
Wan 2.1: La rivoluzione open-source nella generazione video AI
Wan 2.1 è un potente modello open-source di generazione video AI di Alibaba, che crea video di qualità da studio da testo o immagini, gratuitamente e utilizzabile da tutti localmente.

Che cos’è Wan 2.1?
Wan 2.1 (conosciuto anche come WanX 2.1) sta aprendo nuove strade come modello AI di generazione video completamente open-source sviluppato dal Tongyi Lab di Alibaba. Diversamente da molti sistemi proprietari che richiedono abbonamenti costosi o accesso tramite API, Wan 2.1 offre una qualità comparabile o superiore restando completamente gratuito e accessibile a sviluppatori, ricercatori e professionisti creativi.
Ciò che rende Wan 2.1 davvero speciale è la combinazione di accessibilità e prestazioni. La variante più piccola T2V-1.3B richiede solo ~8.2 GB di memoria GPU, rendendolo compatibile con la maggior parte delle GPU consumer moderne. Nel frattempo, la versione più grande da 14 miliardi di parametri offre prestazioni all’avanguardia che superano sia le alternative open-source sia molti modelli commerciali nei benchmark standard.
Caratteristiche chiave che distinguono Wan 2.1
Supporto multi-task
Wan 2.1 non si limita solo alla generazione text-to-video. La sua architettura versatile supporta:
- Text-to-video (T2V)
- Image-to-video (I2V)
- Video-to-video editing
- Generazione text-to-image
- Generazione video-to-audio
Questa flessibilità ti consente di partire da un prompt testuale, un’immagine statica o persino un video esistente e trasformarlo secondo la tua visione creativa.
Generazione di testo multilingue
Come primo modello video in grado di rendere testo leggibile in inglese e cinese all’interno dei video generati, Wan 2.1 apre nuove possibilità per i creatori di contenuti internazionali. Questa funzione è particolarmente preziosa per creare sottotitoli o testo di scena in video multilingue.
Video VAE rivoluzionario (Wan-VAE)
Al centro dell’efficienza di Wan 2.1 c’è il suo Video Variational Autoencoder causale 3D. Questa innovazione tecnologica comprime in modo efficiente le informazioni spaziotemporali, permettendo al modello di:
- Comprimere i video di centinaia di volte in termini di dimensione
- Preservare la fedeltà nel movimento e nei dettagli
- Supportare output ad alta risoluzione fino a 1080p
Efficienza e accessibilità eccezionali
Il modello più piccolo da 1.3B richiede solo 8.19 GB di VRAM e può produrre un video di 5 secondi a 480p in circa 4 minuti su una RTX 4090. Nonostante questa efficienza, la sua qualità rivaleggia o supera quella di modelli molto più grandi, rappresentando il perfetto equilibrio tra velocità e fedeltà visiva.
Benchmark e qualità leader nel settore
Nelle valutazioni pubbliche, Wan 14B ha ottenuto il punteggio complessivo più alto nei test Wan-Bench, superando i concorrenti in:
- Qualità del movimento
- Stabilità
- Precisione nell’aderenza ai prompt
Come si confronta Wan 2.1 con altri modelli di generazione video
A differenza dei sistemi closed-source come Sora di OpenAI o Gen-2 di Runway, Wan 2.1 è liberamente disponibile ed eseguibile localmente. In generale supera i precedenti modelli open-source (come CogVideo, MAKE-A-VIDEO e Pika) e persino molte soluzioni commerciali nei benchmark di qualità.
Un recente sondaggio di settore ha osservato che “tra i molti modelli video AI, Wan 2.1 e Sora si distinguono” – Wan 2.1 per la sua apertura ed efficienza, Sora per la sua innovazione proprietaria. Nei test della community, gli utenti hanno riportato che la capacità image-to-video di Wan 2.1 supera i concorrenti in chiarezza e resa cinematografica.
