Spiegabilità
La spiegabilità dell’AI rende le decisioni dell’intelligenza artificiale trasparenti e comprensibili, costruendo fiducia, rispettando le normative, riducendo i bias e ottimizzando i modelli attraverso metodi come LIME e SHAP.
La spiegabilità dell’AI si riferisce alla capacità di comprendere e interpretare le decisioni e le previsioni fatte dai sistemi di intelligenza artificiale (AI). Con l’aumento della complessità degli algoritmi di AI e machine learning, soprattutto con l’avvento del deep learning e delle reti neurali, questi spesso operano come “scatole nere”. Ciò significa che anche gli ingegneri e i data scientist che sviluppano questi modelli potrebbero non capire pienamente come determinati input portino a specifici output. La spiegabilità dell’AI mira a far luce su questi processi, rendendo i sistemi di AI più trasparenti e i loro risultati più comprensibili agli esseri umani.
Perché è importante la spiegabilità dell’AI?
Fiducia e Trasparenza
Affinché i sistemi di AI siano ampiamente accettati e considerati affidabili, specialmente in settori critici come sanità, finanza e ambito legale, le parti interessate devono comprendere come vengono prese le decisioni. Quando un algoritmo di machine learning raccomanda un trattamento medico o approva una richiesta di prestito, è fondamentale che gli utenti conoscano la logica alla base di queste decisioni per garantire equità e costruire fiducia.
Requisiti Normativi
Molti settori sono soggetti a normative che richiedono trasparenza nei processi decisionali. Le regolamentazioni possono obbligare le organizzazioni a fornire spiegazioni per le decisioni automatizzate, soprattutto quando hanno un impatto significativo sugli individui. Il mancato rispetto può comportare conseguenze legali e perdita di fiducia da parte dei consumatori.
Identificazione e Riduzione dei Bias
I sistemi di AI addestrati su dati distorti possono perpetuare e persino amplificare tali bias. La spiegabilità consente a sviluppatori e stakeholder di individuare processi decisionali ingiusti o distorti all’interno dei modelli AI. Capendo come vengono prese le decisioni, le organizzazioni possono intervenire per correggere i bias, garantendo che i sistemi di AI operino equamente tra diversi gruppi demografici.
Miglioramento delle Prestazioni del Modello
Comprendere il funzionamento interno dei modelli AI consente ai data scientist di ottimizzare le prestazioni. Interpretando quali caratteristiche influenzano le decisioni, possono perfezionare il modello, migliorarne l’accuratezza e assicurare una buona generalizzazione su nuovi dati.
Come si ottiene la spiegabilità dell’AI?
Ottenere la spiegabilità dell’AI implica sia progettare modelli interpretabili sia applicare tecniche per interpretare modelli complessi post hoc.
Interpretabilità vs. Spiegabilità
- Interpretabilità: indica il grado in cui una persona può comprendere la causa di una decisione presa da un sistema di AI.
- Spiegabilità: va oltre, fornendo una descrizione esplicita dei fattori e delle logiche che hanno portato a una decisione.
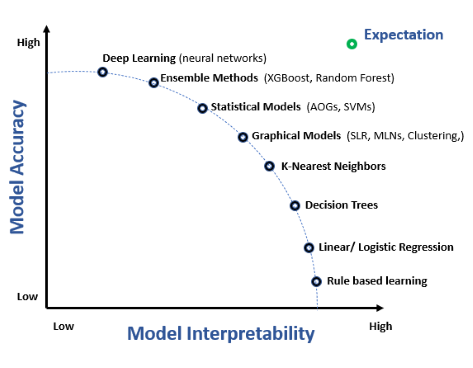
Sebbene i concetti siano correlati, l’interpretabilità si concentra sulla trasparenza del modello, mentre la spiegabilità sulla generazione di spiegazioni per l’output del modello.
Modelli Interpretabili
I modelli interpretabili sono intrinsecamente comprensibili. Esempi includono:
- Regressione Lineare: Modelli in cui la relazione tra le variabili di input e l’output è lineare, rendendo semplice interpretare i coefficienti come influenza di ciascuna caratteristica.
- Alberi Decisionali: Rappresentazioni visive delle decisioni, dove ogni nodo rappresenta una caratteristica e i rami corrispondono a regole decisionali.
- Sistemi Basati su Regole: Sistemi che utilizzano un insieme di regole comprensibili dall’uomo per prendere decisioni.
Questi modelli sacrificano parte della potenza predittiva in favore della trasparenza, ma sono preziosi quando la spiegabilità è fondamentale.
Spiegazioni Post-Hoc
Per modelli complessi come le reti neurali profonde, meno interpretabili, si usano spiegazioni post-hoc. Queste tecniche analizzano il comportamento del modello dopo che ha fatto una previsione.
Metodi Model-Agnostic
Questi metodi possono essere applicati a qualsiasi tipo di modello senza richiedere accesso alla sua struttura interna.
Local Interpretable Model-Agnostic Explanations (LIME)
LIME è una tecnica molto diffusa che spiega la previsione di qualsiasi classificatore approssimandolo localmente con un modello interpretabile. Per una data previsione, LIME perturba leggermente i dati di input e osserva le variazioni nell’output per determinare quali caratteristiche influenzano maggiormente la decisione.
SHapley Additive exPlanations (SHAP)
I valori SHAP si basano sulla teoria dei giochi cooperativi e forniscono una misura unificata dell’importanza delle caratteristiche. Quantificano il contributo di ciascuna caratteristica alla previsione, considerando tutte le possibili combinazioni di caratteristiche.
