
LLM Mistral
LLM Mistral en FlowHunt permite la integración flexible de avanzados modelos de IA de Mistral para una generación de texto fluida en chatbots y herramientas de IA.
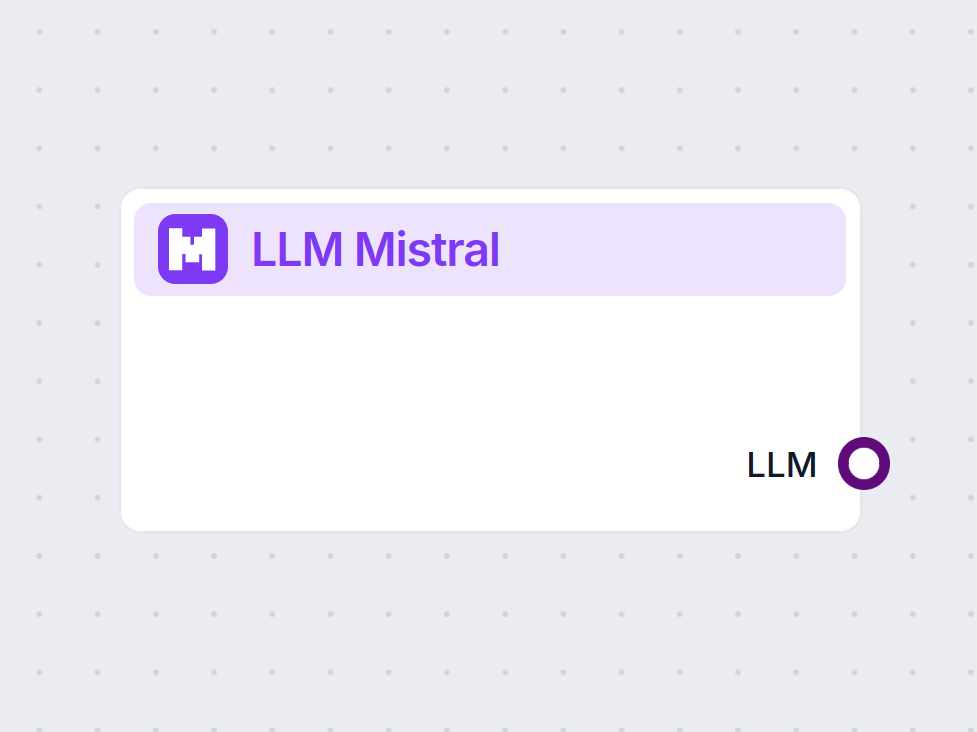
Descripción del componente
Cómo funciona el componente LLM Mistral
¿Qué es el componente LLM Mistral?
El componente LLM Mistral conecta los modelos de Mistral a tu flujo. Mientras que los Generadores y Agentes son donde ocurre la verdadera magia, los componentes LLM te permiten controlar el modelo que se utiliza. Todos los componentes vienen con ChatGPT-4 por defecto. Puedes conectar este componente si deseas cambiar el modelo o tener más control sobre él.
