
Dokumente
Ihr Chatbot kann sofort auf Dokumente, HTML-Seiten und sogar YouTube-Videos zugreifen und diese nutzen, um Ihren individuellen Kontext zu gestalten. Ideal, um I...
2 Min. Lesezeit
AI Chatbot
Knowledge Management
+3
Erfahren Sie, wie Sie die Parameter ‘Ab H1, falls vorhanden’, ‘Ab Markierung laden’ und ‘Letzten Header überspringen’ einrichten.
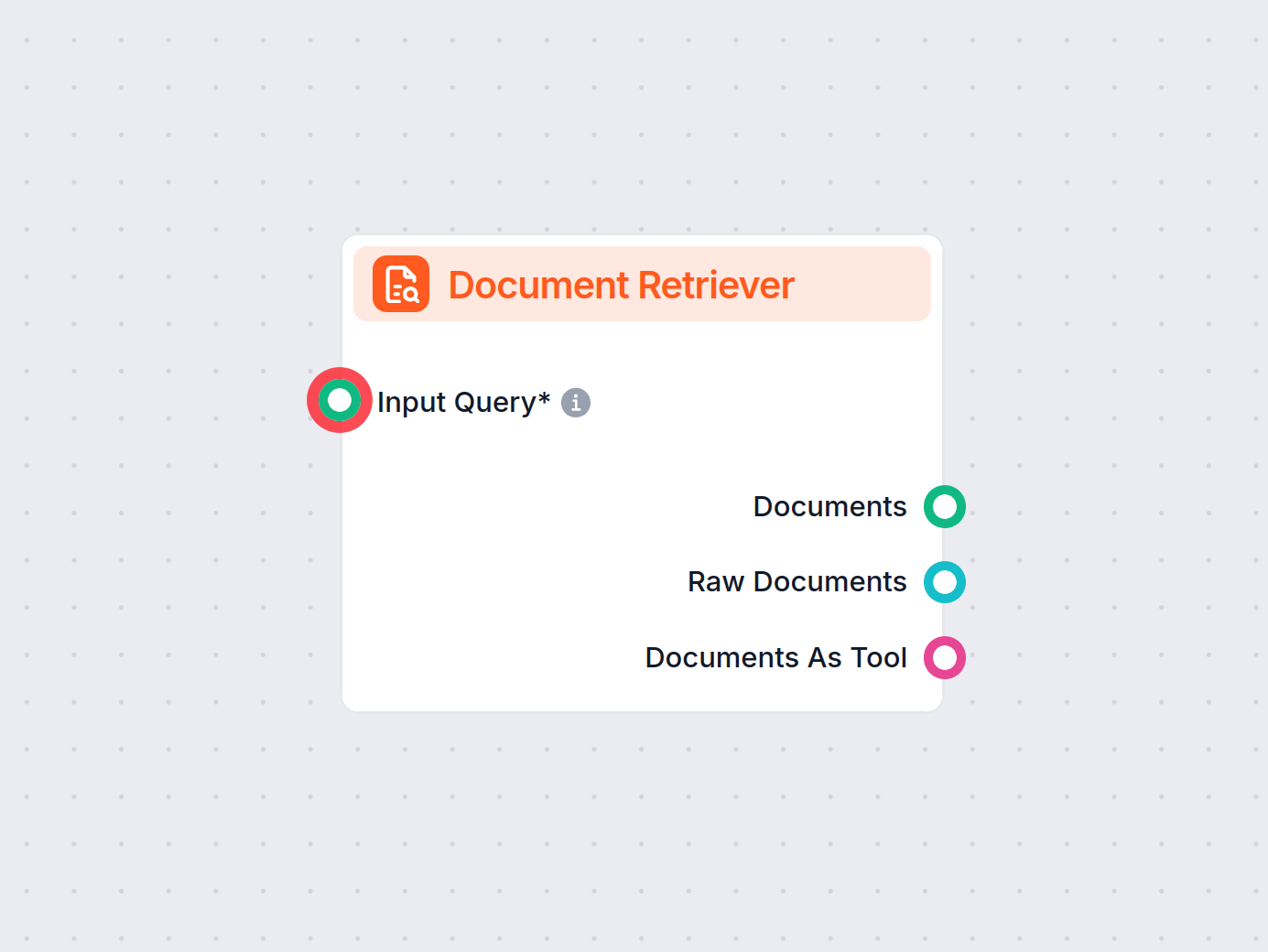
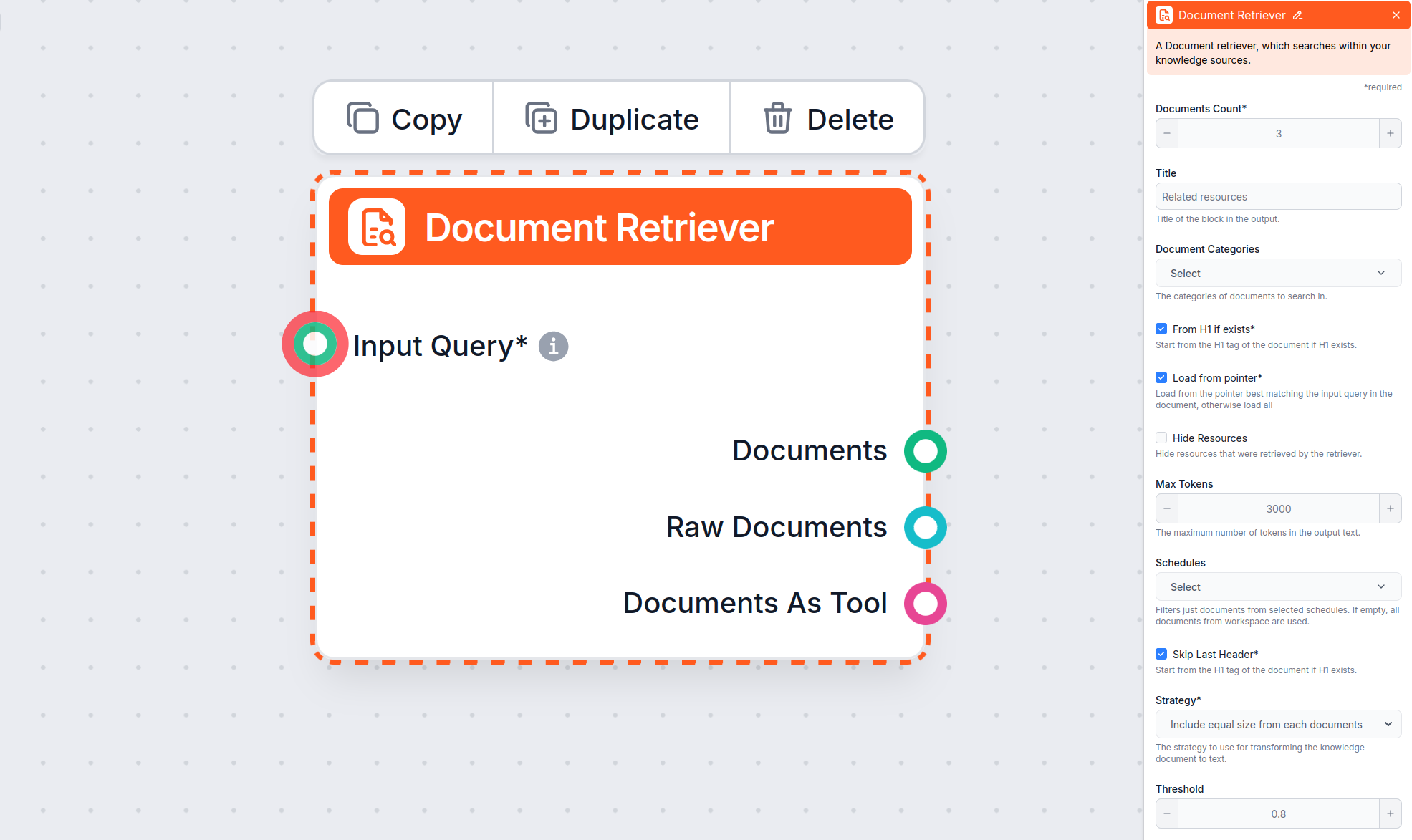
Die Document Retriever Komponente ermöglicht es dem Chatbot, Wissen aus den von Ihnen in den Dokumenten und Zeitplänen angegebenen Quellen abzurufen. Die Aufgabe dieser Komponente ist die Steuerung des Abrufs, wobei mehrere Parameter beeinflussen, wie die Komponente Informationen aus diesen Dokumenten extrahiert.
