URL Retriever
URL Retriever ti permette di recuperare e processare contenuti da link web, supportando OCR, estrazione di metadati e output flessibili per alimentare i flussi di lavoro AI.
Descrizione del componente
Come funziona il componente URL Retriever
Componente URL Retriever
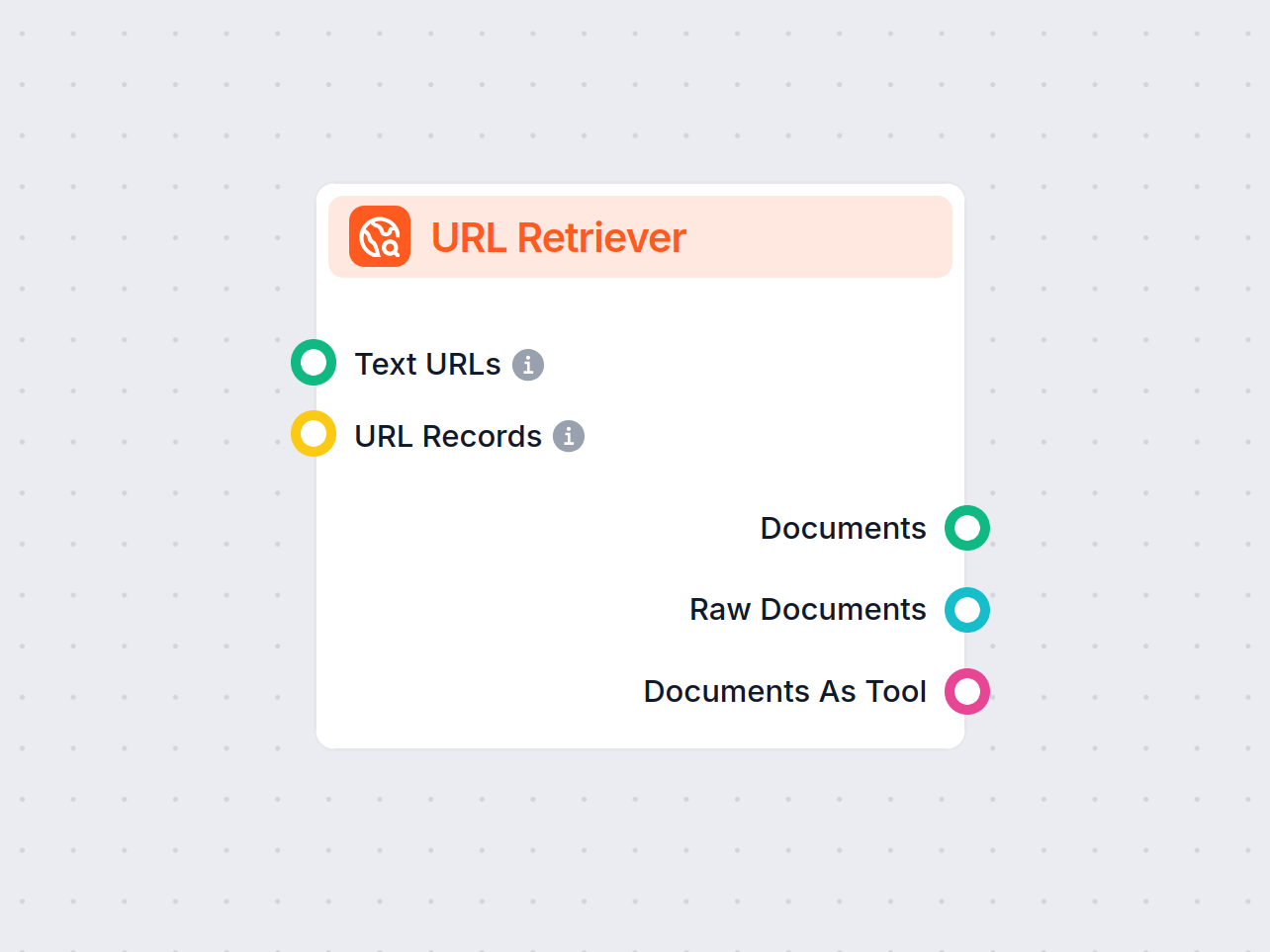
Il URL Retriever è un componente versatile progettato per recuperare e processare contenuti web da URL specificati, restituendo le informazioni come documenti strutturati. Funziona come ponte tra contenuti online esterni e il tuo flusso di lavoro AI, permettendoti di integrare, analizzare o processare informazioni web in modo efficiente.
