Pipeline de récupération
Un pipeline de récupération permet aux chatbots de récupérer et de traiter des connaissances externes pertinentes pour fournir des réponses précises, en temps réel et contextualisées grâce à RAG, aux embeddings et aux bases de données vectorielles.
Qu’est-ce qu’un pipeline de récupération pour les chatbots ?
Un pipeline de récupération pour les chatbots désigne l’architecture technique et le processus qui permettent aux chatbots de récupérer, traiter et extraire des informations pertinentes en réponse aux requêtes des utilisateurs. Contrairement aux systèmes de questions-réponses simples qui s’appuient uniquement sur des modèles de langage pré-entraînés, les pipelines de récupération intègrent des bases de connaissances ou des sources de données externes. Cela permet au chatbot de fournir des réponses précises, contextuelles et actualisées, même lorsque les données ne sont pas intrinsèquement présentes dans le modèle de langage.
Le pipeline de récupération se compose généralement de plusieurs composants, dont l’ingestion de données, la création d’embeddings, le stockage vectoriel, la récupération de contexte et la génération de réponses. Son implémentation repose souvent sur la génération augmentée par la récupération (RAG), qui combine les forces des systèmes de récupération de données et des grands modèles de langage (LLM) pour la génération des réponses.
Comment le pipeline de récupération est-il utilisé dans les chatbots ?
Un pipeline de récupération est utilisé pour améliorer les capacités d’un chatbot en lui permettant de :
- Accéder à des connaissances spécifiques à un domaine
Il peut interroger des bases de données, documents ou API externes pour récupérer des informations précises et pertinentes par rapport à la requête utilisateur. - Générer des réponses contextualisées
En augmentant les données récupérées par la génération de langage naturel, le chatbot produit des réponses cohérentes et adaptées. - Garantir des informations à jour
Contrairement aux modèles de langage statiques, le pipeline permet la récupération en temps réel d’informations provenant de sources dynamiques.
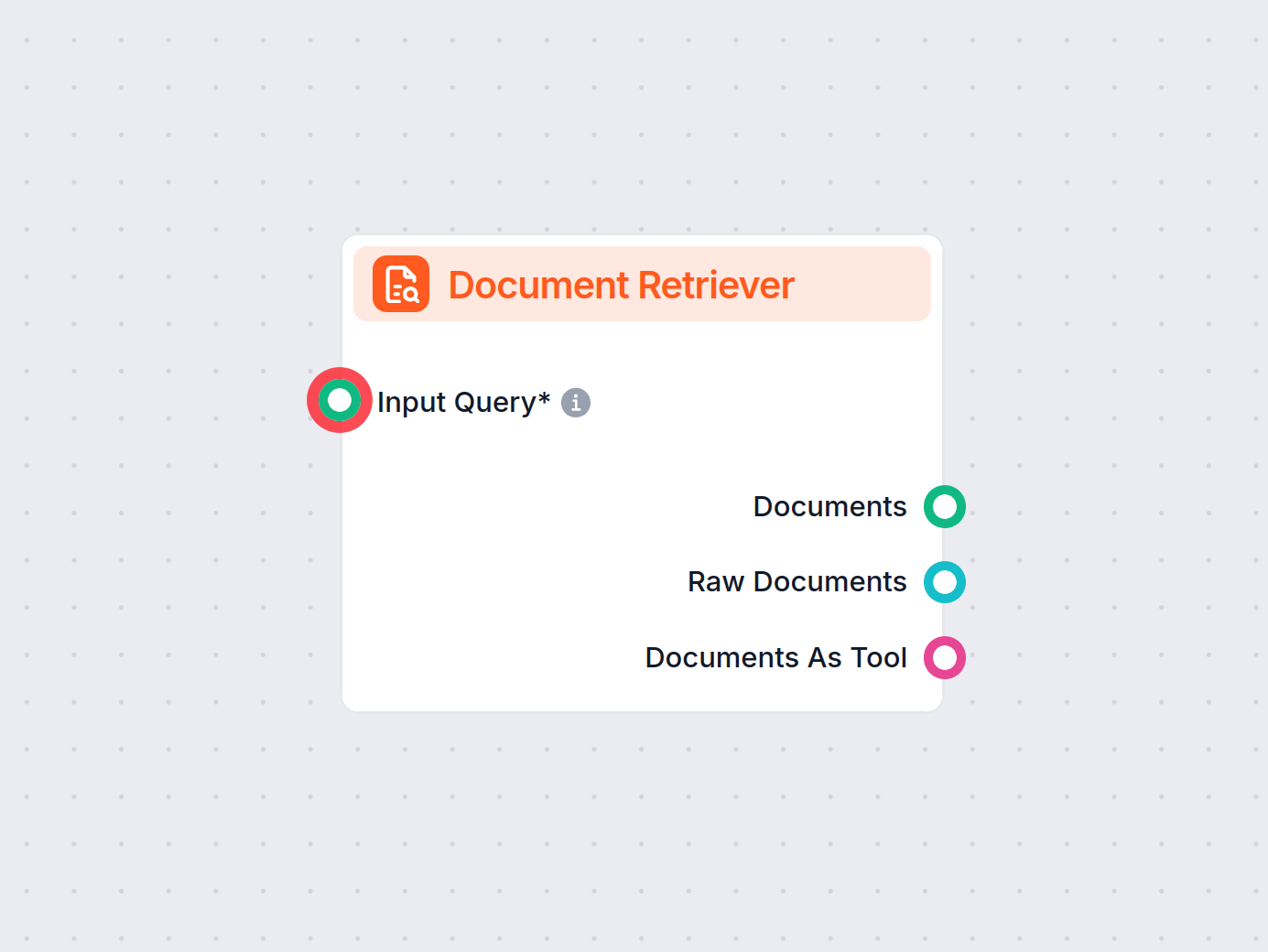
Composants clés d’un pipeline de récupération
Ingestion de documents
Collecte et prétraitement des données brutes, pouvant inclure des PDF, fichiers texte, bases de données ou API. Des outils comme LangChain ou LlamaIndex sont souvent utilisés pour une ingestion fluide des données.
