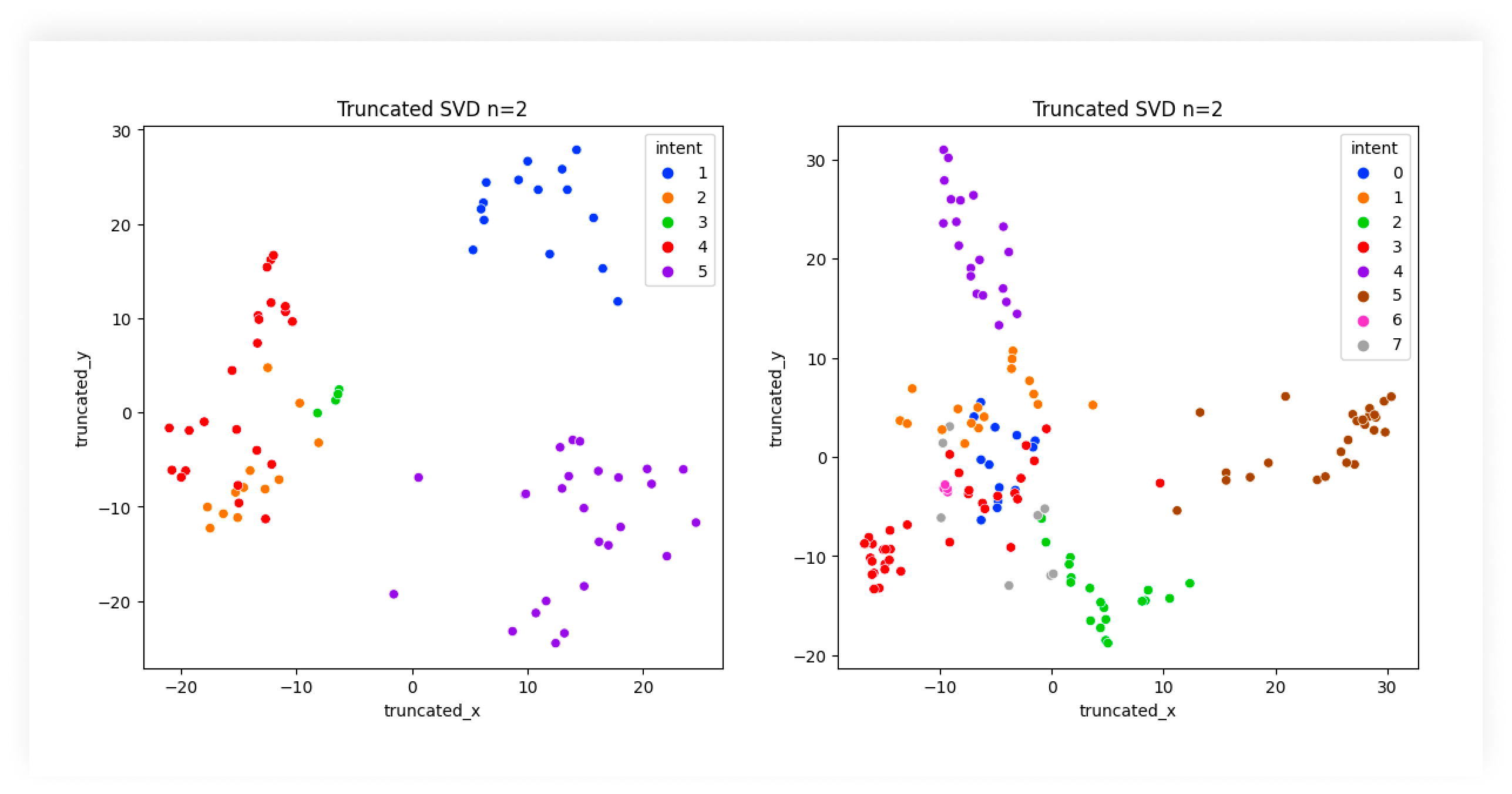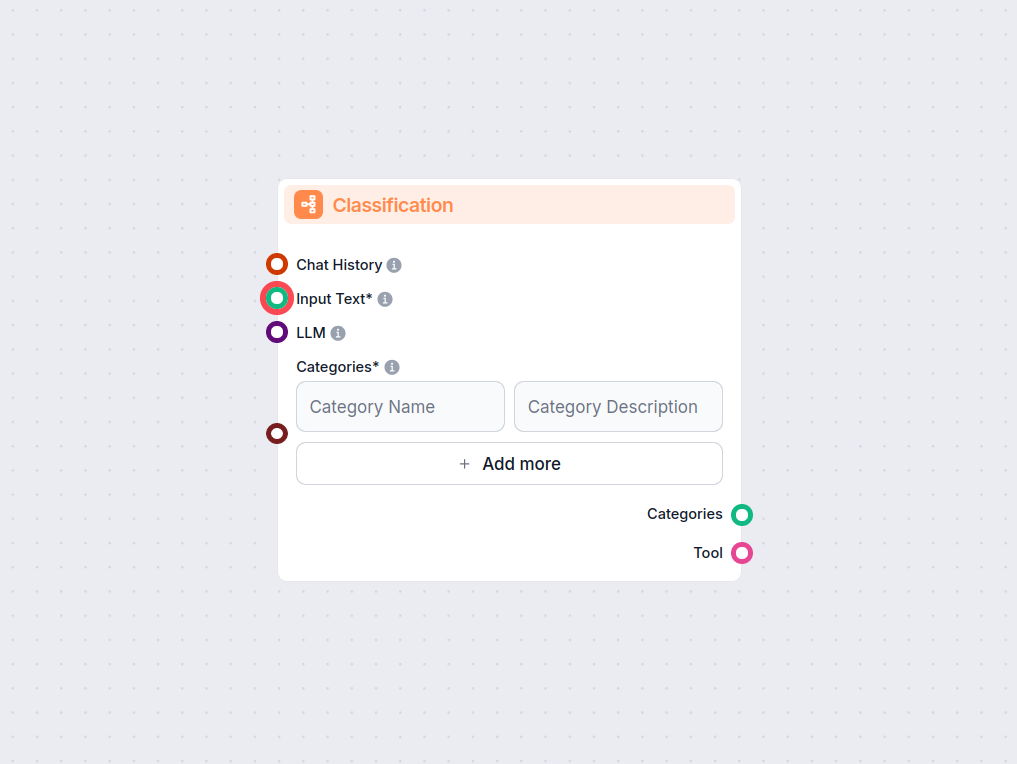
Classificatore
Un classificatore AI categorizza i dati in classi predefinite utilizzando il machine learning, abilitando il processo decisionale automatico in applicazioni come il rilevamento spam, la diagnosi medica e il riconoscimento delle immagini.
Un classificatore AI è un tipo di algoritmo di apprendimento automatico che assegna un’etichetta di classe ai dati in ingresso. In sostanza, categorizza i dati in classi predefinite sulla base di schemi appresi dai dati storici. I classificatori AI sono strumenti fondamentali nei campi dell’intelligenza artificiale e della data science, consentendo ai sistemi di prendere decisioni informate interpretando e organizzando dataset complessi.
Comprendere la classificazione AI
La classificazione è un processo di apprendimento supervisionato in cui un algoritmo apprende da dati di addestramento etichettati per prevedere le etichette di classe di dati non visti. L’obiettivo è creare un modello che assegni in modo accurato nuove osservazioni a una delle categorie predefinite. Questo processo è cruciale in molteplici applicazioni, dal rilevamento dello spam nelle email alla diagnosi medica.
Concetti chiave della classificazione AI
- Etichette di classe: Categorie o gruppi in cui i punti dati vengono classificati. Ad esempio, ‘spam’ o ‘non spam’ nel filtraggio delle email.
- Caratteristiche (Features): Attributi o proprietà dei dati utilizzati dal classificatore per prendere decisioni. Nel riconoscimento delle immagini, le caratteristiche possono includere valori dei pixel o bordi.
- Dati di addestramento: Un dataset con etichette di classe note utilizzato per insegnare al classificatore. Aiuta l’algoritmo a imparare gli schemi associati a ciascuna classe.
Tipi di problemi di classificazione
I compiti di classificazione possono essere suddivisi in base al numero e alla natura delle etichette di classe.
Classificazione binaria
La classificazione binaria prevede l’assegnazione dei dati a una delle due classi. È la forma più semplice di classificazione, che affronta scenari sì/no o vero/falso.
Esempi:
- Rilevamento email spam: Classifica le email come ‘spam’ o ‘non spam’. Il classificatore analizza caratteristiche come indirizzo del mittente, parole chiave nel contenuto e collegamenti ipertestuali per determinare la probabilità di spam.
