Embeddings de Palabras
Los embeddings de palabras mapean palabras a vectores en un espacio continuo, capturando su significado y contexto para mejorar las aplicaciones de PLN.
Procesamiento de Lenguaje Natural (PLN) - Embeddings
Los embeddings de palabras son fundamentales en el PLN y sirven de puente en la interacción humano-computadora. Descubre sus aspectos clave, funcionamiento y aplicaciones hoy por varias razones:
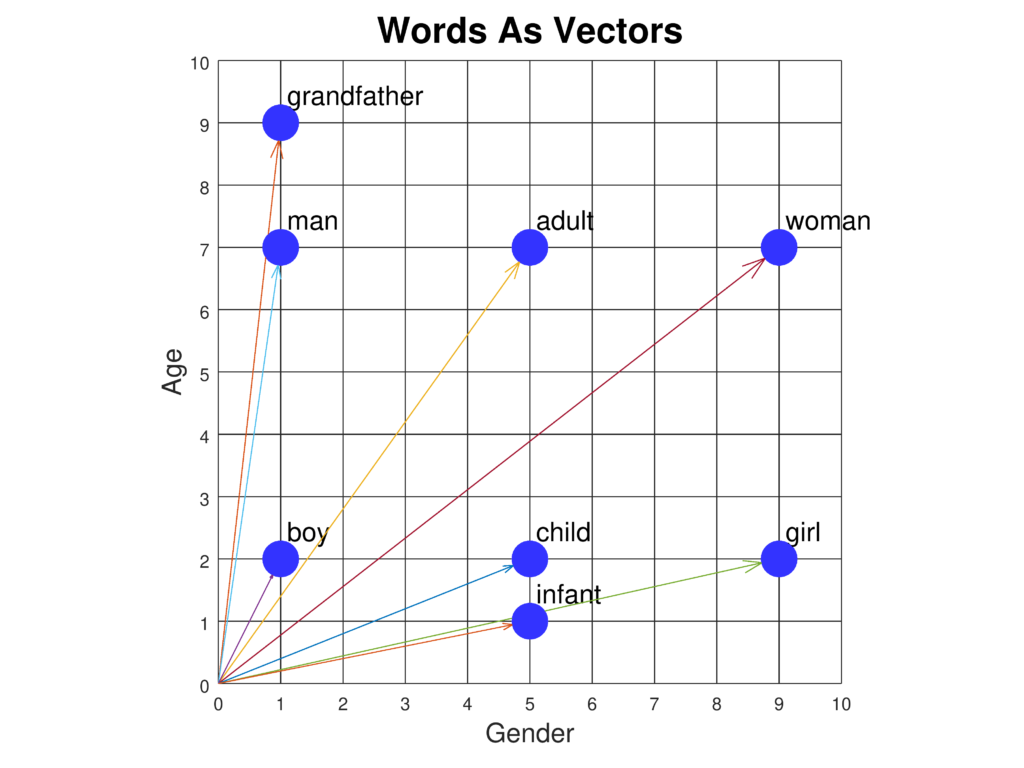
- Comprensión Semántica: Permiten que los modelos capturen el significado de las palabras y sus relaciones entre sí, posibilitando una comprensión más matizada del lenguaje. Por ejemplo, los embeddings pueden captar analogías como “rey es a reina como hombre es a mujer”.
- Reducción de Dimensionalidad: Representar palabras en un espacio denso y de menor dimensión reduce la carga computacional y mejora la eficiencia en el procesamiento de grandes vocabularios.
- Aprendizaje por Transferencia: Los embeddings preentrenados pueden utilizarse en diferentes tareas de PLN, disminuyendo la necesidad de grandes cantidades de datos específicos y recursos computacionales.
- Gestión de Grandes Vocabularios: Permiten manejar vocabularios extensos y tratar palabras poco frecuentes de manera más eficaz, mejorando el desempeño del modelo en conjuntos de datos diversos.