Exemple : chargement des FAQ du service client ou des spécifications produit dans le système.Prétraitement des documents
Les documents longs sont découpés en fragments plus petits et sémantiquement cohérents. Ceci est essentiel pour respecter les limites de tokens des modèles d’embedding (par exemple, 512 tokens).Exemple de code :
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) chunks = text_splitter.split_documents(document_list)Génération d’embeddings
Les données textuelles sont converties en représentations vectorielles de grande dimension à l’aide de modèles d’embedding. Ces embeddings encodent numériquement la signification sémantique des données. Exemple de modèle d’embedding :text-embedding-ada-002d’OpenAI oue5-large-v2de Hugging Face.Stockage vectoriel
Les embeddings sont stockés dans des bases de données vectorielles optimisées pour la recherche de similarité. Des outils comme Milvus, Chroma ou PGVector sont couramment employés. Exemple : stockage des descriptions produits et de leurs embeddings pour une récupération efficace.Traitement des requêtes
Lorsqu’une requête utilisateur est reçue, elle est transformée en vecteur de requête via le même modèle d’embedding. Cela permet l’appariement sémantique avec les embeddings stockés.Exemple de code :
query_vector = embedding_model.encode("Quelles sont les spécifications du Produit X ?") retrieved_docs = vector_db.similarity_search(query_vector, k=5)Récupération des données
Le système récupère les fragments de données les plus pertinents selon les scores de similarité (ex. similarité cosinus). Les systèmes de récupération multi-modaux peuvent combiner bases SQL, graphes de connaissances et recherches vectorielles pour des résultats plus robustes.Génération de réponse
Les données récupérées sont combinées avec la question de l’utilisateur et transmises à un grand modèle de langage (LLM) pour générer une réponse finale en langage naturel. Cette étape est souvent appelée génération augmentée.Exemple de template de prompt :
prompt_template = """ Contexte : {context} Question : {question} Veuillez fournir une réponse détaillée en utilisant le contexte ci-dessus. """Post-traitement et validation
Les pipelines avancés incluent la détection d’hallucinations, la vérification de la pertinence ou le grading des réponses pour garantir la factualité et la pertinence de la sortie.
