
Récupérateur de Documents
Le Récupérateur de Documents de FlowHunt améliore la précision de l’IA en connectant les modèles génératifs à vos propres documents et URL à jour, garantissant ...
4 min de lecture
AI
Document Retrieval
+3
Découvrez comment configurer les paramètres «xa0Depuis H1 si existexa0», «xa0Charger depuis le pointeurxa0» et «xa0Ignorer le dernier en-têtexa0».
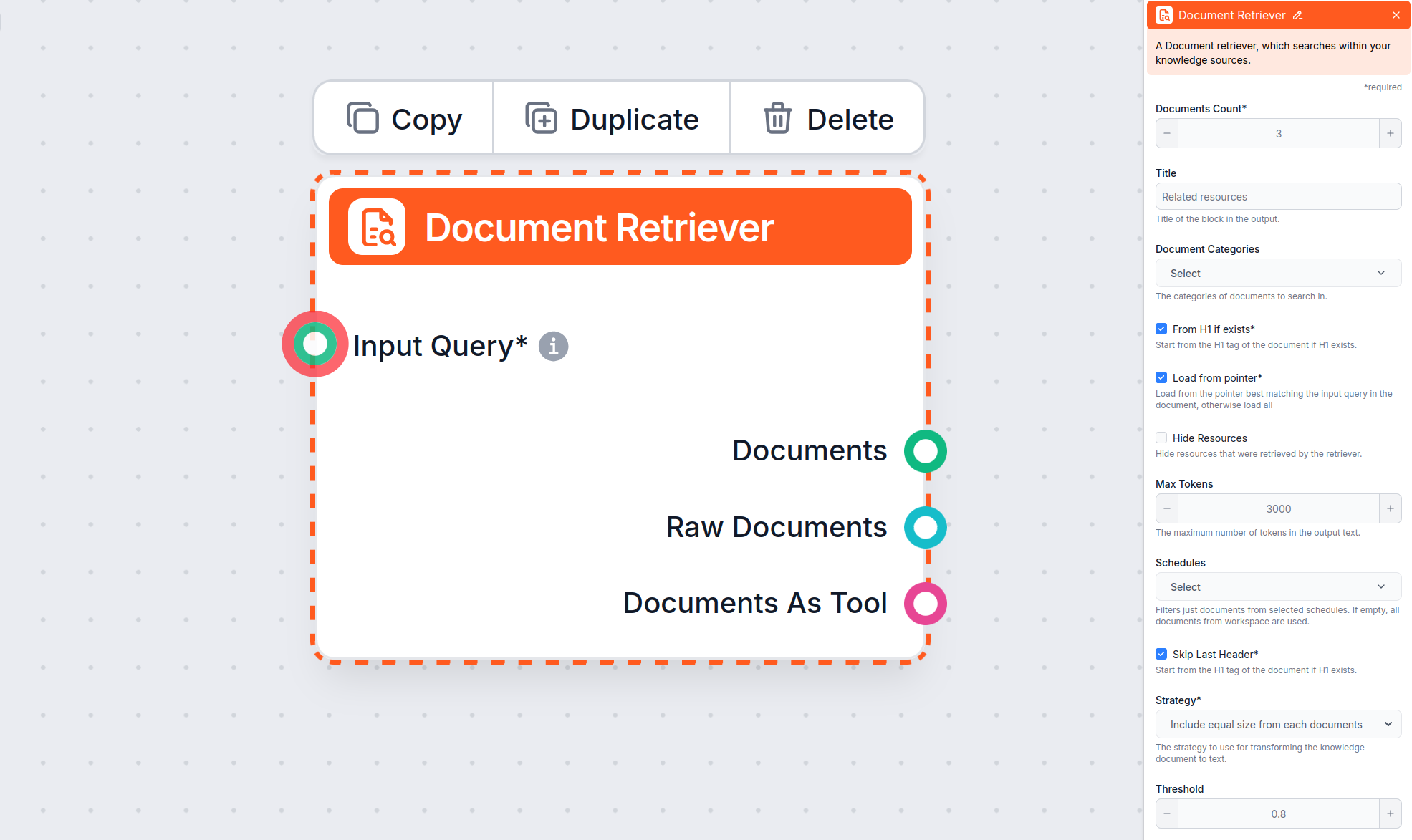
Le composant Document Retriever permet au chatbot d’accéder aux connaissances issues des sources que vous avez spécifiées dans les Documents et les Plannings. Le rôle de ce composant est de contrôler la récupération, et plusieurs paramètres influencent la manière dont il extrait les informations de ces documents.
L’option Depuis H1 si existe indique au retriever de commencer à extraire le contenu à partir du premier en-tête H1 trouvé (généralement le titre principal de l’article).
Que se passe-t-il ?
Exemple d’utilisation :
Vous souhaitez ne récupérer que le guide réel, sans la navigation du site ou l’en-tête de page qui alourdit votre site web.
Remarque :
Depuis H1 si existe est activé par défaut dans le composant Document Retriever.
L’option Charger depuis le pointeur vous offre une plus grande précision en permettant au Document Retriever de ne charger que les données à partir d’un pointeur dans un article potentiellement long.
Que se passe-t-il ?
Qu’est-ce qu’un « pointeur » ?
Un pointeur est généralement une chaîne unique ou un en-tête présent dans le document (par exemple, un H2, une phrase ou un titre de section spécifique).
Exemple d’utilisation :
Vous souhaitez ignorer les sections d’introduction et ne récupérer que l’information d’une section spécifique dans un article ou document long (par exemple, à partir de « Étape 4 : Ajouter un bouton de chat en direct » dans un guide d’installation).
L’option Ignorer le dernier en-tête est utile pour ne pas prendre en compte le dernier en-tête du document, souvent répété ou réservé à la navigation ou au pied de page.