Conceptos y Técnicas Clave
- Representaciones Vectoriales: Las palabras se transforman en vectores en un espacio de alta dimensión. La proximidad y direccionalidad entre estos vectores indican la similitud semántica y las relaciones entre palabras.
- Significado Semántico: Los embeddings encapsulan la esencia semántica de las palabras, permitiendo a los modelos realizar análisis de sentimientos, reconocimiento de entidades y traducción automática con mayor precisión.
- Reducción de Dimensionalidad: Al condensar datos de alta dimensión en formatos más manejables, los embeddings mejoran la eficiencia computacional de los modelos de PLN.
- Redes Neuronales: Muchos embeddings se generan utilizando redes neuronales, ejemplificadas por modelos como Word2Vec y GloVe, que aprenden a partir de extensos corpus de texto.
Técnicas Comunes de Embedding de Palabras
- Word2Vec: Desarrollada por Google, esta técnica utiliza modelos como Continuous Bag of Words (CBOW) y Skip-gram para predecir una palabra en función de su contexto o viceversa.
- GloVe (Global Vectors for Word Representation): Utiliza estadísticas globales de coocurrencia de palabras para derivar embeddings, enfatizando las relaciones semánticas mediante factorización de matrices.
- FastText: Mejora Word2Vec incorporando información de subpalabras (n-gramas de caracteres), lo que permite manejar mejor palabras poco frecuentes o fuera de vocabulario.
- TF-IDF (Term Frequency-Inverse Document Frequency): Un método basado en la frecuencia que resalta las palabras significativas en un documento respecto a un corpus, aunque carece de la profundidad semántica de los embeddings neuronales.
Casos de Uso en PLN
- Clasificación de Texto: Los embeddings mejoran la clasificación de texto proporcionando representaciones semánticas ricas, aumentando la precisión en tareas como análisis de sentimiento y detección de spam.
- Traducción Automática: Facilitan la traducción entre idiomas al capturar relaciones semánticas, esenciales para sistemas como Google Translate.
- Reconocimiento de Entidades Nombradas (NER): Ayudan a identificar y clasificar entidades como nombres, organizaciones y lugares, comprendiendo el contexto y la semántica.
- Recuperación de Información y Búsqueda: Mejoran los motores de búsqueda al captar relaciones semánticas, permitiendo resultados más relevantes y contextualizados.
- Sistemas de Preguntas y Respuestas: Mejoran la comprensión de consultas y contexto, generando respuestas más precisas y relevantes.
Desafíos y Limitaciones
- Polisemia: Los embeddings clásicos tienen dificultades con palabras que tienen múltiples significados. Embeddings contextuales como BERT buscan resolver esto proporcionando diferentes vectores según el contexto.
- Sesgo en Datos de Entrenamiento: Los embeddings pueden perpetuar sesgos presentes en los datos de entrenamiento, afectando la equidad y precisión en las aplicaciones.
- Escalabilidad: El entrenamiento de embeddings en grandes corpus requiere considerables recursos computacionales, aunque técnicas como embeddings de subpalabras y reducción de dimensionalidad pueden aliviar este problema.
Modelos Avanzados y Desarrollos
- BERT (Bidirectional Encoder Representations from Transformers): Un modelo basado en transformers que genera embeddings contextuales considerando el contexto completo de la oración, ofreciendo un rendimiento superior en numerosas tareas de PLN.
- GPT (Generative Pre-trained Transformer): Se centra en producir textos coherentes y contextualmente relevantes, utilizando embeddings para comprender y generar texto similar al humano.