Cas d’utilisation des pipelines de récupération dans les chatbots
Service client
Les chatbots peuvent extraire des manuels produits, guides de résolution ou FAQ pour fournir des réponses instantanées aux clients.
Exemple : un chatbot aide un client à réinitialiser un routeur en récupérant la section appropriée du manuel.Gestion des connaissances en entreprise
Les chatbots internes accèdent à des données spécifiques à l’entreprise telles que politiques RH, documentation SI ou consignes de conformité.
Exemple : des employés interrogeant un chatbot interne sur la politique de congés maladie.E-commerce
Les chatbots assistent les utilisateurs en récupérant des détails produit, avis ou disponibilités en stock.
Exemple : « Quels sont les principaux atouts du Produit Y ? »Santé
Les chatbots extraient de la littérature médicale, des recommandations ou des données patient pour aider professionnels ou patients.
Exemple : un chatbot récupère les contre-indications d’un médicament dans une base pharmaceutique.Éducation et recherche
Les chatbots académiques utilisent des pipelines RAG pour récupérer des articles scientifiques, répondre à des questions ou résumer des résultats.
Exemple : « Peux-tu résumer les conclusions de cette étude de 2023 sur le changement climatique ? »Légal et conformité
Les chatbots récupèrent des documents juridiques, jurisprudences ou exigences réglementaires pour assister les professionnels du droit.
Exemple : « Quelle est la dernière mise à jour sur la réglementation RGPD ? »
Exemples d’implémentations de pipelines de récupération
Exemple 1 : Q&R basée sur PDF
Un chatbot conçu pour répondre aux questions à partir du rapport financier annuel d’une entreprise au format PDF.
Exemple 2 : Récupération hybride
Un chatbot combinant SQL, recherche vectorielle et graphes de connaissances pour répondre à la question d’un employé.
Bénéfices de l’utilisation d’un pipeline de récupération
- Précision
Réduit les hallucinations en ancrant les réponses sur des données factuelles récupérées. - Pertinence contextuelle
Adapte les réponses selon des données spécifiques au domaine. - Mises à jour en temps réel
Maintient la base de connaissances du chatbot à jour grâce à des sources dynamiques. - Efficacité économique
Réduit la nécessité d’affinage coûteux des LLM en augmentant avec des données externes. - Transparence
Fournit des sources traçables et vérifiables pour les réponses du chatbot.
Défis et points d’attention
- Latence
La récupération en temps réel peut introduire des délais, surtout avec des pipelines à plusieurs étapes. - Coût
L’augmentation des appels API vers les LLM ou les bases vectorielles peut entraîner des coûts opérationnels plus élevés. - Confidentialité des données
Les données sensibles doivent être traitées de manière sécurisée, notamment dans les systèmes RAG auto-hébergés. - Scalabilité
Les pipelines à grande échelle nécessitent une conception efficace pour éviter les goulets d’étranglement lors de la récupération ou du stockage des données.
Tendances futures
- Pipelines RAG agentiques
Agents autonomes effectuant des raisonnements et récupérations multi-étapes. - Modèles d’embedding fine-tunés
Embeddings spécifiques à un domaine pour une recherche sémantique améliorée. - Intégration de données multimodales
Extension de la récupération aux images, à l’audio et à la vidéo en plus du texte.
En s’appuyant sur des pipelines de récupération, les chatbots ne sont plus limités par les contraintes de données statiques d’entraînement, ce qui leur permet d’offrir des interactions dynamiques, précises et riches en contexte.