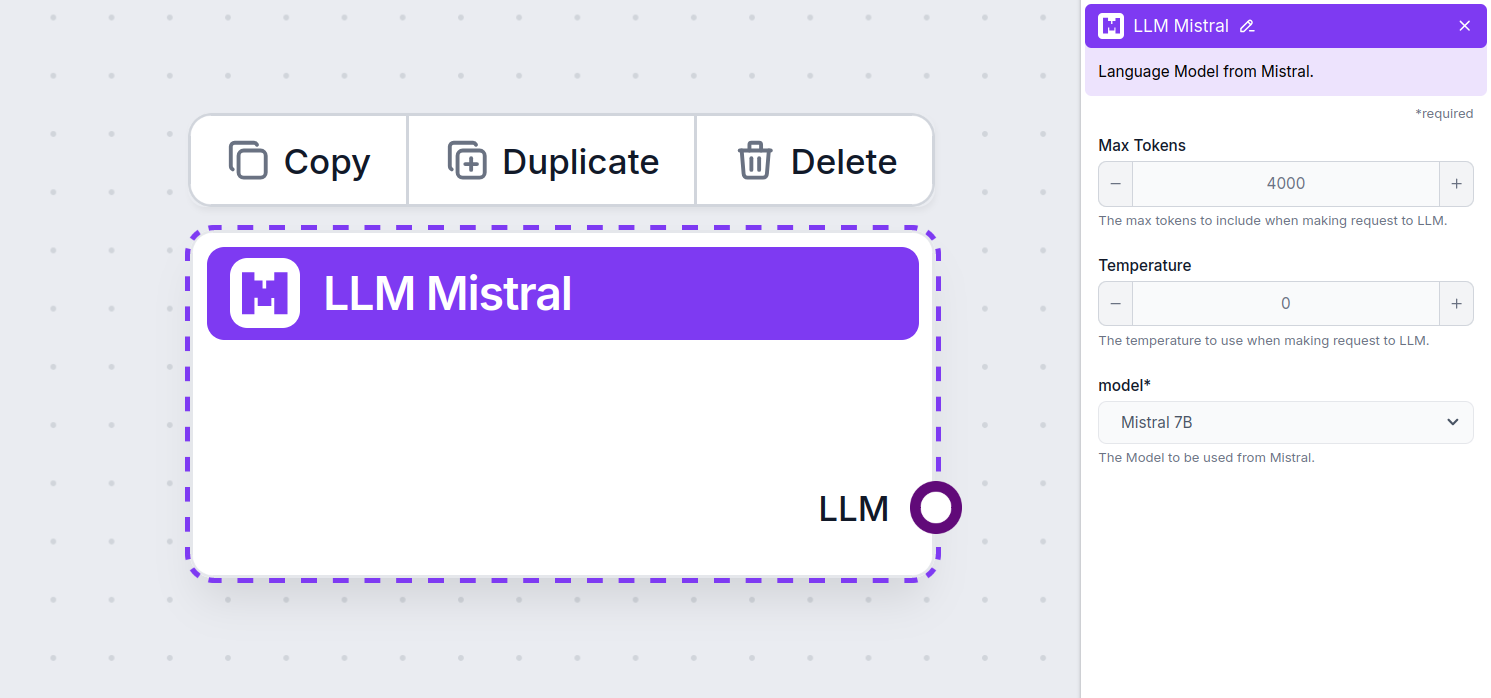
Recuerda que conectar un componente LLM es opcional. Todos los componentes que usan un LLM vienen con ChatGPT-4o como predeterminado. Los componentes LLM te permiten cambiar el modelo y controlar la configuración del modelo.
Configuración del componente LLM Mistral
Máximo de Tokens
Los tokens representan las unidades individuales de texto que el modelo procesa y genera. El uso de tokens varía según los modelos, y un solo token puede ser una palabra, subpalabra o incluso un solo carácter. Los modelos suelen tener precios por millones de tokens.
La configuración de máximo de tokens limita el número total de tokens que se pueden procesar en una sola interacción o solicitud, asegurando que las respuestas se generen dentro de límites razonables. El límite predeterminado es de 4,000 tokens, que es el tamaño óptimo para resumir documentos y varias fuentes para generar una respuesta.
Temperatura
La temperatura controla la variabilidad de las respuestas, en un rango de 0 a 1.
Una temperatura de 0.1 hará que las respuestas sean muy directas pero potencialmente repetitivas y deficientes.
Una temperatura alta de 1 permite la máxima creatividad en las respuestas, pero genera el riesgo de respuestas irrelevantes o incluso alucinatorias.
Por ejemplo, la temperatura recomendada para un bot de atención al cliente es entre 0.2 y 0.5. Este nivel debería mantener las respuestas relevantes y ajustadas al guion, permitiendo al mismo tiempo cierta variación natural.