- Diagnosi medica: Prevede se un paziente ha una malattia (‘positivo’) o meno (‘negativo’) in base ai risultati di test clinici.
- Rilevamento delle frodi: Identifica le transazioni come ‘fraudolente’ o ‘legittime’ esaminando importi delle transazioni, località e modelli di comportamento dell’utente.
Classificazione multiclasse
La classificazione multiclasse riguarda scenari in cui i dati possono appartenere a più di due categorie.
Esempi:
- Riconoscimento immagini: Classifica immagini di cifre scritte a mano (0-9) nei sistemi postali per lo smistamento automatico.
- Classificazione di testi: Categorizza articoli di notizie in ‘sport’, ‘politica’, ‘tecnologia’ ecc., in base al contenuto.
- Identificazione di specie: Classifica piante o animali in specie in base a caratteristiche come morfologia o informazioni genetiche.
Classificazione multilabel
Nella classificazione multilabel, ogni punto dati può appartenere contemporaneamente a più classi.
Esempi:
- Tagging di documenti: Assegna più tag a un documento, come ‘machine learning’, ‘data science’ e ‘intelligenza artificiale’ in base al contenuto.
- Classificazione di generi musicali: Una canzone può essere classificata sotto i generi ‘rock’, ‘blues’ e ‘alternative’ contemporaneamente.
- Annotazione immagini: Identifica tutti gli oggetti presenti in un’immagine, come ‘persona’, ‘bicicletta’ e ‘semaforo’.
Classificazione sbilanciata
La classificazione sbilanciata si verifica quando la distribuzione delle classi è squilibrata e una classe supera significativamente le altre.
Esempi:
- Rilevamento delle frodi: Le transazioni fraudolente sono rare rispetto a quelle legittime, rendendo il dataset sbilanciato.
- Diagnostica medica: Malattie con bassa prevalenza creano dataset sbilanciati nella diagnosi delle condizioni.
- Rilevamento di anomalie: Identifica eventi rari o outlier nei dataset, come intrusioni di rete.
Algoritmi di classificazione comuni
Diversi algoritmi possono essere utilizzati per costruire classificatori AI, ognuno con il proprio approccio e vantaggi.
Regressione logistica
Nonostante il nome, la regressione logistica viene utilizzata per compiti di classificazione, in particolare per la classificazione binaria.
- Come funziona: Modella la probabilità che un dato input appartenga a una determinata classe tramite la funzione logistica.
- Applicazioni:
- Credit scoring: Previsione della probabilità che un mutuatario non restituisca un prestito.
- Marketing: Determinazione della probabilità che un cliente risponda a un’offerta promozionale.
Alberi decisionali
Gli alberi decisionali utilizzano un modello ad albero delle decisioni, dove ogni nodo rappresenta un test su una caratteristica, ogni ramo un risultato e ogni foglia un’etichetta di classe.
- Come funziona: L’albero suddivide il dataset in base ai valori delle caratteristiche, prendendo decisioni a ogni nodo per separare efficacemente i dati.
- Applicazioni:
- Segmentazione clienti: Classificazione dei clienti in base ai comportamenti di acquisto.
- Diagnosi medica: Assistenza nella diagnosi delle malattie sulla base di sintomi e risultati di test.
Support Vector Machines (SVM)
Le SVM sono potenti sia per la classificazione lineare che non lineare e risultano efficaci in spazi ad alta dimensionalità.
- Come funziona: Trovano l’iperpiano che separa meglio le classi nello spazio delle caratteristiche.
- Applicazioni:
- Classificazione di testi: Categorizzazione di email o documenti in argomenti.
- Riconoscimento immagini: Classificazione di immagini in base agli schemi di intensità dei pixel.
Reti neurali
Le reti neurali sono ispirate al cervello umano ed eccellono nel catturare schemi complessi nei dati.
- Come funziona: Composte da strati di nodi (neuroni), le reti neurali apprendono rappresentazioni gerarchiche dei dati attraverso l’addestramento.
- Applicazioni:
- Riconoscimento immagini: Identificazione di oggetti, volti o numeri scritti a mano nelle immagini.
- Elaborazione del linguaggio naturale: Compiti come analisi del sentiment, traduzione automatica e classificazione di testi.
Random Forest
Le random forest sono insiemi di alberi decisionali che migliorano la precisione della previsione riducendo l’overfitting.
