
Documentos
Tu chatbot puede acceder y utilizar al instante documentos, páginas HTML e incluso videos de YouTube para adaptar tu contexto único. Perfecto para agregar infor...
3 min de lectura
AI Chatbot
Knowledge Management
+3
Aprende cómo configurar los parámetros ‘Desde H1 si existe’, ‘Cargar desde puntero’ y ‘Omitir último encabezado’.
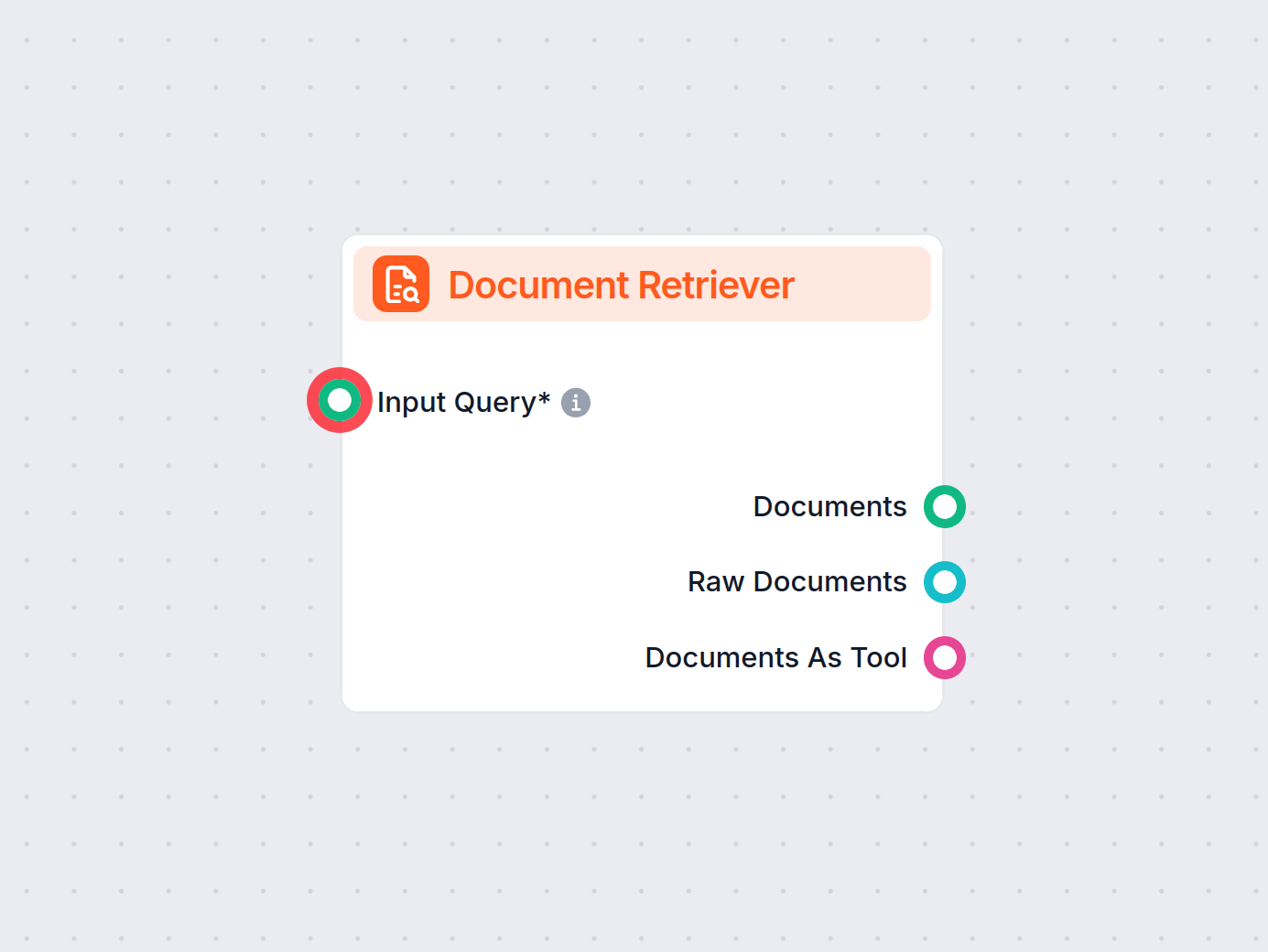
El componente Document Retriever permite al chatbot recuperar conocimiento de las fuentes que especifiques en Documentos y Programaciones. El papel de este componente es controlar la recuperación y múltiples parámetros afectan cómo recupera la información de esos documentos.
La opción Desde H1 si existe le indica al recuperador que comience a extraer contenido desde el encabezado H1 que encuentre (habitualmente el título principal del artículo).
¿Qué sucede?
Ejemplo de caso de uso:
Quieres recuperar solo la guía real, sin la navegación del sitio ni encabezados de página que generan ruido en tu web.
Nota:
Desde H1 si existe está activado por defecto en el componente Document Retriever.