Modelo
Este es el selector de modelo. Aquí encontrarás todos los modelos compatibles de Mistral. Actualmente admitimos los siguientes modelos:
- Mistral 7B – Un modelo de lenguaje con 7.3 mil millones de parámetros que utiliza la arquitectura transformers, lanzado bajo la licencia Apache 2.0. A pesar de ser un proyecto más pequeño, supera de forma rutinaria al modelo Llama 2 de Meta. Consulta nuestros resultados de prueba.
- Mistral 8x7B (Mixtral) – Este modelo emplea una arquitectura de mezcla dispersa de expertos, compuesta por ocho grupos distintos de “expertos”, sumando un total de 46.7 mil millones de parámetros. Cada token utiliza hasta 12.9 mil millones de parámetros, ofreciendo un rendimiento que iguala o supera a LLaMA 2 70B y GPT-3.5 en la mayoría de los benchmarks. Mira ejemplos de salida.
- Mistral Large – Un modelo de lenguaje de alto rendimiento con 123 mil millones de parámetros y una longitud de contexto de 128,000 tokens. Es fluido en varios idiomas, incluidos lenguajes de programación, y demuestra un rendimiento competitivo con modelos como LLaMA 3.1 405B, especialmente en tareas relacionadas con programación. Más información aquí.
Cómo agregar el LLM Mistral a tu flujo