- Come funziona: Vengono costruiti più alberi decisionali utilizzando sottoinsiemi casuali di dati e caratteristiche, e le loro previsioni vengono aggregate.
- Applicazioni:
- Importanza delle caratteristiche: Determinazione delle caratteristiche più significative per le previsioni.
- Compiti di classificazione: Versatili per molte applicazioni come la previsione del default su prestiti o la classificazione di malattie.
Addestramento dei classificatori AI
Addestrare un classificatore AI richiede diversi passaggi per garantire che possa generalizzare bene a nuovi dati non visti.
Preparazione dei dati di addestramento
Dati di addestramento di qualità sono fondamentali. I dati devono essere:
- Etichettati: Ogni punto dati deve avere la corretta etichetta di classe.
- Rappresentativi: Devono coprire la varietà di casi che il classificatore potrebbe incontrare.
- Puliti: Privi di errori, valori mancanti o informazioni irrilevanti.
Apprendimento del modello
Durante l’addestramento, il classificatore apprende gli schemi nei dati.
- Estrazione delle caratteristiche: Identificazione degli attributi più rilevanti che influenzano la classificazione.
- Algoritmo di apprendimento: L’algoritmo selezionato adatta i suoi parametri per minimizzare la differenza tra etichette previste e reali.
- Validazione: Una parte dei dati viene spesso separata per validare il modello durante l’addestramento e prevenire l’overfitting.
Valutazione del modello
Dopo l’addestramento, le prestazioni del classificatore vengono valutate tramite metriche come:
- Accuratezza: Proporzione delle previsioni corrette sul totale delle previsioni.
- Precisione e richiamo: La precisione misura la correttezza delle previsioni positive, mentre il richiamo misura quante effettive positività sono state previste correttamente.
- F1 Score: Media armonica di precisione e richiamo, che fornisce un bilanciamento tra le due.
- Matrice di confusione: Una tabella che descrive le prestazioni in termini di veri positivi, falsi positivi, veri negativi e falsi negativi.
Evitare overfitting e underfitting
- Overfitting: Quando il modello apprende troppo bene i dati di addestramento, inclusi i rumori, e non si generalizza sui nuovi dati.
- Underfitting: Quando il modello è troppo semplice per catturare gli schemi nei dati.
- Tecniche per mitigare:
- Cross-Validation: Validazione del modello su diversi sottoinsiemi dei dati.
- Regolarizzazione: Aggiunta di una penalità per modelli complessi per evitare l’overfitting.
- Potatura (Pruning): Semplificazione degli alberi decisionali rimuovendo sezioni con scarso potere classificatorio.
Applicazioni dei classificatori AI
I classificatori AI sono integrati in vari settori, automatizzando processi decisionali e aumentando l’efficienza.
Rilevamento delle frodi
Le istituzioni finanziarie utilizzano classificatori per identificare transazioni fraudolente.
- Come viene utilizzato:
- Riconoscimento di schemi: Analisi dei modelli di transazione per individuare anomalie.
- Allerta in tempo reale: Notifiche immediate per attività sospette.
- Vantaggi:
- Prevenzione delle perdite: Il rilevamento precoce minimizza le perdite finanziarie.
- Fiducia del cliente: Migliora la reputazione dell’istituzione in materia di sicurezza.
Segmentazione clienti
I classificatori aiutano le aziende a personalizzare le strategie di marketing.
- Come viene utilizzato:
- Raggruppamento clienti: In base a comportamenti, preferenze e dati demografici.
- Marketing personalizzato: Invio di promozioni o raccomandazioni mirate.
- Vantaggi:
- Maggiore coinvolgimento: Contenuti rilevanti migliorano l’interazione del cliente.
- Tassi di conversione superiori: Offerte personalizzate portano più vendite.
Riconoscimento di immagini
Nel riconoscimento immagini, i classificatori identificano oggetti, persone o schemi nelle immagini.
- Come viene utilizzato:
- Riconoscimento facciale: Sblocco di dispositivi o tag nelle foto sui social media.
- Imaging medico: Rilevamento di tumori o anomalie in radiografie e risonanze.
- Vantaggi:
- Automazione: Riduce la necessità di analisi manuale delle immagini.
- Precisione: Alta accuratezza in compiti come la diagnostica.
Elaborazione del linguaggio naturale (NLP)
I classificatori elaborano e analizzano grandi quantità di dati in linguaggio naturale.