La opción Cargar desde puntero te da mayor precisión permitiéndole al Document Retriever cargar solo los datos desde un puntero en el artículo, que puede ser largo.
¿Qué sucede?
¿Qué es un “puntero”?
Un puntero suele ser una cadena única o encabezado presente en el documento (por ejemplo, un H2 o una frase o título de sección específico).
Ejemplo de caso de uso:
Quieres omitir las secciones introductorias y recuperar información para una sección relevante específica de un artículo o documento largo (ejemplo: desde “Paso 4: Agrega un botón de chat en vivo” en una guía de configuración).
La opción Omitir último encabezado es útil para ignorar el último encabezado del documento, que a menudo se repite o se usa para navegación o propósitos de pie de página.
¿Qué sucede?
Ejemplo de caso de uso:
Quieres evitar que el Document Retriever cargue un encabezado de navegación de pie de página (como “Otros artículos” al final de una página de ayuda), asegurando que solo se procese el contenido principal.
Nota:
Omitir último encabezado puede ayudar con documentos que generan automáticamente pies de página o elementos de navegación repetitivos. Sin embargo, si no tienes tales secciones, usar este parámetro podría hacer que una parte válida del artículo no sea recuperada. Por lo tanto, se recomienda dejar esta opción desactivada hasta que tengas una razón válida para activarla.
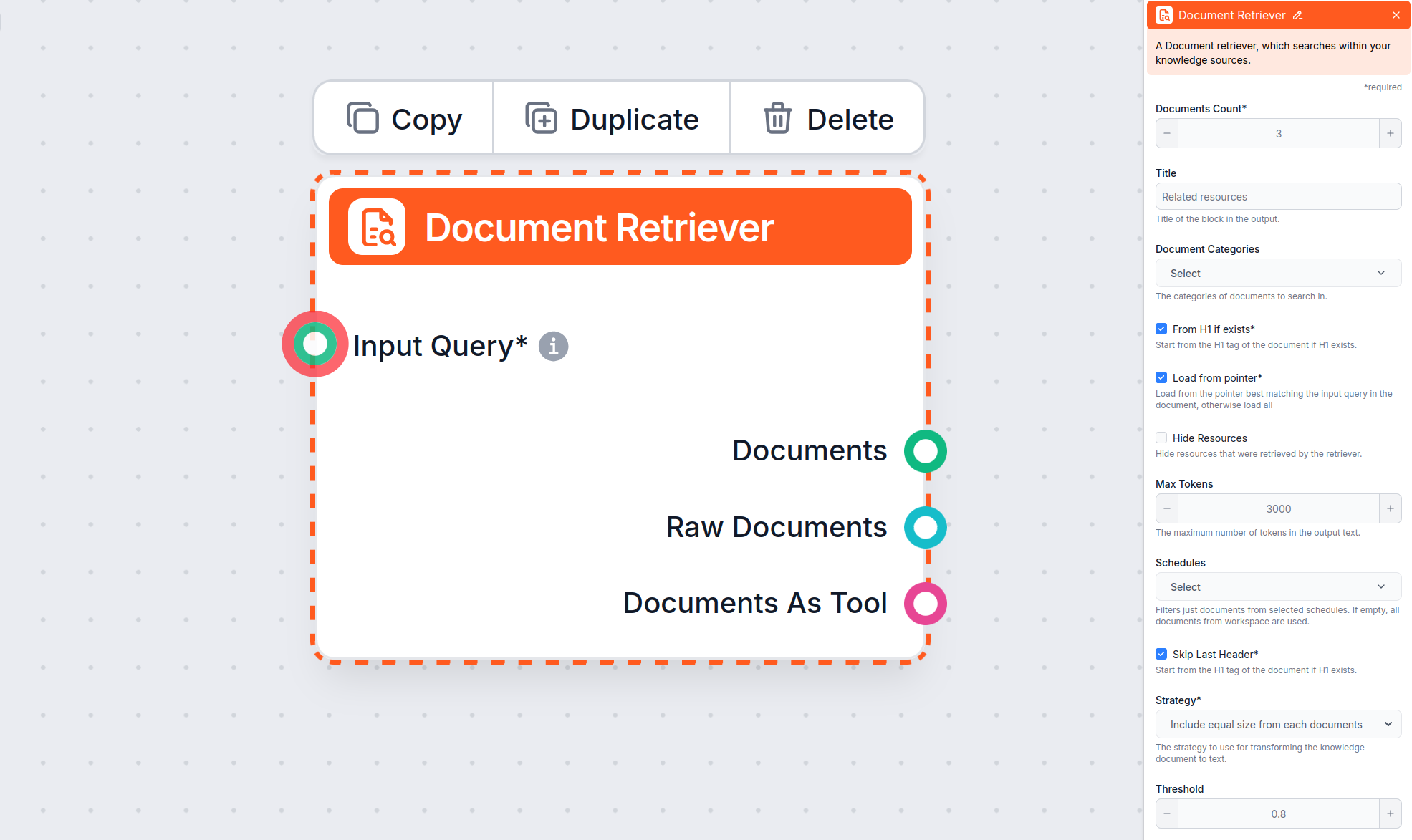
El parámetro Máximo de tokens te permite controlar el número máximo de tokens (palabras y signos de puntuación, según lo cuenta el modelo de IA subyacente) que el Document Retriever mostrará del texto extraído.