Cosa fa?
Questo componente recupera il contenuto di uno o più URL forniti come input. Può estrarre il testo principale, i metadati e persino processare contenuti da immagini usando il riconoscimento ottico dei caratteri (OCR). I dati recuperati sono quindi disponibili in vari formati strutturati adatti a compiti AI a valle come riassunti, domande e risposte o estrazione di conoscenza.
Opzioni di input
Puoi fornire gli URL al componente in due modi:
URL di testo:
- Tipo di input:
Message - Descrizione: Un elenco di link URL semplici da cui il componente deve recuperare i contenuti.
- Tipo di input:
Record URL:
- Tipo di input:
UrlRecord - Descrizione: Un elenco di record URL strutturati, che possono includere metadati aggiuntivi.
- Tipo di input:
Parametri avanzati di input
| Parametro | Tipo | Default | Descrizione |
|---|---|---|---|
| Applica OCR | Booleano | false | Se abilitato, applica OCR per estrarre testo dalle immagini nel documento. |
| Cache TTL | Dropdown | 2 settimane | Per quanto tempo il contenuto deve essere memorizzato in cache, con opzioni da nessuna cache fino a 1 anno. |
| Da H1 se esiste | Booleano | true | Inizia l’estrazione dal tag H1 se presente, concentrandosi sul contenuto principale. |
| Carica da puntatore | Booleano | true | Carica il contenuto a partire dalla sezione più rilevante in base alla tua query. |
| Nascondi risorse | Booleano | false | Nasconde le risorse recuperate dall’output o dalla visualizzazione. |
| Max Token | Intero | 3000 | Imposta il numero massimo di token per il testo di output. |
| Salta ultima intestazione | Booleano | true | Salta l’ultima intestazione durante l’estrazione per un contenuto più lineare. |
| Strategia | Dropdown | Includi stessa quantità da ogni documento | Determina come combinare i contenuti: concatenare completamente o includere parti uguali da ciascun documento. |
| Esporta contenuti | Multi-select | Tutti | Scegli quali elementi HTML esportare (H1-H6, Paragrafo). |
| Includi metadati | Multi-select | Prodotto | Specifica quali campi di metadati includere (es. Prodotto, Autore, Sito web, ecc.). |
| Verbose | Booleano | false | Abilita output dettagliato per debugging o informazioni. |
| Nome strumento | Stringa | (vuoto) | Assegna facoltativamente un nome personalizzato allo strumento per il riferimento degli agenti. |
| Descrizione strumento | Multilinea | (vuoto) | Fornisci una descrizione per aiutare gli agenti a comprendere lo scopo dello strumento. |
Output
URL Retriever fornisce i suoi output in diversi formati, permettendo un’integrazione flessibile con vari processi AI:
| Nome Output | Tipo | Descrizione |
|---|---|---|
| Documenti | Message | Il contenuto processato dagli URL, pronto all’uso in flussi di lavoro orientati ai messaggi. |
| Documenti Grezzi | Document | Gli oggetti documento grezzi, non processati, per elaborazioni avanzate successive. |
| Documenti come Strumento | Tool | Il contenuto impacchettato come uno strumento, per permettere ai flussi agent-based di utilizzarlo. |
Perché usare URL Retriever?