La tecnologia dietro Wan 2.1
Wan 2.1 si basa su una backbone diffusion-transformer con una nuova VAE spaziotemporale. Ecco come funziona:
- Un input (testo e/o immagine/video) viene codificato in una rappresentazione latente video dal Wan-VAE
- Un diffusion transformer (basato sull’architettura DiT) denoisa iterativamente questa latenza
- Il processo è guidato dall’encoder testuale (una variante multilingue di T5 chiamata umT5)
- Infine, il decoder Wan-VAE ricostruisce i frame video di output
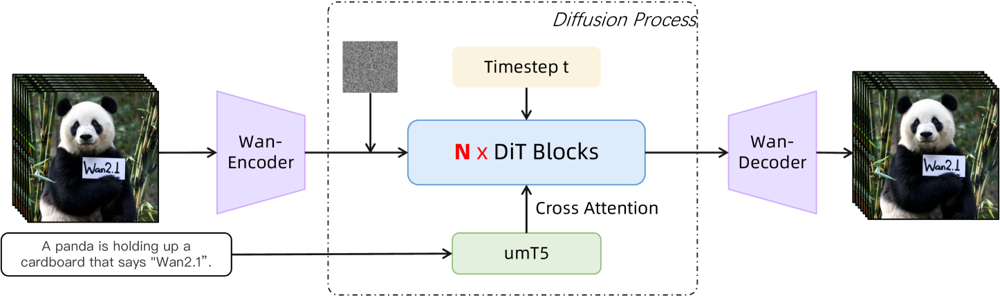
Figura: Architettura ad alto livello di Wan 2.1 (caso text-to-video). Un video (o immagine) viene prima codificato dall’encoder Wan-VAE in una latenza. Questa latenza viene quindi passata attraverso N blocchi diffusion transformer, che si collegano all’embedding testuale (da umT5) tramite cross-attention. Infine, il decoder Wan-VAE ricostruisce i frame video. Questo design – caratterizzato da un “encoder/decoder VAE causale 3D che circonda un diffusion transformer” (ar5iv.org) – permette una compressione efficiente dei dati spaziotemporali e supporta output video di alta qualità.
Questa architettura innovativa—caratterizzata da un “encoder/decoder VAE causale 3D che circonda un diffusion transformer”—permette una compressione efficiente dei dati spaziotemporali e supporta output video di alta qualità.
Il Wan-VAE è progettato appositamente per i video. Comprimo l’input per fattori impressionanti (4× temporale e 8× spaziale) in una latenza compatta prima di ricostruirlo in video completo. L’uso di convoluzioni 3D e livelli causali (che preservano il tempo) garantisce una coerenza nei movimenti lungo tutto il contenuto generato.
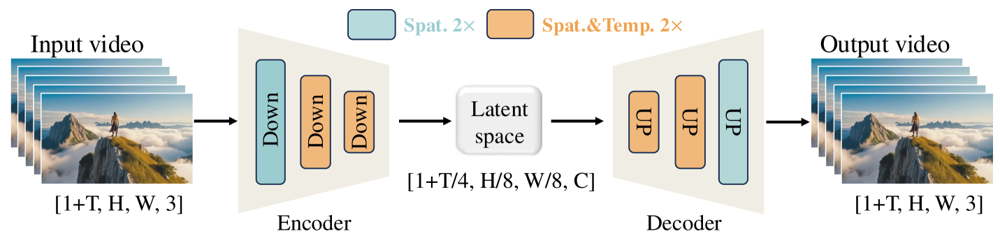
Figura: Framework Wan-VAE di Wan 2.1 (encoder-decoder). L’encoder Wan-VAE (a sinistra) applica una serie di layer di down-sampling (“Down”) al video di input (forma [1+T, H, W, 3] frame) fino ad arrivare a una latenza compatta ([1+T/4, H/8, W/8, C]). Il decoder Wan-VAE (a destra) esegue simmetricamente l’upsampling (“UP”) di questa latenza riportandola ai frame video originali. I blocchi blu indicano compressione spaziale, quelli arancioni compressione combinata spaziale+temporale (ar5iv.org). Comprimendo il video di 256× (nel volume spaziotemporale), Wan-VAE rende praticabile la modellazione video ad alta risoluzione per il successivo modello di diffusione.
