Descrizione del componente
Come funziona il componente LLM Gemini
Cos’è il componente LLM Gemini?
Il componente LLM Gemini collega i modelli Gemini di Google al tuo flow. Sebbene la vera magia avvenga nei Generator e negli Agent, i componenti LLM ti permettono di controllare il modello utilizzato. Tutti i componenti hanno di default ChatGPT-4. Puoi collegare questo componente se desideri cambiare modello o avere un maggiore controllo su di esso.
Ricorda che collegare un componente LLM è facoltativo. Tutti i componenti che usano un LLM hanno ChatGPT-4o come default. I componenti LLM ti permettono di cambiare modello e controllare le impostazioni del modello.
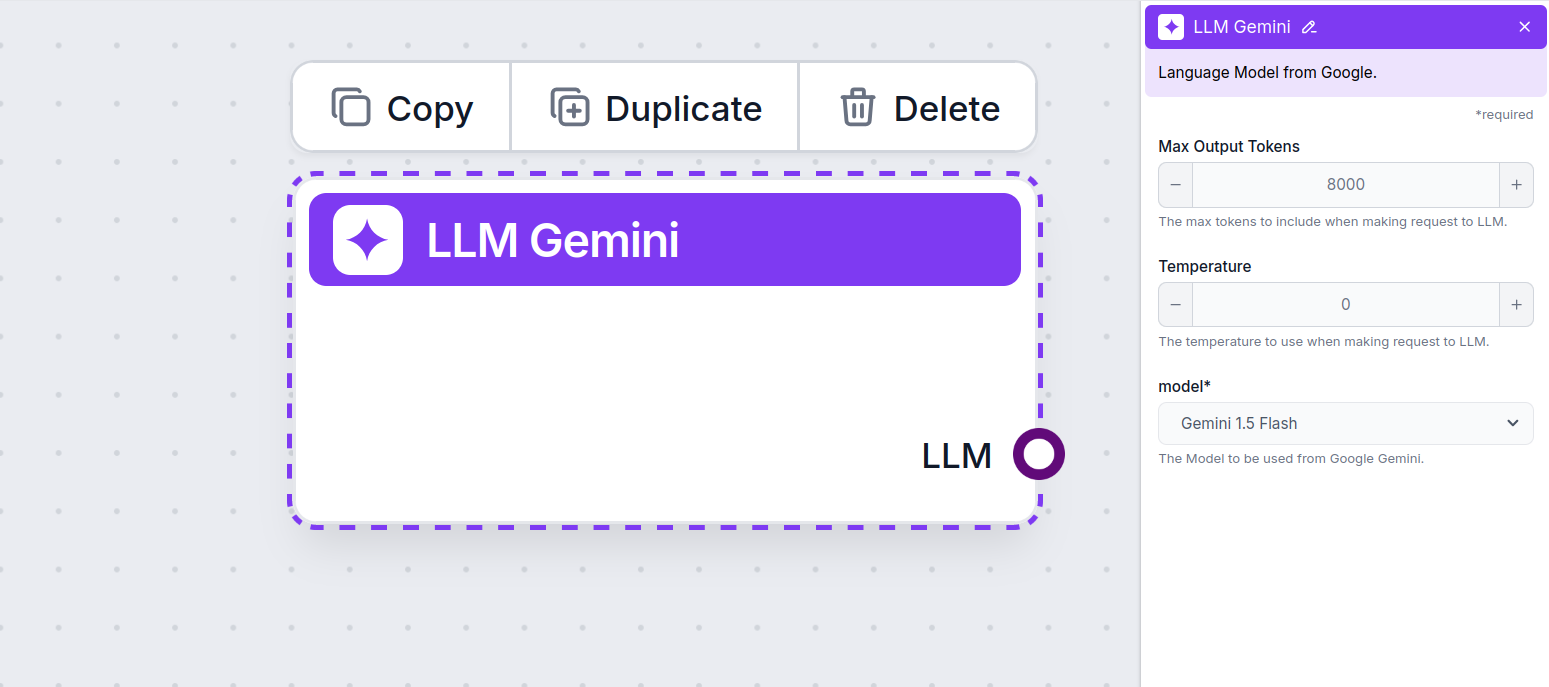
Impostazioni del componente LLM Gemini
Max Token
I token rappresentano le singole unità di testo che il modello elabora e genera. L’uso dei token varia in base ai modelli, e un singolo token può essere una parola, una sotto-parola o un singolo carattere. I modelli sono solitamente tariffati a milioni di token.