- Integra conoscenza esterna: Porta senza sforzo informazioni web nelle tue applicazioni AI, come chatbot, motori di ricerca o knowledge base.
- Estrazione personalizzabile: Affina quali contenuti e metadati vuoi, controlla la quantità di dati ed utilizza l’OCR per le immagini.
- Prestazioni & Efficienza: Utilizza la cache per evitare download ridondanti e limita i token di output per migliorare le prestazioni.
- Formati di output flessibili: Scegli il formato di output che meglio si adatta al prossimo step del tuo flusso di lavoro: documento strutturato, messaggio o strumento.
Esempi d’uso
- Creazione di agenti conversazionali basati sulla conoscenza che rispondono usando contenuti web aggiornati.
- Aggregazione di dati di prodotto da siti e-commerce per confronti o analisi.
- Monitoraggio e analisi di articoli di blog o notizie su argomenti o keyword specifici.
- Estrazione di informazioni da pagine web con media misti (testo e immagini).
Tabella di riepilogo
| Caratteristica | Descrizione |
|---|---|
| Recupera URL | Recupera e processa contenuti web dagli URL forniti. |
| Supporto OCR | Estrae testo dalle immagini nei documenti se abilitato. |
| Estrazione metadati | Opzionalmente include metadati come autore, prodotto o tipi schema.org. |
| Output personalizzabile | Seleziona quali elementi HTML o metadati esportare. |
| Cache | Durate di cache configurabili per l’efficienza. |