Investigación sobre Embeddings de Palabras en PLN
Learning Word Sense Embeddings from Word Sense Definitions
Qi Li, Tianshi Li, Baobao Chang (2016) proponen un método para abordar el desafío de las palabras polisémicas y homónimas en los embeddings de palabras, creando un embedding por sentido a partir de definiciones de sentido. Su enfoque aprovecha el entrenamiento basado en corpus para lograr embeddings de alta calidad por sentido de palabra. Los resultados experimentales muestran mejoras en tareas de similitud de palabras y desambiguación de sentidos. El estudio demuestra el potencial de los embeddings de sentidos para mejorar las aplicaciones de PLN. Leer másNeural-based Noise Filtering from Word Embeddings
Kim Anh Nguyen, Sabine Schulte im Walde, Ngoc Thang Vu (2016) presentan dos modelos para mejorar los embeddings de palabras mediante filtrado de ruido. Identifican información innecesaria en los embeddings tradicionales y proponen técnicas de aprendizaje no supervisado para crear embeddings denoising. Estos modelos utilizan una red neuronal profunda para destacar la información relevante y minimizar el ruido. Los resultados indican un rendimiento superior de los embeddings denoising en tareas de referencia. Leer másA Survey On Neural Word Embeddings
Erhan Sezerer, Selma Tekir (2021) ofrecen una revisión exhaustiva de los embeddings neuronales de palabras, rastreando su evolución e impacto en el PLN. El estudio cubre teorías fundamentales y explora diversos tipos de embeddings, como de sentido, morfema y contextuales. También analiza conjuntos de datos de referencia y evaluaciones de desempeño, destacando el efecto transformador de los embeddings neuronales en tareas de PLN. Leer másImproving Interpretability via Explicit Word Interaction Graph Layer
Arshdeep Sekhon, Hanjie Chen, Aman Shrivastava, Zhe Wang, Yangfeng Ji, Yanjun Qi (2023) se centran en mejorar la interpretabilidad de los modelos de PLN mediante WIGRAPH, una capa de red neuronal que construye un grafo global de interacciones entre palabras. Esta capa puede integrarse en cualquier clasificador de texto PLN, mejorando tanto la interpretabilidad como el rendimiento predictivo. El estudio resalta la importancia de las interacciones de palabras para comprender las decisiones del modelo. Leer másWord Embeddings for Banking Industry
Avnish Patel (2023) explora la aplicación de los embeddings de palabras en el sector bancario, destacando su papel en tareas como análisis de sentimientos y clasificación de texto. El estudio examina el uso de embeddings estáticos (por ejemplo, Word2Vec, GloVe) y modelos contextuales, enfatizando su impacto en tareas de PLN específicas para la industria. Leer más
Preguntas frecuentes
- ¿Qué son los embeddings de palabras?
Los embeddings de palabras son representaciones densas en vectores de las palabras, mapeando palabras semánticamente similares a puntos cercanos en un espacio continuo, lo que permite a los modelos comprender el contexto y las relaciones en el lenguaje.
- ¿Cómo mejoran los embeddings de palabras las tareas de PLN?
Mejoran las tareas de PLN al capturar relaciones semánticas y sintácticas, reducir la dimensionalidad, permitir el aprendizaje por transferencia y mejorar el manejo de palabras poco frecuentes.
- ¿Cuáles son las técnicas comunes para crear embeddings de palabras?
Las técnicas más populares incluyen Word2Vec, GloVe, FastText y TF-IDF. Los modelos neuronales como Word2Vec y GloVe aprenden embeddings a partir de grandes corpus de texto, mientras que FastText incorpora información de subpalabras.
- ¿Qué desafíos enfrentan los embeddings de palabras?
Los embeddings clásicos tienen dificultades con la polisemia (palabras con múltiples significados), pueden perpetuar sesgos presentes en los datos y pueden requerir recursos computacionales significativos para su entrenamiento en grandes corpus.
- ¿Cómo se utilizan los embeddings de palabras en aplicaciones reales?
Se utilizan en clasificación de texto, traducción automática, reconocimiento de entidades nombradas, recuperación de información y sistemas de preguntas y respuestas para mejorar la precisión y la comprensión contextual.
Prueba FlowHunt para Soluciones de PLN
Comienza a construir soluciones avanzadas de IA con herramientas intuitivas para PLN, incluyendo embeddings de palabras y más.