Que se passe-t-il ?
Exemple d’utilisation :
Vous souhaitez éviter que le Document Retriever ne charge un en-tête de navigation de pied de page (tel que « Autres articles » en fin de page d’aide), afin que seul le contenu principal soit traité.
Remarque :
Ignorer le dernier en-tête peut être utile pour les documents qui génèrent automatiquement des pieds de page ou des éléments de navigation répétitifs. Toutefois, si vous n’avez pas ce type de sections, activer ce paramètre pourrait empêcher la récupération d’une partie valide de l’article. Il est donc conseillé de laisser cette option désactivée sauf cas de besoin avéré.
Le paramètre Nombre maximal de jetons vous permet de contrôler le nombre maximal de jetons (mots et signes de ponctuation, selon le modèle d’IA sous-jacent) que le Document Retriever extraira du texte récupéré.
Que se passe-t-il ?
Valeur par défaut :
La valeur par défaut est généralement de 3000 jetons, mais vous pouvez l’ajuster selon vos besoins.
Exemple d’utilisation :
Si vous traitez de longs documents, fixer une valeur plus basse pour le nombre maximal de jetons aide à garder des réponses concises. Cependant, pour de meilleurs résultats, activez le paramètre « Charger depuis le pointeur ». Cela garantit que le texte extrait commence à la section la plus pertinente du document, plutôt qu’au tout début, ce qui vous permet d’obtenir un extrait ciblé et gérable dans la limite de jetons spécifiée. Cette combinaison est particulièrement utile si vous souhaitez des sorties succinctes et contextualisées à partir de grandes sources.
Remarque :
Si vous constatez que des informations sont coupées, essayez d’augmenter la valeur du nombre maximal de jetons. À l’inverse, si vous souhaitez des réponses plus courtes et ciblées, réduisez ce paramètre.
Lorsque le Document Retriever trouve plusieurs documents pertinents, le paramètre Stratégie détermine la manière dont ils sont fusionnés en une seule sortie textuelle pour votre chatbot, tout en respectant la limite du nombre maximal de jetons.
Deux options de stratégie :
Inclure une taille égale de chaque document :
La limite de jetons est répartie équitablement. Par exemple, avec trois documents et une limite de 3 000 jetons, chaque document peut utiliser jusqu’à 1 000 jetons. Cela garantit que toutes les sources contribuent de façon équitable, ce qui est utile pour obtenir une réponse équilibrée basée sur plusieurs documents.
Concaténer les documents, remplir depuis le premier jusqu’à la limite de jetons :
Les documents sont ajoutés selon leur pertinence jusqu’à atteindre la limite de jetons. Le document le plus pertinent occupe l’espace en priorité ; s’il reste de la place, les moins pertinents sont ajoutés à leur tour. Si le premier document est long, il peut consommer toute la limite à lui seul.
Comment choisir ?
Remarque :
Ces stratégies n’agissent que sur la manière dont le texte est construit à partir des documents récupérés avant d’être transmis à l’étape suivante (génération IA, par exemple). Elles ne changent pas les documents sélectionnés, seulement la façon dont leur contenu est fusionné et tronqué pour respecter la limite de jetons.
Bien que cet article se concentre sur la configuration des paramètres « Depuis H1 si existe », « Charger depuis le pointeur », « Ignorer le dernier en-tête » et « Nombre maximal de jetons », le Document Retriever propose aussi d’autres paramètres pour contrôler la sélection et la récupération des documents :
Ce paramètre limite le nombre de documents que le flux doit récupérer, afin que les résultats restent pertinents et que les réponses soient générées rapidement.
Ce paramètre optionnel permet de limiter la récupération à une ou plusieurs catégories que vous avez créées dans la section Documents des Sources de connaissances.
Cela vous permet d’inclure ou non une section séparée, avant la réponse du chatbot, avec une liste des ressources récupérées par le retriever. Pour l’intégration avec LiveAgent, cette option doit être cochée, car cette section n’est pas prise en charge et ne s’affichera pas correctement dans le widget chatbot LiveAgent.
Permet de restreindre la récupération à un ou plusieurs plannings que vous avez spécifiés pour le crawl ou la mise à jour du contenu dans les Sources de connaissances.
Contrôle la correspondance requise entre les documents récupérés et la requête, grâce à un score de pertinence (de 0 à 1). Par exemple, un seuil de 0,7–0,8 est recommandé pour des réponses très pertinentes. Un seuil élevé donne des correspondances précises, tandis qu’un seuil plus bas peut inclure des documents moins pertinents.
Exemple :
Si vous fixez un seuil à 0,6 et que vous avez quatre articles avec des scores de pertinence de 0,8, 0,65, 0,5 et 0,9, seuls ceux au-dessus de 0,6 (soit 0,8, 0,65 et 0,9) seront utilisés pour l’extraction.
Si la réponse fournie par le chatbot ne contient pas une information que vous êtes certain qu’il possède dans vos documents ou plannings, vérifiez l’historique de conversation avec l’option « Verbeux » pour voir les journaux détaillés indiquant si le Document Retriever a été utilisé et quels documents ont été récupérés. Si besoin, ajustez vos réglages et votre prompt en fonction de ces logs.
Le Récupérateur de Documents de FlowHunt améliore la précision de l’IA en connectant les modèles génératifs à vos propres documents et URL à jour, garantissant ...
Intégrez vos flux de travail avec Google Docs grâce au composant Récupérateur Google Docs—récupérez sans effort le contenu de vos documents pour l'utiliser dans...
Votre chatbot peut instantanément accéder à des documents, des pages HTML et même des vidéos YouTube pour adapter votre contexte unique. Idéal pour ajouter des ...