L’impostazione dei max token limita il numero totale di token che possono essere processati in una singola interazione o richiesta, assicurando che le risposte siano generate entro limiti ragionevoli. Il limite predefinito è 4.000 token, la dimensione ottimale per riassumere documenti e più fonti per generare una risposta.
Temperatura
La temperatura controlla la variabilità delle risposte, partendo da 0 a 1.
Una temperatura di 0.1 renderà le risposte molto dirette ma potenzialmente ripetitive e carenti.
Una temperatura elevata di 1 permette la massima creatività nelle risposte, ma comporta il rischio di risposte irrilevanti o addirittura allucinatorie.
Ad esempio, la temperatura consigliata per un bot di assistenza clienti è tra 0.2 e 0.5. Questo livello dovrebbe mantenere le risposte pertinenti e aderenti allo script, consentendo comunque una variazione naturale.
Modello
Questo è il selettore del modello. Qui troverai tutti i modelli Gemini supportati da Google. Supportiamo tutti gli ultimi modelli Gemini:
- Gemini 2.0 Flash Experimental – Un modello avanzato a bassa latenza progettato per agenti. Presenta nuove capacità come l’uso nativo degli strumenti, la creazione di immagini e la generazione vocale. Scopri come il modello Google più avanzato ha gestito compiti di routine nei nostri test.
- Gemini 1.5 Flash – Un modello multimodale leggero ottimizzato per velocità ed efficienza, in grado di elaborare input audio, immagini, video e testo, con una finestra di contesto fino a 1.048.576 token. Scopri di più qui.