Die Option Ab H1, falls vorhanden weist den Retriever an, mit der Extraktion von Inhalten ab der gefundenen H1-Überschrift (meistens der Haupttitel des Artikels) zu beginnen.
Was passiert?
Anwendungsbeispiel:
Sie möchten nur den eigentlichen Leitfaden abrufen, ohne die Navigation der Website oder störende Kopfzeilen.
Hinweis:
Ab H1, falls vorhanden ist im Document Retriever standardmäßig aktiviert.
Mit der Option Ab Markierung laden können Sie noch präziser steuern, denn der Document Retriever lädt nur Daten ab einer Markierung in einem möglicherweise langen Artikel.
Was passiert?
Was ist eine “Markierung”?
Eine Markierung ist typischerweise eine eindeutige Zeichenfolge oder Überschrift im Dokument (z. B. eine H2 oder ein bestimmter Abschnittstitel oder eine einzelne Phrase).
Anwendungsbeispiel:
Sie möchten einleitende Abschnitte überspringen und Informationen zu einem bestimmten relevanten Abschnitt eines langen Artikels abrufen (z. B. ab “Schritt 4: Live-Chat-Button hinzufügen” in einer Anleitung).
Die Option Letzten Header überspringen ist nützlich, um die letzte Überschrift im Dokument zu ignorieren, die oft wiederholt wird oder als Navigation oder Fußzeile dient.
Was passiert?
Anwendungsbeispiel:
Sie möchten verhindern, dass der Document Retriever eine Fußzeilen-Navigationsüberschrift (wie “Weitere Artikel” am Ende einer Hilfeseite) lädt, sodass nur der eigentliche Hauptinhalt verarbeitet wird.
Hinweis:
Letzten Header überspringen kann bei Dokumenten helfen, die automatisch Fußzeilen oder wiederholte Navigationselemente generieren. Wenn Sie jedoch keine solchen Abschnitte haben, kann die Aktivierung dazu führen, dass relevante Informationen am Artikelende nicht abgerufen werden. Es empfiehlt sich daher, diese Option nur bei Bedarf zu aktivieren.
Mit dem Parameter Maximale Token steuern Sie, wie viele Token (Wörter und Satzzeichen, gezählt vom KI-Modell) der Document Retriever aus dem extrahierten Text maximal ausgibt.
Was passiert?
Standardwert:
Der Standardwert beträgt in der Regel 3000 Token, kann aber bei Bedarf angepasst werden.
Anwendungsbeispiel:
Wenn Sie sehr lange Dokumente verarbeiten, hilft ein niedrigerer Wert für Maximale Token, die Antworten prägnant zu halten. Für optimale Ergebnisse empfiehlt sich zudem die Aktivierung von “Ab Markierung laden”. So startet die Extraktion direkt am relevantesten Abschnitt, anstatt am Anfang, und Sie erhalten einen fokussierten, handhabbaren Ausschnitt innerhalb Ihres Token-Limits. Diese Kombination ist besonders hilfreich, wenn Sie prägnante, kontextrelevante Ausgaben aus großen Quellen wünschen.
Hinweis:
Wenn Sie feststellen, dass Informationen abgeschnitten werden, erhöhen Sie den Wert für Maximale Token. Möchten Sie dagegen kürzere, gezieltere Antworten, verringern Sie den Parameter.
Findet der Document Retriever mehrere relevante Dokumente, bestimmt der Parameter Strategie, wie sie zu einer einzigen Textausgabe für Ihren Chatbot zusammengefasst werden – unter Berücksichtigung des Limits für “Maximale Token”.
Zwei Strategieoptionen:
Gleiche Anzahl aus jedem Dokument einbeziehen:
Das Token-Limit wird gleichmäßig aufgeteilt. Bei drei Dokumenten und einem Limit von 3.000 Token erhält jedes bis zu 1.000 Token. So tragen alle Quellen gleichermaßen bei – ideal, wenn Sie eine ausgewogene Antwort aus mehreren Dokumenten wünschen.