Spiegazioni Globali vs. Locali
- Spiegazioni Globali: Offrono una comprensione generale del comportamento del modello su tutti i dati.
- Spiegazioni Locali: Si concentrano su una singola previsione, spiegando perché il modello ha preso una specifica decisione per un caso individuale.
Ricerche sulla spiegabilità dell’AI
La spiegabilità dell’AI ha ricevuto molta attenzione man mano che questi sistemi si integrano nei processi decisionali umani. Ecco alcuni articoli scientifici recenti che affrontano questo tema fondamentale:
Explainable AI Improves Task Performance in Human-AI Collaboration (Pubblicato: 2024-06-12)
Autori: Julian Senoner, Simon Schallmoser, Bernhard Kratzwald, Stefan Feuerriegel, Torbjørn Netland
Questo articolo esplora l’impatto dell’AI spiegabile nel migliorare le prestazioni dei compiti durante la collaborazione uomo-AI. Gli autori sostengono che l’AI tradizionale opera come una scatola nera, rendendo difficile per le persone convalidare le previsioni AI rispetto alle proprie conoscenze. Introducendo l’AI spiegabile, in particolare tramite heatmap visive, lo studio ha riscontrato un miglioramento delle prestazioni. Sono stati condotti due esperimenti con operai di fabbrica e radiologi, dimostrando una significativa riduzione dei tassi di errore grazie all’uso di AI spiegabile. Questa ricerca sottolinea il potenziale dell’AI spiegabile nel migliorare l’accuratezza decisionale nei compiti reali. Leggi di più“Weak AI” is Likely to Never Become “Strong AI”, So What is its Greatest Value for Us? (Pubblicato: 2021-03-29)
Autore: Bin Liu
Questo articolo affronta le continue controversie sulle capacità e sul potenziale futuro dell’AI. Distingue tra “weak AI” e “strong AI” e sostiene che, sebbene la strong AI possa non essere raggiungibile, la weak AI ha un valore sostanziale. L’autore approfondisce i criteri per classificare la ricerca AI e discute le implicazioni sociali delle capacità attuali dell’AI. Il lavoro offre una prospettiva filosofica sul ruolo dell’AI nella società. Leggi di piùUnderstanding Mental Models of AI through Player-AI Interaction (Pubblicato: 2021-03-30)
Autori: Jennifer Villareale, Jichen Zhu
Questo studio indaga su come le persone sviluppano modelli mentali dei sistemi AI tramite l’interazione in giochi basati su AI. Gli autori propongono che tali interazioni offrano preziose informazioni sui modelli mentali degli utenti AI. Viene presentato un case study che evidenzia i vantaggi dell’utilizzo dei giochi per studiare la spiegabilità dell’AI, suggerendo che tali interazioni possono migliorare la comprensione dell’AI da parte degli utenti.From Explainable to Interactive AI: A Literature Review on Current Trends in Human-AI Interaction (Pubblicato: 2024-05-23)
Autori: Muhammad Raees, Inge Meijerink, Ioanna Lykourentzou, Vassilis-Javed Khan, Konstantinos Papangelis
Questa review esamina la transizione dall’AI spiegabile all’AI interattiva, sottolineando l’importanza del coinvolgimento umano nello sviluppo e nell’operatività dei sistemi AI. L’articolo analizza le tendenze attuali e le preoccupazioni sociali riguardo l’interazione uomo-AI, evidenziando la necessità di sistemi AI sia spiegabili che interattivi. Questa review fornisce una panoramica completa per la ricerca futura nel settore.
Domande frequenti
- Che cos’è la spiegabilità dell’AI?
La spiegabilità dell’AI è la capacità di comprendere e interpretare come i sistemi di intelligenza artificiale prendono decisioni e fanno previsioni. Rende i processi interni dell’AI trasparenti e aiuta gli utenti a fidarsi e a convalidare i risultati prodotti dall’AI.
- Perché la spiegabilità è importante nell’AI?
La spiegabilità garantisce che i sistemi di AI siano trasparenti, affidabili e conformi alle normative. Aiuta a identificare e ridurre i bias, migliora le prestazioni del modello e consente agli utenti di comprendere e fidarsi delle decisioni dell’AI, soprattutto in settori critici come sanità e finanza.
- Quali tecniche vengono utilizzate per ottenere la spiegabilità dell’AI?
Le tecniche più comuni includono modelli interpretabili (come la regressione lineare e gli alberi decisionali) e metodi di spiegazione post-hoc come LIME e SHAP, che forniscono approfondimenti sulle decisioni di modelli complessi.
- Qual è la differenza tra interpretabilità e spiegabilità?
L’interpretabilità si riferisce a quanto bene una persona può comprendere la causa di una decisione presa da un modello di AI. La spiegabilità va oltre, fornendo motivazioni dettagliate e contesto per gli output del modello, rendendo esplicite le ragioni alla base delle decisioni.
- In che modo la spiegabilità aiuta a ridurre i bias nell’AI?
La spiegabilità consente alle parti interessate di esaminare come i modelli di AI prendono decisioni, aiutando a identificare e affrontare eventuali bias presenti nei dati o nella logica del modello, garantendo così risultati più equi e imparziali.
Pronto a creare la tua AI?
Chatbot intelligenti e strumenti AI sotto lo stesso tetto. Collega blocchi intuitivi per trasformare le tue idee in Flussi automatizzati.
Scopri di più