- Gemini 1.5 Flash-8B – Una variante più piccola, veloce ed economica del modello 1.5 Flash, che offre capacità multimodali simili con un prezzo inferiore del 50% e limiti di velocità doppi rispetto al 1.5 Flash. Quanto è buono l’output del modello più debole? Scoprilo qui.
- Gemini 1.5 Pro – Un modello multimodale di medie dimensioni ottimizzato per un’ampia gamma di compiti di ragionamento, in grado di elaborare grandi quantità di dati, inclusi input audio e video estesi, con un limite di input di 2.097.152 token. Vedi esempi di output.
Come aggiungere il componente LLM Gemini al tuo Flow
Noterai che tutti i componenti LLM hanno solo una maniglia di output. L’input non passa attraverso il componente, poiché rappresenta solo il modello, mentre la generazione avviene realmente negli AI Agent e Generator.
La maniglia LLM è sempre viola. La maniglia di input LLM si trova in qualsiasi componente che utilizza l’AI per generare testo o elaborare dati. Puoi vedere le opzioni facendo clic sulla maniglia:
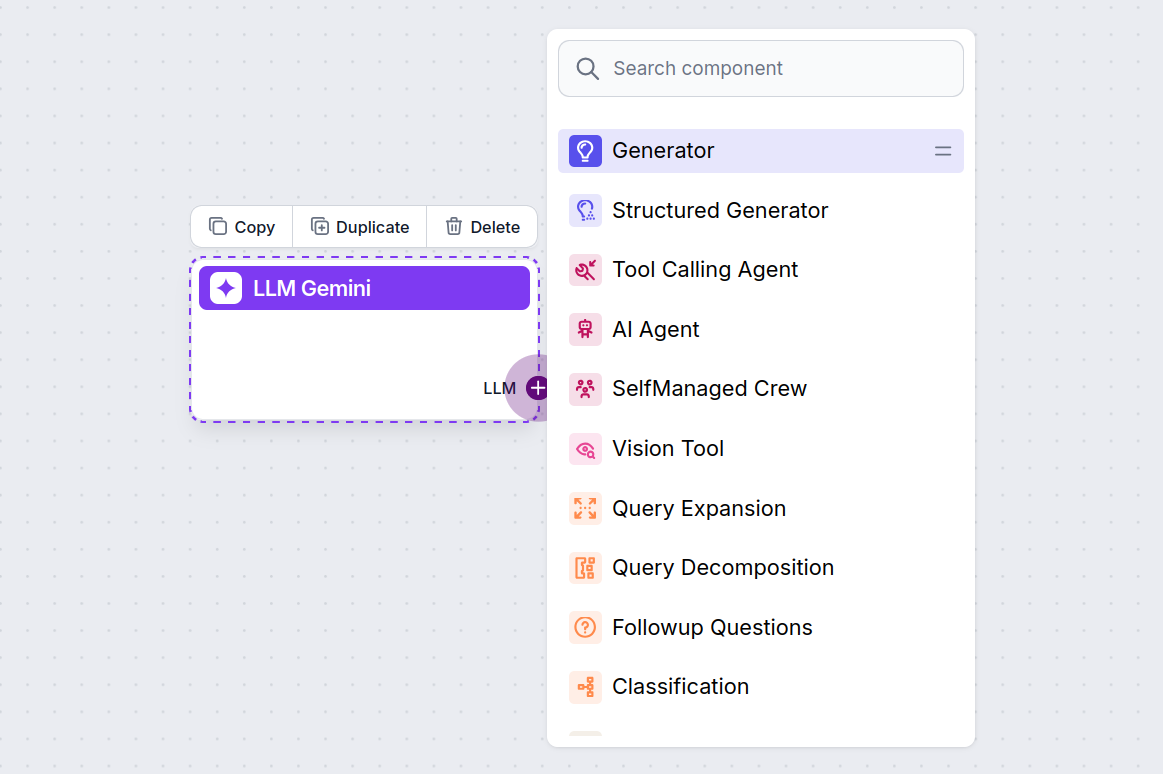
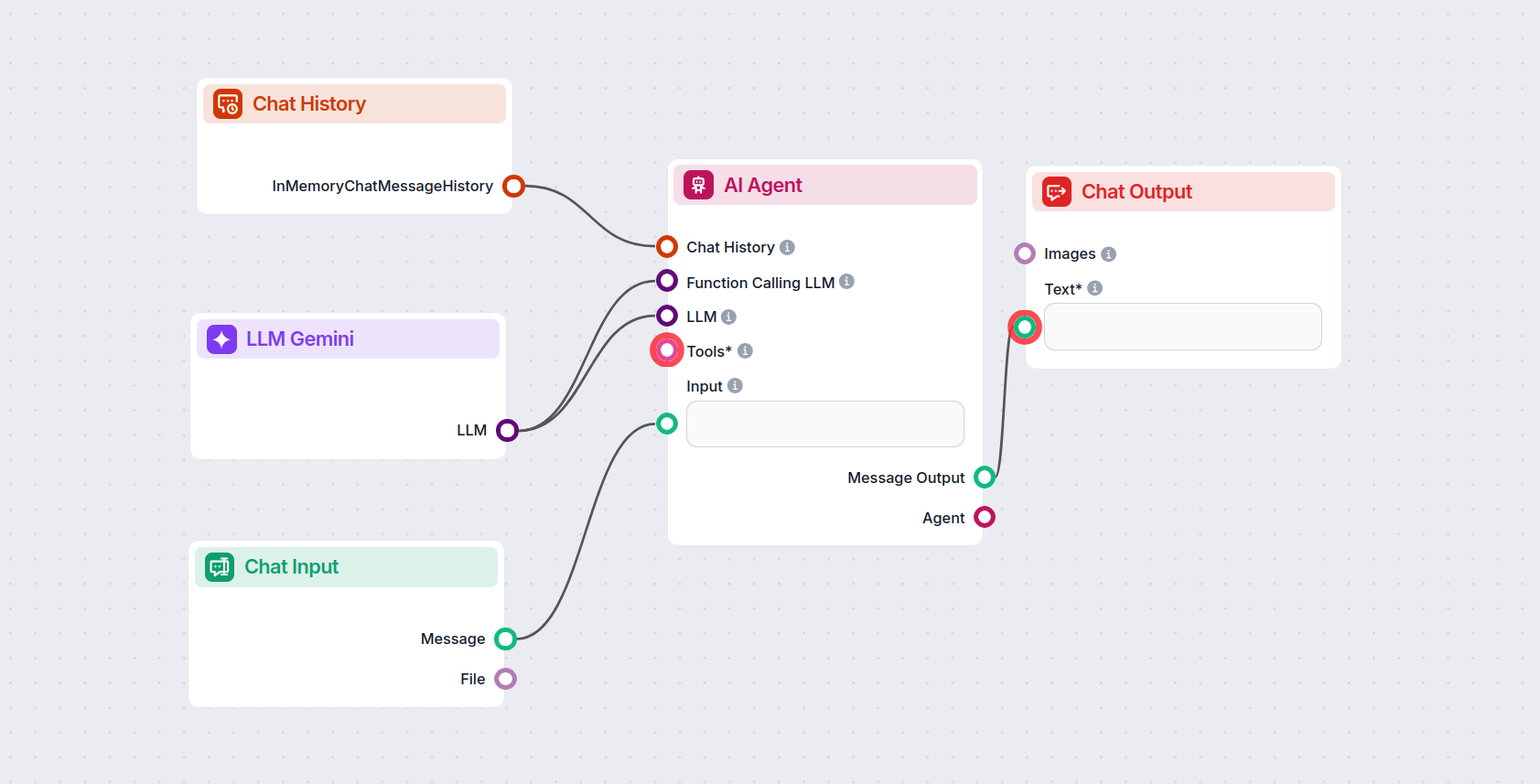
Questo ti permette di creare ogni tipo di strumento. Vediamo il componente in azione. Ecco un semplice flow chatbot AI Agent che utilizza Gemini 2.0 Flash Experimental per generare risposte. Puoi considerarlo come un chatbot Gemini di base.
Questo semplice Chatbot Flow include:
- Chat input: rappresenta il messaggio inviato dall’utente in chat.
- Chat history: garantisce che il chatbot possa ricordare e considerare le risposte precedenti.
- Chat output: rappresenta la risposta finale del chatbot.
- AI Agent: un agente AI autonomo che genera le risposte.
- LLM Gemini: la connessione ai modelli di generazione testo di Google.