| Tipi di output multipli | Supporta output come messaggio, documento grezzo e strumento per flessibilità nei flussi. |
Il URL Retriever è un ponte potente e flessibile tra i contenuti web e i tuoi flussi di lavoro AI, offrendo controllo granulare sull’estrazione e l’integrazione dei contenuti.
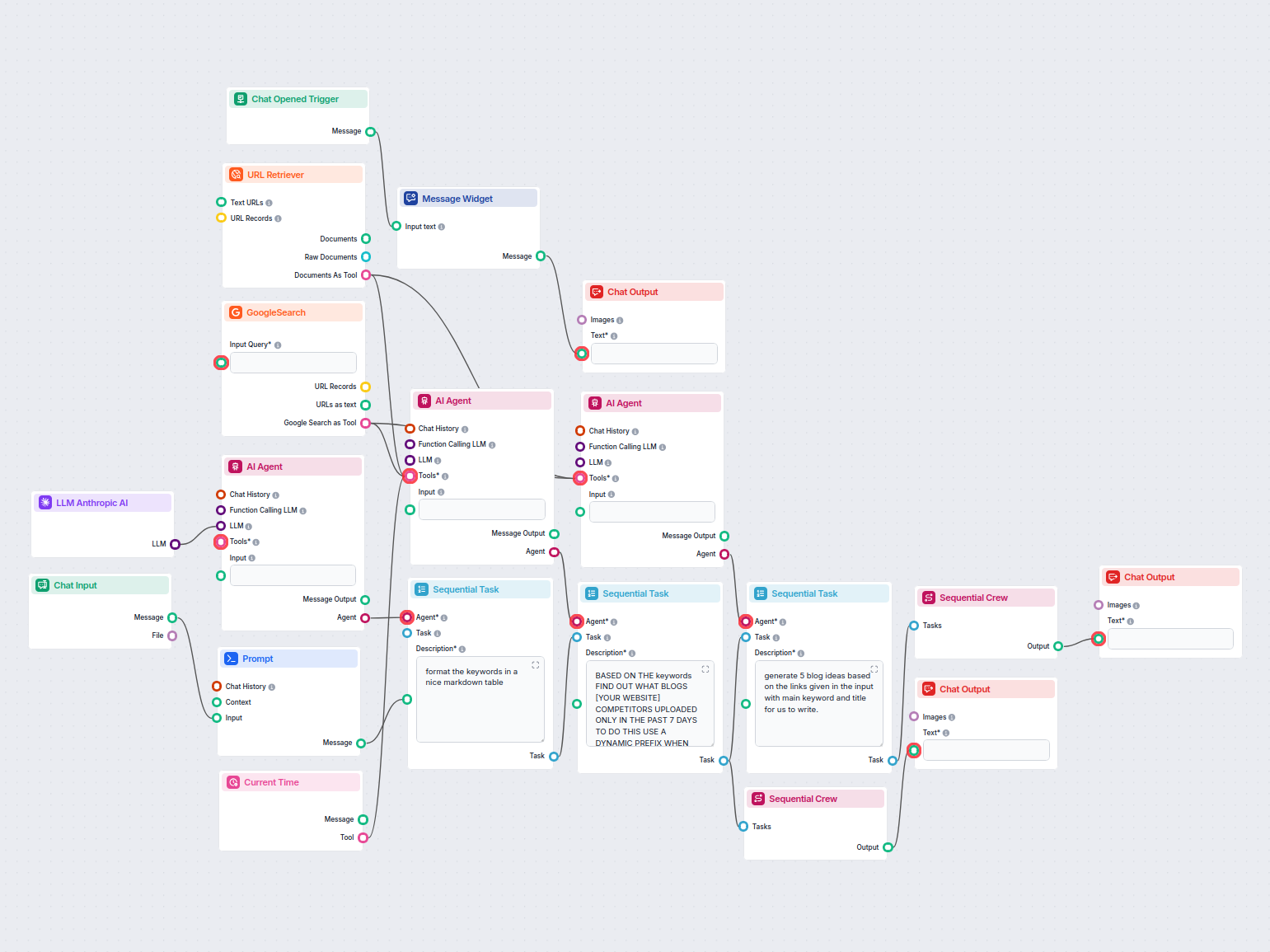
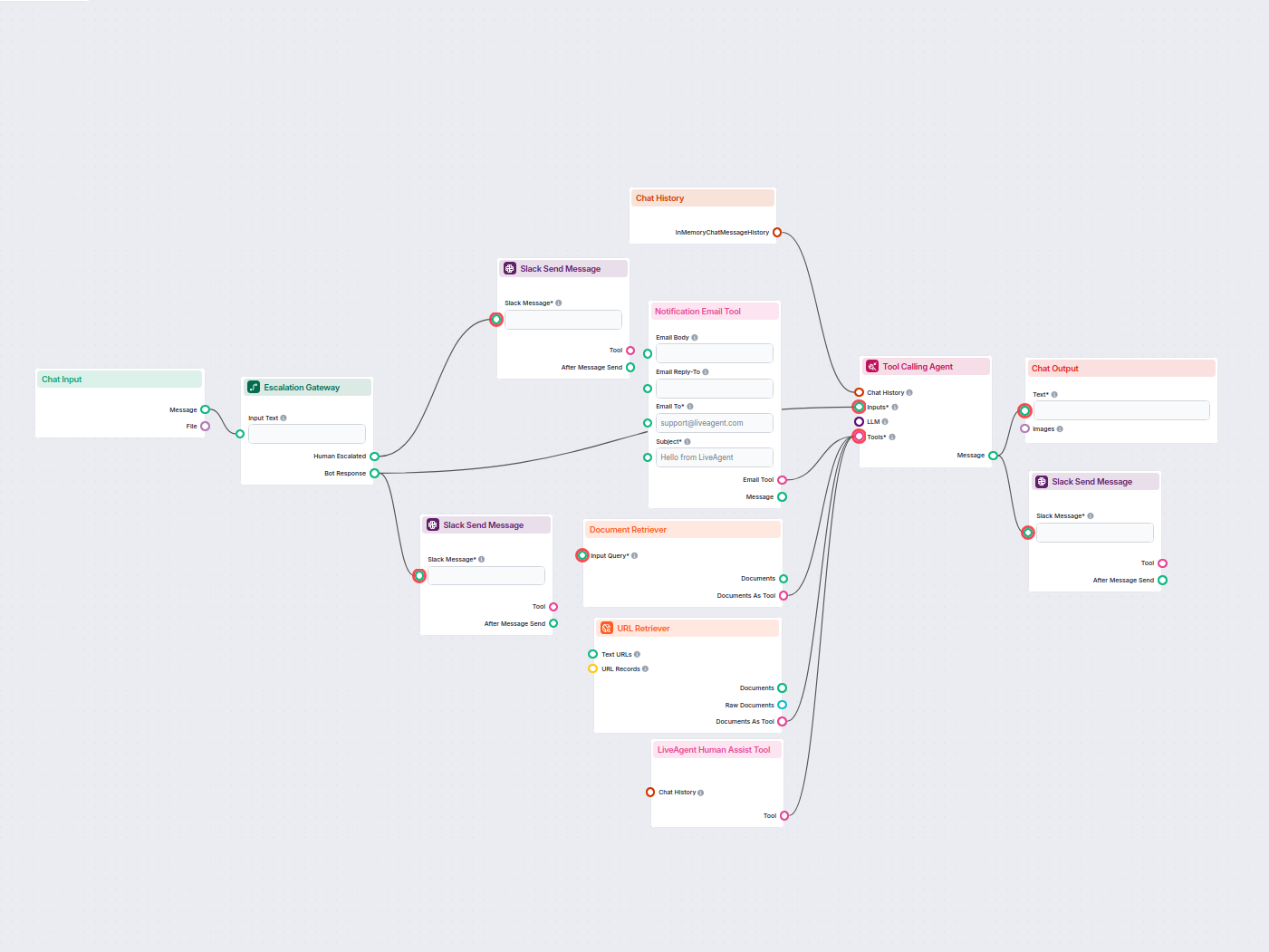
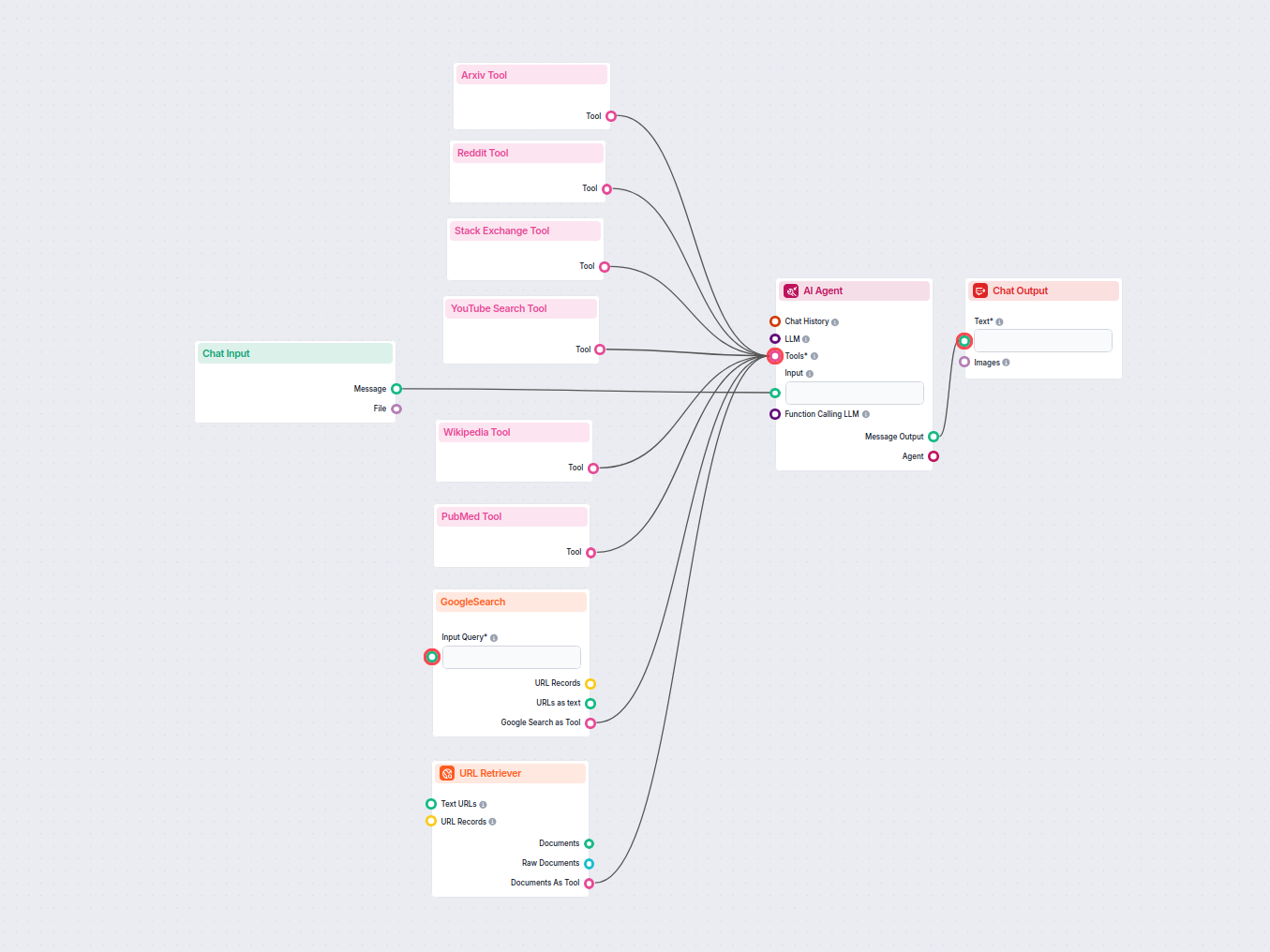
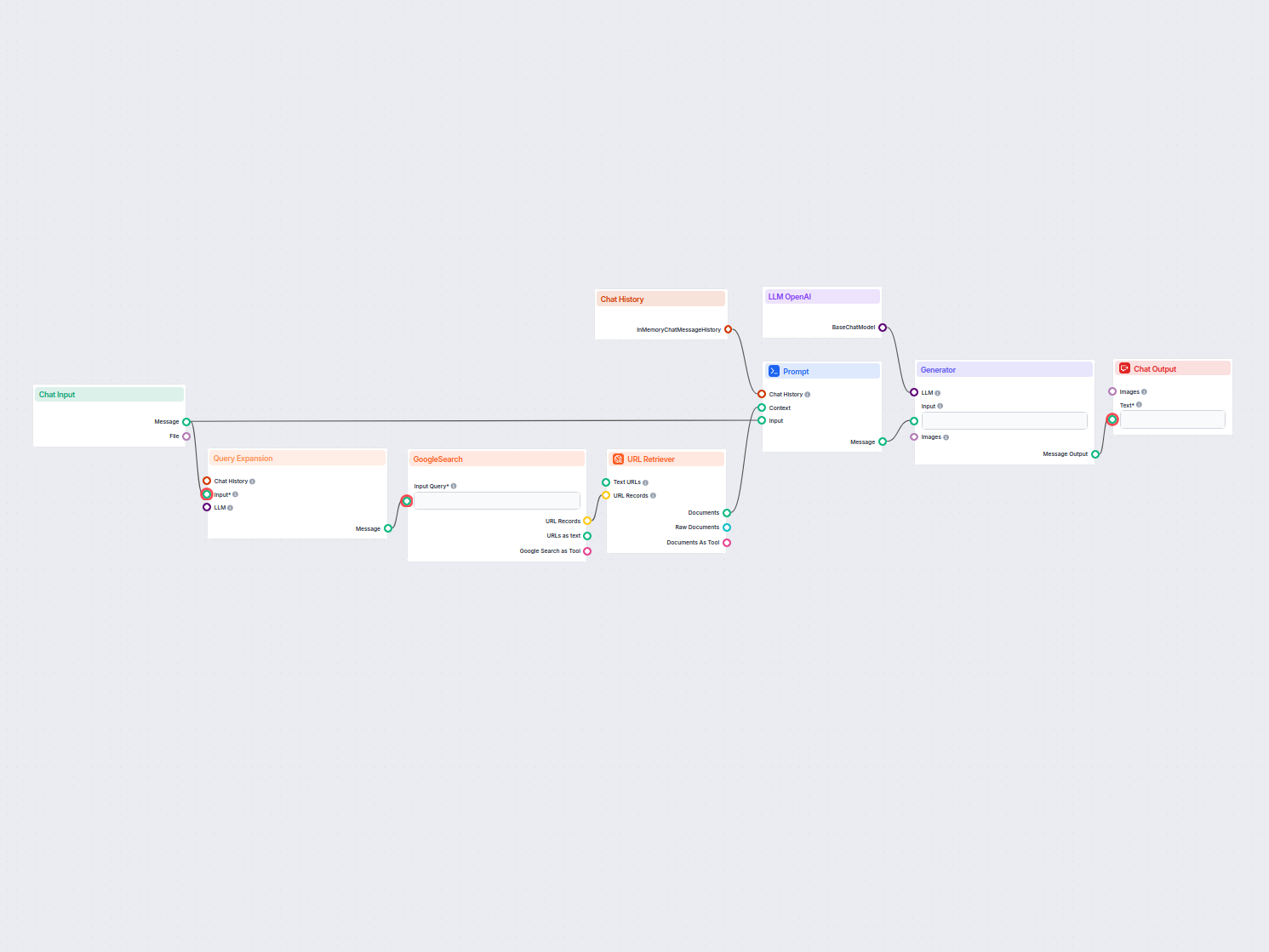
Esempi di modelli di flusso che utilizzano il componente URL Retriever
Per aiutarti a iniziare rapidamente, abbiamo preparato diversi modelli di flusso di esempio che mostrano come utilizzare efficacemente il componente URL Retriever. Questi modelli presentano diversi casi d'uso e best practice, rendendo più facile per te comprendere e implementare il componente nei tuoi progetti.



















