- Come viene utilizzato:
- Analisi del sentiment: Determinazione del sentimento di dati testuali (positivo, negativo, neutro).
- Filtro spam: Identificazione e filtraggio di email non richieste.
- Vantaggi:
- Insight: Comprensione delle opinioni e feedback dei clienti.
- Efficienza: Automazione della classificazione e gestione dei dati testuali.
Chatbot e assistenti AI
I classificatori permettono ai chatbot di comprendere e rispondere in modo appropriato agli input degli utenti.
- Come viene utilizzato:
- Riconoscimento dell’intento: Classificazione delle richieste degli utenti per determinare l’azione desiderata.
- Generazione di risposte: Fornitura di risposte pertinenti o svolgimento di compiti.
- Vantaggi:
- Supporto 24/7: Assistenza in qualsiasi momento senza intervento umano.
- Scalabilità: Gestione simultanea di molteplici interazioni.
Casi d’uso ed esempi
Rilevamento email spam
- Problema: Smistare le email tra ‘spam’ e ‘non spam’ per proteggere gli utenti da phishing e contenuti indesiderati.
- Soluzione:
- Caratteristiche utilizzate: Informazioni sul mittente, contenuto dell’email, presenza di link o allegati.
- Algoritmo: I classificatori Naïve Bayes sono comunemente usati per la loro efficacia sui dati testuali.
- Risultato: Esperienza utente migliorata e riduzione del rischio di email dannose.
Diagnosi medica
- Problema: Rilevamento precoce di malattie come il cancro tramite immagini mediche.
- Soluzione:
- Caratteristiche utilizzate: Schemi nei dati di imaging, biomarcatori.
- Algoritmo: Le reti neurali convoluzionali (CNN) sono specializzate nei dati delle immagini.
- Risultato: Maggiore accuratezza nella diagnosi e migliori risultati per i pazienti.
Previsione del comportamento del cliente
- Problema: Prevedere l’abbandono dei clienti per trattenerli.
- Soluzione:
- Caratteristiche utilizzate: Storico degli acquisti, interazioni con il servizio clienti, metriche di coinvolgimento.
- Algoritmo: Random forest o modelli di regressione logistica per gestire interazioni complesse.
- Risultato: Strategie di retention proattive e riduzione dei tassi di abbandono.
Valutazione del rischio finanziario
- Problema: Valutazione del rischio associato ai richiedenti prestito.
- Soluzione:
- Caratteristiche utilizzate: Storico creditizio, stato occupazionale, livello di reddito.
- Algoritmo: Support vector machine o alberi decisionali classificano i livelli di rischio dei richiedenti.
- Risultato: Decisioni di concessione credito più informate e tassi di default ridotti.
Tagging di immagini per la gestione dei contenuti
- Problema: Organizzazione di grandi database di immagini per facilitarne il recupero.
- Soluzione:
- Caratteristiche utilizzate: Caratteristiche visive estratte dalle immagini.
- Algoritmo: Le reti neurali taggano automaticamente le immagini con parole chiave pertinenti.
- Risultato: Gestione dei contenuti efficiente e maggiore ricercabilità.
Classificazione nel machine learning
La classificazione è un problema centrale nel machine learning, alla base di molti algoritmi e sistemi avanzati.
Relazione con gli algoritmi di machine learning
- Apprendimento supervisionato: La classificazione rientra nell’apprendimento supervisionato, in cui i modelli vengono addestrati su dati etichettati.
- Selezione dell’algoritmo: La scelta dell’algoritmo dipende dal tipo di problema, dalla dimensione dei dati e dall’accuratezza desiderata.
- Metriche di valutazione: Metriche come precisione, richiamo e F1 score sono essenziali per valutare le prestazioni del classificatore.
Glossario di machine learning: termini correlati ai classificatori
- Overfitting: Quando un modello apprende troppo bene i dati di addestramento, inclusi i rumori, e ha scarse prestazioni su nuovi dati.
- Underfitting: Quando un modello è troppo semplice per cogliere gli schemi sottostanti nei dati.
- Iperparametri: Impostazioni che influenzano il processo di apprendimento, come la profondità di un albero decisionale o il numero di neuroni in una rete neurale.
- Regolarizzazione: Tecniche usate per evitare l’overfitting penalizzando i modelli complessi.
- Cross-Validation: Metodo per valutare quanto bene un modello si generalizza su un dataset indipendente.