Recherche sur les pipelines de récupération pour les chatbots
Les pipelines de récupération jouent un rôle clé dans les systèmes de chatbots modernes, permettant des interactions intelligentes et contextualisées.
« Lingke : A Fine-grained Multi-turn Chatbot for Customer Service » par Pengfei Zhu et al. (2018)
Présente Lingke, un chatbot intégrant la récupération d’information pour gérer des conversations multi-tours. Il s’appuie sur un traitement par pipeline finement découpé pour extraire des réponses à partir de documents non structurés et utilise une correspondance attentive contexte-réponse pour des interactions séquentielles, améliorant significativement la capacité du chatbot à traiter des requêtes complexes.
Lire l’article ici.« FACTS About Building Retrieval Augmented Generation-based Chatbots » par Rama Akkiraju et al. (2024)
Explore les défis et méthodologies pour développer des chatbots d’entreprise avec des pipelines RAG et des LLM. Les auteurs proposent le cadre FACTS, mettant l’accent sur la Fraîcheur, l’Architecture, le Coût, les Tests et la Sécurité dans l’ingénierie des pipelines RAG. Leurs résultats empiriques mettent en avant les compromis entre précision et latence lors de la montée en charge des LLM, offrant des perspectives précieuses pour concevoir des chatbots sécurisés et performants. Lire l’article ici.« From Questions to Insightful Answers: Building an Informed Chatbot for University Resources » par Subash Neupane et al. (2024)
Présente BARKPLUG V.2, un système de chatbot dédié à l’environnement universitaire. Utilisant des pipelines RAG, le système fournit des réponses précises et adaptées au domaine sur les ressources du campus, améliorant l’accès à l’information. L’étude évalue l’efficacité du chatbot au moyen de cadres comme RAG Assessment (RAGAS) et met en avant son utilité dans les milieux académiques. Lire l’article ici.
Questions fréquemment posées
- Qu'est-ce qu'un pipeline de récupération dans les chatbots ?
Un pipeline de récupération est une architecture technique permettant aux chatbots de récupérer, traiter et extraire des informations pertinentes à partir de sources externes en réponse aux requêtes des utilisateurs. Il combine l'ingestion de données, l'embedding, le stockage vectoriel et la génération de réponses par LLM pour des réponses dynamiques et contextualisées.
- Comment la génération augmentée par la récupération (RAG) améliore-t-elle les réponses des chatbots ?
La RAG combine les forces des systèmes de récupération de données et des grands modèles de langage (LLM), permettant aux chatbots d'ancrer leurs réponses sur des données factuelles et à jour, réduisant ainsi les hallucinations et augmentant la précision.
- Quels sont les composants typiques d'un pipeline de récupération ?
Les composants clés incluent l'ingestion de documents, le prétraitement, la génération d'embeddings, le stockage vectoriel, le traitement des requêtes, la récupération des données, la génération des réponses et la validation post-traitement.
- Quels sont les cas d'utilisation courants des pipelines de récupération dans les chatbots ?
Les cas d'utilisation incluent l'assistance client, la gestion de la connaissance en entreprise, les informations produit en e-commerce, l'accompagnement en santé, l'éducation et la recherche, ainsi que l'aide à la conformité légale.
- Quels défis dois-je considérer lors de la création d'un pipeline de récupération ?
Les défis incluent la latence due à la récupération en temps réel, les coûts opérationnels, les préoccupations liées à la confidentialité des données et les exigences de scalabilité pour gérer de grands volumes de données.
Commencez à créer des chatbots alimentés par l'IA avec des pipelines de récupération
Libérez la puissance de la génération augmentée par la récupération (RAG) et de l'intégration de données externes pour fournir des réponses intelligentes et précises via chatbot. Essayez la plateforme sans code de FlowHunt dès aujourd'hui.
En savoir plus