Dokumente aneinanderhängen, ab dem relevantesten auffüllen bis Token-Limit erreicht:
Dokumente werden nach Relevanz hinzugefügt, bis das Token-Limit erreicht ist. Das relevanteste Dokument füllt den Platz zuerst; bleibt noch Raum, werden weniger relevante nach Reihenfolge ergänzt. Ist das erste Dokument lang, kann es das Limit allein ausschöpfen.
Wie entscheiden?
Hinweis:
Diese Strategien beeinflussen lediglich, wie der Text aus den abgerufenen Dokumenten zusammengesetzt wird, bevor er an den nächsten Schritt (z. B. KI-Generierung) übergeben wird. Sie ändern nicht, welche Dokumente abgerufen werden – nur, wie deren Inhalt zusammengeführt und auf das Token-Limit zugeschnitten wird.
Dieser Artikel konzentriert sich auf die Parameter ‘Ab H1, falls vorhanden’, ‘Ab Markierung laden’, ‘Letzten Header überspringen’ und ‘Maximale Token’. Der Document Retriever bietet jedoch noch weitere Optionen, mit denen Sie steuern, wie Dokumente ausgewählt und abgerufen werden:
Mit dieser Einstellung begrenzen Sie, wie viele Dokumente der Flow abrufen soll. So bleiben die Ergebnisse relevant und die Antwortzeiten kurz.
Mit dieser optionalen Einstellung können Sie die Suche auf eine oder mehrere Kategorien beschränken, die Sie im Abschnitt Dokumente der Wissensquellen angelegt haben.
Damit können Sie einen separaten Abschnitt mit einer Liste der abgerufenen Ressourcen ausblenden oder anzeigen, bevor die eigentliche Chatbot-Antwort folgt. Für die Integration mit LiveAgent muss diese Option aktiviert sein, da dieser Abschnitt dort nicht unterstützt wird und im LiveAgent-Widget nicht korrekt angezeigt werden kann.
Ermöglicht es, die Suche auf einen oder mehrere Zeitpläne zu beschränken, die Sie für das Crawling oder die Aktualisierung von Inhalten in Wissensquellen definiert haben.
Steuert, wie genau die abgerufenen Dokumente mit der Eingabeanfrage übereinstimmen müssen – gemessen an einem Relevanz-Score (von 0 bis 1). Für besonders relevante Antworten empfiehlt sich ein Schwellenwert von 0,7–0,8. Höhere Werte liefern präzisere Ergebnisse, niedrigere schließen unter Umständen weniger relevante Dokumente ein.
Beispiel:
Setzen Sie den Schwellenwert auf 0,6 und haben vier Artikel mit Relevanzwerten von 0,8, 0,65, 0,5 und 0,9, werden nur die mit mehr als 0,6 (also 0,8, 0,65 und 0,9) zur Extraktion herangezogen.
Wenn die vom Chatbot gegebene Antwort keine Informationen enthält, von denen Sie sicher wissen, dass sie in Ihren Dokumenten oder Zeitplänen vorhanden sind, überprüfen Sie die Gesprächshistorie mit der Option “Verbose”. Dort sehen Sie detaillierte Protokolle darüber, ob der Document Retriever verwendet wurde und welche Dokumente abgerufen wurden. Passen Sie bei Bedarf Ihre Einstellungen und Eingaben anhand dieser Protokolle an.
Ihr Chatbot kann sofort auf Dokumente, HTML-Seiten und sogar YouTube-Videos zugreifen und diese nutzen, um Ihren individuellen Kontext zu gestalten. Ideal, um I...
FlowHunts Dokumenten-Retriever verbessert die Genauigkeit von KI, indem generative Modelle mit Ihren eigenen aktuellen Dokumenten und URLs verbunden werden. So ...
Die Document to Text-Komponente von FlowHunt wandelt strukturierte Daten aus Retrievern in lesbaren Markdown-Text um und gibt Ihnen präzise Kontrolle darüber, w...