Come eseguire Wan 2.1 sul tuo computer
Pronto a provare Wan 2.1? Ecco come iniziare:
Requisiti di sistema
- Python 3.8+
- PyTorch ≥2.4.0 con supporto CUDA
- GPU NVIDIA (8GB+ VRAM per il modello 1.3B, 16-24GB per i modelli 14B)
- Librerie aggiuntive dal repository
Passaggi di installazione
Clona il repository e installa le dipendenze:
git clone https://github.com/Wan-Video/Wan2.1.git cd Wan2.1 pip install -r requirements.txtScarica i pesi del modello:
pip install "huggingface_hub[cli]" huggingface-cli login huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./Wan2.1-T2V-14BGenera il tuo primo video:
python generate.py --task t2v-14B --size 1280*720 \ --ckpt_dir ./Wan2.1-T2V-14B \ --prompt "A futuristic city skyline at sunset, with flying cars zooming overhead."
Consigli per le prestazioni
- Per macchine con memoria GPU limitata, prova il modello t2v-1.3B più leggero
- Usa le opzioni
--offload_model True --t5_cpuper spostare parti del modello sulla CPU - Controlla il rapporto d’aspetto con il parametro
--size(es. 832*480 per 16:9 480p) - Wan 2.1 offre estensione dei prompt e “modalità ispirazione” tramite opzioni aggiuntive
Per riferimento, una RTX 4090 può generare un video di 5 secondi a 480p in circa 4 minuti. Configurazioni multi-GPU e varie ottimizzazioni (FSDP, quantizzazione, ecc.) sono supportate per utilizzi su larga scala.
Perché Wan 2.1 è importante per il futuro dei video AI
Come potenza open-source che sfida i giganti nella generazione video AI, Wan 2.1 rappresenta un cambiamento significativo in termini di accessibilità. La sua natura libera e aperta significa che chiunque disponga di una GPU decente può esplorare la generazione video all’avanguardia senza costi di abbonamento o API.
Per gli sviluppatori, la licenza open-source consente di personalizzare e migliorare il modello. I ricercatori possono estenderne le capacità, mentre i professionisti creativi possono prototipare rapidamente ed efficientemente contenuti video.
In un’epoca in cui i modelli AI proprietari sono sempre più bloccati dietro paywall, Wan 2.1 dimostra che le prestazioni all’avanguardia possono essere democratizzate e condivise con la comunità più ampia.
Domande frequenti
- Che cos'è Wan 2.1?
Wan 2.1 è un modello AI completamente open-source per la generazione video sviluppato dal Tongyi Lab di Alibaba, capace di creare video di alta qualità da prompt testuali, immagini o video esistenti. È gratuito, supporta più compiti e funziona in modo efficiente su GPU consumer.
- Quali caratteristiche rendono Wan 2.1 unico?
Wan 2.1 supporta la generazione video multi-task (text-to-video, image-to-video, video editing, ecc.), la resa di testo multilingue nei video, un'elevata efficienza grazie al suo Video VAE causale 3D e supera molti modelli commerciali e open-source nei benchmark.
- Come posso eseguire Wan 2.1 sul mio computer?
Hai bisogno di Python 3.8+, PyTorch 2.4.0+ con CUDA e una GPU NVIDIA (8GB+ di VRAM per il modello piccolo, 16-24GB per il modello grande). Clona il repository GitHub, installa le dipendenze, scarica i pesi del modello e utilizza gli script forniti per generare video localmente.
- Perché Wan 2.1 è importante per la generazione video AI?
Wan 2.1 democratizza l'accesso alla generazione video allo stato dell'arte essendo open-source e gratuito, permettendo a sviluppatori, ricercatori e creativi di sperimentare e innovare senza barriere economiche o restrizioni proprietarie.
- Come si confronta Wan 2.1 con modelli come Sora o Runway Gen-2?
A differenza delle alternative closed-source come Sora o Runway Gen-2, Wan 2.1 è completamente open-source ed eseguibile localmente. In generale supera i precedenti modelli open-source e si confronta o supera molte soluzioni commerciali nei benchmark di qualità.
Arshia è una AI Workflow Engineer presso FlowHunt. Con una formazione in informatica e una passione per l'IA, è specializzata nella creazione di workflow efficienti che integrano strumenti di intelligenza artificiale nelle attività quotidiane, migliorando produttività e creatività.

Arshia Kahani
AI Workflow Engineer
Prova FlowHunt e costruisci soluzioni AI
Inizia a creare i tuoi strumenti AI e flussi di lavoro per la generazione video con FlowHunt oppure prenota una demo per vedere la piattaforma in azione.
Scopri di più