Conclusione
Un classificatore AI è uno strumento fondamentale nell’apprendimento automatico e nell’intelligenza artificiale, che consente ai sistemi di categorizzare e interpretare dati complessi. Comprendendo come funzionano i classificatori, i tipi di problemi di classificazione e gli algoritmi utilizzati, le organizzazioni possono sfruttare questi strumenti per automatizzare processi, prendere decisioni informate e migliorare l’esperienza utente.
Dal rilevamento delle frodi all’alimentazione di chatbot intelligenti, i classificatori sono parte integrante delle moderne applicazioni AI. La loro capacità di apprendere dai dati e migliorare nel tempo li rende preziosi in un mondo sempre più guidato da informazioni e automazione.
Ricerche sui classificatori AI
I classificatori AI sono una componente cruciale nel campo dell’intelligenza artificiale, responsabili della categorizzazione dei dati in classi predefinite sulla base di schemi appresi. Le ricerche recenti hanno approfondito vari aspetti dei classificatori AI, incluse le loro capacità, limitazioni e implicazioni etiche.
“Weak AI” is Likely to Never Become “Strong AI”, So What is its Greatest Value for us? di Bin Liu (2021).
Questo articolo discute la distinzione tra “weak AI” e “strong AI”, evidenziando che, sebbene l’AI abbia eccelso in compiti specifici come la classificazione delle immagini e i giochi, è ancora lontana dal raggiungere l’intelligenza generale. Il lavoro esplora anche il valore dell’AI debole nella sua forma attuale. Leggi di piùThe Switch, the Ladder, and the Matrix: Models for Classifying AI Systems di Jakob Mokander et al. (2024).
Gli autori esaminano diversi modelli per classificare i sistemi AI al fine di colmare il divario tra principi etici e pratica. L’articolo categorizza i sistemi AI usando tre modelli: The Switch, The Ladder e The Matrix, ognuno con i suoi punti di forza e debolezza, fornendo un quadro di riferimento per una migliore governance dell’AI. Leggi di piùCognitive Anthropomorphism of AI: How Humans and Computers Classify Images di Shane T. Mueller (2020).
Questo studio esplora le differenze tra la classificazione delle immagini da parte degli umani e dell’AI, enfatizzando l’antropomorfismo cognitivo, in cui gli umani si aspettano che l’AI imiti l’intelligenza umana. Il lavoro suggerisce strategie come l’AI spiegabile per migliorare l’interazione uomo-AI allineando le capacità dell’AI ai processi cognitivi umani. Leggi di piùAn Information-Theoretic Explanation for the Adversarial Fragility of AI Classifiers di Hui Xie et al. (2019).
Questa ricerca presenta un’ipotesi sulle proprietà di compressione dei classificatori AI, fornendo spunti teorici sulla loro vulnerabilità agli attacchi avversari. Comprendere queste vulnerabilità è fondamentale per sviluppare sistemi AI più robusti. Leggi di più
Domande frequenti
- Cos’è un classificatore AI?
Un classificatore AI è un algoritmo di machine learning che assegna etichette di classe ai dati in ingresso, categorizzandoli in classi predefinite sulla base di schemi appresi dai dati storici.
- Quali sono alcuni tipi comuni di problemi di classificazione?
I problemi di classificazione includono la classificazione binaria (due classi), la classificazione multiclasse (più di due classi), la classificazione multilabel (più etichette per punto dati) e la classificazione sbilanciata (distribuzione delle classi non uniforme).
- Quali algoritmi sono comunemente usati per la classificazione?
Gli algoritmi di classificazione più popolari includono la regressione logistica, gli alberi decisionali, le macchine a vettori di supporto (SVM), le reti neurali e le foreste casuali.
- Quali sono le applicazioni tipiche dei classificatori AI?
I classificatori AI sono utilizzati nel rilevamento dello spam, nella diagnosi medica, nel rilevamento delle frodi, nel riconoscimento delle immagini, nella segmentazione dei clienti, nell’analisi del sentiment e per alimentare chatbot e assistenti AI.
- Come vengono valutati i classificatori AI?
I classificatori AI vengono valutati utilizzando metriche come accuratezza, precisione, richiamo, F1 score e matrice di confusione per determinare le loro prestazioni su dati non visti.
Pronto a costruire la tua intelligenza artificiale?
Chatbot intelligenti e strumenti AI sotto lo stesso tetto. Collega blocchi intuitivi per trasformare le tue idee in Flussi automatizzati.
Scopri di più