Domande frequenti
- Cosa fa il componente URL Retriever?
URL Retriever recupera e processa contenuti da link web specificati, rendendo testo e metadati da documenti online disponibili per il tuo flusso di lavoro o agente AI.
- Può estrarre contenuti da immagini o PDF?
Sì, attivando l'opzione OCR, il componente può estrarre testo da documenti basati su immagini o PDF scansionati.
- Quali tipi di output fornisce?
Restituisce documenti processati come messaggi di testo, oggetti documento grezzi, o come strumento per i flussi di lavoro degli agenti, a seconda della configurazione.
- Come funziona la cache in URL Retriever?
Puoi impostare per quanto tempo i contenuti recuperati vengono memorizzati in cache, riducendo i download ripetuti e velocizzando i tuoi flussi.
- Posso controllare quali parti di una pagina web vengono estratte?
Sì, puoi specificare quali intestazioni, paragrafi o campi di metadati includere nell'output, permettendo un'estrazione mirata.
- È adatto per costruire bot di conoscenza o automazioni di dati web?
Assolutamente. URL Retriever è essenziale per qualsiasi automazione o chatbot che deve leggere, processare o riassumere contenuti web in tempo reale.
Prova FlowHunt URL Retriever
Potenzia i tuoi flussi di lavoro integrando contenuti web in tempo reale. Estrai, processa e utilizza dati dagli URL con facilità.
Scopri di più