Notarás que todos los componentes LLM solo tienen un conector de salida. La entrada no pasa por el componente, ya que solo representa el modelo, mientras que la generación real ocurre en los Agentes de IA y Generadores.
El conector LLM siempre es de color morado. El conector de entrada LLM se encuentra en cualquier componente que use IA para generar texto o procesar datos. Puedes ver las opciones haciendo clic en el conector:
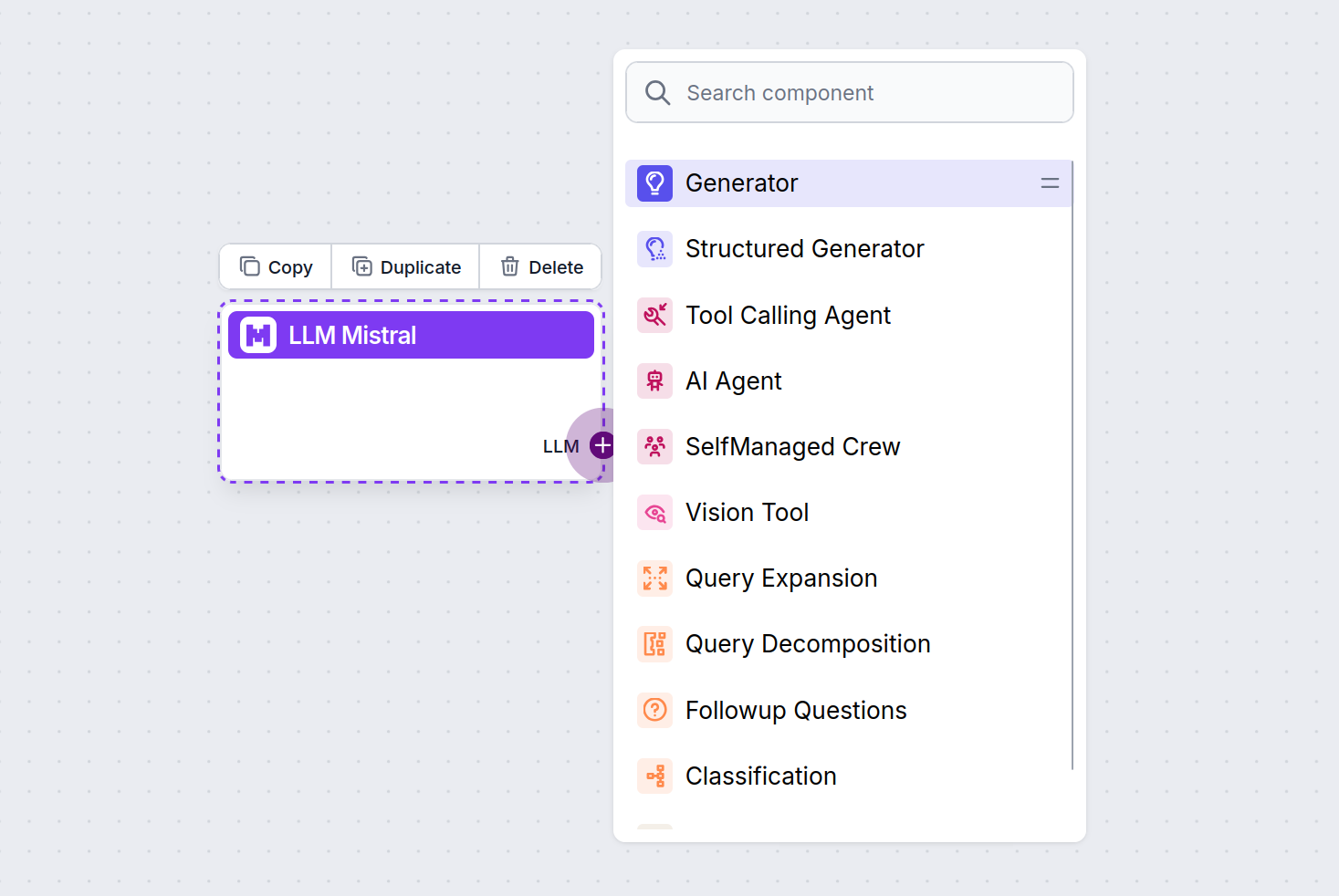
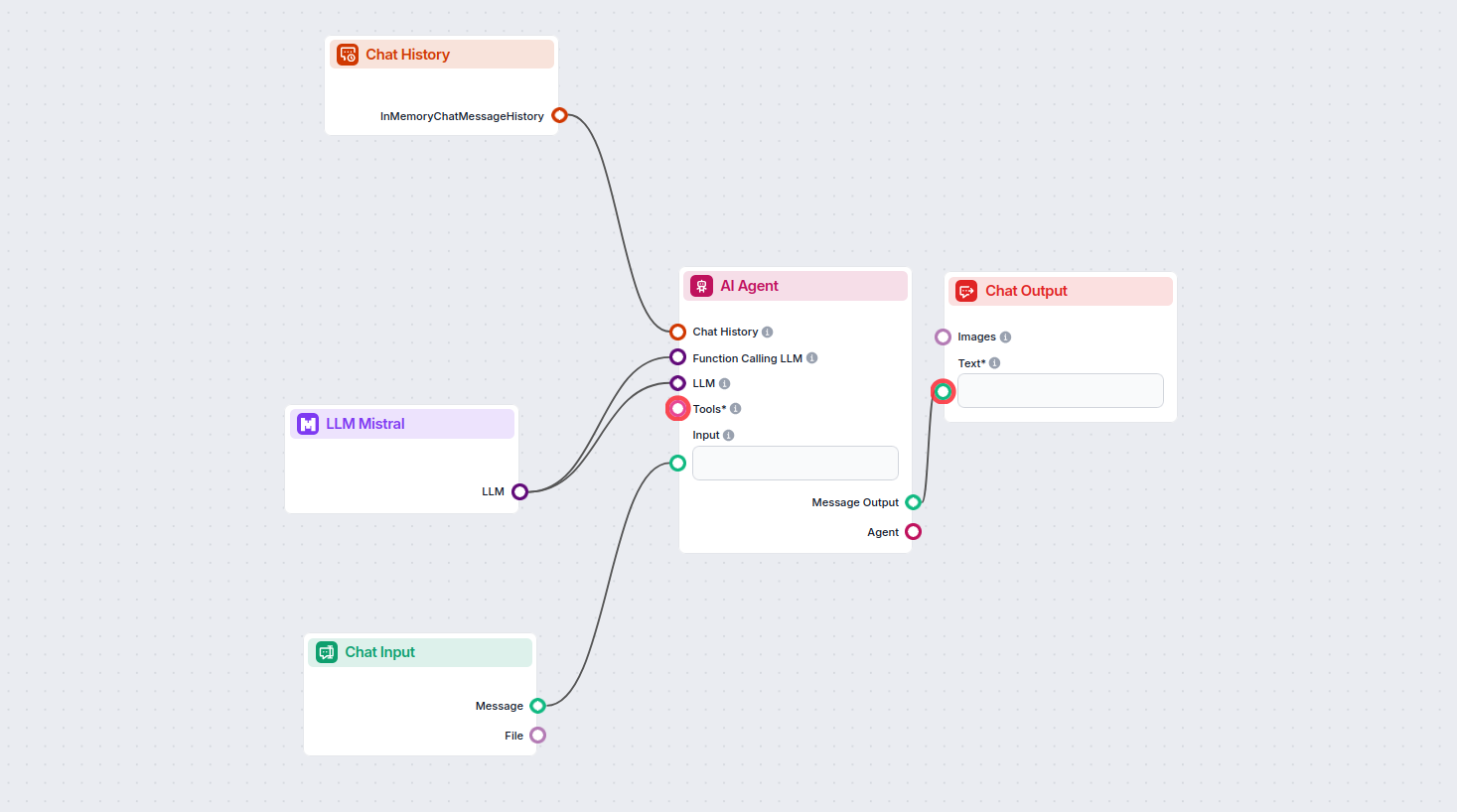
Esto te permite crear todo tipo de herramientas. Veamos el componente en acción. Aquí tienes un flujo simple de chatbot AI Agent que utiliza el modelo Mistral 7B para generar respuestas. Puedes considerarlo como un chatbot básico de Mistral.
Este flujo simple de Chatbot incluye:
- Entrada de chat: Representa el mensaje que el usuario envía en el chat.
- Historial de chat: Garantiza que el chatbot pueda recordar y tener en cuenta respuestas anteriores.
- Salida de chat: Representa la respuesta final del chatbot.
- Agente de IA: Un agente autónomo de IA que genera respuestas.
- LLM Mistral: La conexión con los modelos de generación de texto de Mistral.
Preguntas frecuentes
- ¿Qué es el componente LLM Mistral en FlowHunt?