Esempi di modelli di flusso che utilizzano il componente LLM Gemini
Per aiutarti a iniziare rapidamente, abbiamo preparato diversi modelli di flusso di esempio che mostrano come utilizzare efficacemente il componente LLM Gemini. Questi modelli presentano diversi casi d'uso e best practice, rendendo più facile per te comprendere e implementare il componente nei tuoi progetti.
Domande frequenti
- Cos'è il componente LLM Gemini in FlowHunt?
LLM Gemini collega i modelli Gemini di Google ai tuoi flussi AI di FlowHunt, permettendoti di scegliere tra le ultime varianti Gemini per la generazione di testi e personalizzare il loro comportamento.
- Quali modelli Gemini sono supportati?
FlowHunt supporta Gemini 2.0 Flash Experimental, Gemini 1.5 Flash, Gemini 1.5 Flash-8B e Gemini 1.5 Pro—ognuno offre capacità uniche per input di testo, immagini, audio e video.
- Come influenzano Max Token e Temperatura le risposte?
Max Token limita la lunghezza della risposta, mentre Temperatura controlla la creatività—valori bassi danno risposte più mirate, valori alti consentono maggiore varietà. Entrambi possono essere impostati per ogni modello in FlowHunt.
- È obbligatorio usare il componente LLM Gemini?
No, l'utilizzo dei componenti LLM è facoltativo. Tutti i flussi AI hanno di default ChatGPT-4o, ma aggiungendo LLM Gemini puoi passare ai modelli Google e perfezionare le impostazioni.
Prova Google Gemini con FlowHunt
Inizia a creare chatbot AI avanzati e strumenti con Gemini e altri modelli di punta—tutto in una sola dashboard. Cambia modello, personalizza le impostazioni e semplifica i tuoi flussi di lavoro.
Scopri di più