformer das Design neuer Medikamente und die personalisierte Medizin.
Betrugserkennung und Empfehlungssysteme
Transformer erkennen Muster und Anomalien in großen Datensätzen und sind daher wertvoll bei der Aufdeckung von Betrugsfällen sowie bei der Generierung personalisierter Empfehlungen im E-Commerce und in Streaming-Diensten.
Der positive Kreislauf von Transformer-KI
Transformer profitieren von einem positiven Kreislauf: Durch ihren Einsatz in verschiedenen Anwendungen entstehen große Mengen an Daten, die wiederum zur Entwicklung noch genauerer und leistungsfähigerer Modelle dienen. Dieser Kreislauf aus Datengenerierung und Modellverbesserung treibt den Fortschritt in der KI weiter voran – einige Forscher sprechen bereits vom „Zeitalter der Transformer-KI“.
Transformer vs. traditionelle Modelle
Recurrent Neural Networks (RNNs)
Im Gegensatz zu RNNs, die Daten sequenziell verarbeiten, verarbeiten Transformer die gesamte Sequenz gleichzeitig. Das ermöglicht eine stärkere Parallelisierung und höhere Effizienz.
Convolutional Neural Networks (CNNs)
Während CNNs hervorragend für Bilddaten geeignet sind, glänzen Transformer bei der Verarbeitung sequenzieller Daten. Sie bieten eine vielseitigere und leistungsfähigere Architektur für ein breiteres Spektrum an Anwendungen.
Häufig gestellte Fragen
- Was ist ein Transformer-Modell?
Ein Transformer-Modell ist eine Architektur für neuronale Netzwerke, die entwickelt wurde, um sequenzielle Daten mithilfe eines Attention-Mechanismus zu verarbeiten. So können Beziehungen und Abhängigkeiten innerhalb der Daten effizient erfasst werden.
- Worin unterscheiden sich Transformer von RNNs und CNNs?
Im Gegensatz zu RNNs, die Daten sequenziell verarbeiten, verarbeiten Transformer die gesamte Eingabesequenz auf einmal, was eine höhere Effizienz ermöglicht. Während CNNs besonders für Bilddaten geeignet sind, glänzen Transformer bei der Verarbeitung von sequenziellen Daten wie Text und Sprache.
- Was sind die Hauptanwendungsbereiche von Transformer-Modellen?
Transformer werden vielseitig eingesetzt – von der Verarbeitung natürlicher Sprache über Spracherkennung und -synthese bis hin zur Genomik, Wirkstoffforschung, Betrugserkennung und Empfehlungssystemen. Sie sind besonders leistungsfähig bei komplexen sequenziellen Daten.
Beginnen Sie mit dem Aufbau eigener KI-Lösungen
Probieren Sie FlowHunt aus, um individuelle KI-Chatbots und Tools zu erstellen und dabei fortschrittliche Modelle wie Transformer für Ihre Geschäftsanforderungen zu nutzen.
Mehr erfahren