El componente LLM Mistral te permite conectar modelos de IA de Mistral a tus proyectos de FlowHunt, habilitando la generación avanzada de texto para tus chatbots y agentes de IA. Permite intercambiar modelos, controlar configuraciones e integrar modelos como Mistral 7B, Mixtral (8x7B) y Mistral Large.
- ¿Qué modelos de Mistral admite FlowHunt?
FlowHunt admite Mistral 7B, Mixtral (8x7B) y Mistral Large, cada uno ofreciendo diferentes niveles de rendimiento y parámetros para diversas necesidades de generación de texto.
- ¿Qué configuraciones puedo personalizar con el componente LLM Mistral?
Puedes ajustar configuraciones como el máximo de tokens y la temperatura, y seleccionar entre los modelos de Mistral admitidos para controlar la longitud de la respuesta, la creatividad y el comportamiento del modelo dentro de tus flujos.
- ¿Es obligatorio conectar el componente LLM Mistral en cada proyecto?
No, conectar un componente LLM es opcional. Por defecto, los componentes de FlowHunt usan ChatGPT-4o. Utiliza el componente LLM Mistral cuando quieras más control o usar un modelo específico de Mistral.
Prueba LLM Mistral de FlowHunt hoy
Empieza a crear chatbots y herramientas de IA más inteligentes integrando los potentes modelos de lenguaje de Mistral con la plataforma sin código de FlowHunt.
Saber más