¿Qué sucede?
Valor predeterminado:
El valor predeterminado suele ser de 3000 tokens, pero puedes ajustarlo si lo necesitas.
Ejemplo de caso de uso:
Si estás procesando documentos extensos, establecer un valor de Máximo de tokens más bajo ayuda a mantener las respuestas concisas. Sin embargo, para mejores resultados, considera activar el parámetro “Cargar desde puntero”. Esto asegura que el texto extraído comience en la sección más relevante del documento, en vez de desde el inicio, permitiéndote obtener un fragmento de información enfocado y manejable dentro de tu límite de tokens. Esta combinación es especialmente útil cuando quieres salidas concisas y contextualmente relevantes de fuentes grandes.
Nota:
Si ves que se corta información, prueba aumentando el valor de Máximo de tokens. Por el contrario, si quieres salidas más breves y enfocadas, reduce el parámetro de Máximo de tokens.
Cuando el Document Retriever encuentra varios documentos relevantes, el parámetro Estrategia determina cómo se fusionan en una sola salida de texto para tu chatbot, teniendo en cuenta el límite de “Máximo de tokens”.
Dos opciones de estrategia:
Incluir igual tamaño de cada documento:
El límite de tokens se divide de manera equitativa. Por ejemplo, con tres documentos y un límite de 3,000 tokens, cada uno recibe hasta 1,000 tokens. Esto asegura que todas las fuentes contribuyan por igual, lo cual es útil cuando quieres una respuesta equilibrada extraída de varios documentos.
Concatenar documentos, llenar desde el primero hasta el límite de tokens:
Los documentos se agregan según su relevancia hasta alcanzar el límite de tokens. El documento más relevante ocupa el espacio primero; si queda espacio, se agregan documentos menos relevantes en orden. Si el primer documento es largo, puede usar todo el límite por sí solo.
¿Cómo elegir?
Nota:
Estas estrategias solo afectan cómo se construye el texto a partir de los documentos recuperados antes de pasarlo al siguiente paso (como la generación por IA). No cambian qué documentos se recuperan, solo cómo se fusiona y recorta su contenido para ajustarse al ajuste de Máximo de tokens.
Aunque este artículo se centra en la configuración de los parámetros ‘Desde H1 si existe’, ‘Cargar desde puntero’, ‘Omitir último encabezado’ y ‘Máximo de tokens’, el Document Retriever también ofrece parámetros adicionales que ayudan a controlar cómo se seleccionan y recuperan los documentos:
Este ajuste limita la cantidad de documentos que el flujo debe recuperar, asegurando que los resultados sigan siendo relevantes y que las respuestas se generen rápidamente.
Este ajuste opcional te permite limitar la recuperación a una o más categorías que hayas creado en la sección Documentos de Fuentes de Conocimiento.
Esto te permite incluir u ocultar una sección separada, antes de la respuesta real del chatbot, con una lista de recursos que el recuperador obtuvo. Para la integración con LiveAgent, debe estar activado, ya que esta sección no es compatible y no se mostrará correctamente en el widget del chatbot de LiveAgent.
Te permite restringir la recuperación a una o más Programaciones que hayas especificado para rastrear o actualizar contenido en Fuentes de Conocimiento.
Controla cuán estrechamente deben coincidir los documentos recuperados con la consulta de entrada, usando una puntuación de relevancia (de 0 a 1). Por ejemplo, se recomienda un umbral de 0.7–0.8 para respuestas muy relevantes. Umbrales más altos dan coincidencias más precisas, mientras que los más bajos pueden incluir documentos menos relevantes.
Ejemplo:
Si estableces un umbral de 0.6 y tienes cuatro artículos con puntuaciones de relevancia de 0.8, 0.65, 0.5 y 0.9, solo los que estén por encima de 0.6 (es decir, 0.8, 0.65 y 0.9) se usarán para la extracción.
Si la respuesta proporcionada por el chatbot no contiene información que estás seguro de que tiene disponible en tus documentos o programaciones, prueba revisar el historial de la conversación con la opción “Verbose” para ver registros detallados de si se utilizó el Document Retriever y qué documentos se recuperaron. Si es necesario, ajusta tus configuraciones y el prompt en base a estos registros.
Tu chatbot puede acceder y utilizar al instante documentos, páginas HTML e incluso videos de YouTube para adaptar tu contexto único. Perfecto para agregar infor...
El Recuperador de Documentos de FlowHunt mejora la precisión de la IA al conectar modelos generativos con tus propios documentos y URLs actualizados, garantizan...
Integra tus flujos de trabajo con Google Docs usando el componente Recuperador de Google Docs: obtén el contenido de los documentos de forma automática para usa...