Interpretabilità del Modello
L’interpretabilità del modello è la capacità di comprendere e fidarsi delle previsioni dell’IA, essenziale per trasparenza, conformità e mitigazione dei bias in settori come sanità e finanza.
Interpretabilità del Modello
L’interpretabilità del modello significa comprendere e fidarsi delle previsioni dell’IA, cruciale in ambiti come sanità e finanza. Comprende interpretabilità globale e locale, favorendo fiducia, conformità e mitigazione dei bias tramite metodi intrinseci e post-hoc.
L’interpretabilità del modello si riferisce alla capacità di comprendere, spiegare e fidarsi delle previsioni e delle decisioni prese dai modelli di machine learning. È un elemento critico nel campo dell’intelligenza artificiale, in particolare nelle applicazioni che implicano decisioni, come sanità, finanza e sistemi autonomi. Il concetto è centrale nella data science poiché colma il divario tra modelli computazionali complessi e comprensione umana.
Cos’è l’Interpretabilità del Modello?
L’interpretabilità del modello è il grado in cui una persona può prevedere costantemente i risultati del modello e comprendere la causa di una previsione. Implica la comprensione della relazione tra le caratteristiche in input e gli output prodotti dal modello, permettendo agli stakeholder di cogliere le ragioni di previsioni specifiche. Questa comprensione è fondamentale per costruire fiducia, garantire la conformità alle normative e guidare i processi decisionali.
Secondo il framework discusso da Lipton (2016) e Doshi-Velez & Kim (2017), l’interpretabilità include la capacità di valutare e ottenere informazioni dai modelli che il solo obiettivo finale non può fornire.
Interpretabilità Globale vs. Locale
L’interpretabilità del modello può essere suddivisa in due tipologie principali:
Interpretabilità Globale: Fornisce una comprensione generale di come funziona un modello, offrendo informazioni sul suo processo decisionale complessivo. Riguarda la comprensione della struttura del modello, dei suoi parametri e delle relazioni che apprende dal dataset. Questo tipo di interpretabilità è fondamentale per valutare il comportamento del modello su un ampio spettro di input.
Interpretabilità Locale: Si concentra sullo spiegare le singole previsioni, offrendo insight sul motivo per cui il modello ha preso una decisione specifica per un determinato caso. L’interpretabilità locale aiuta a comprendere il comportamento del modello in scenari particolari ed è essenziale per il debug e il perfezionamento dei modelli. Metodi come LIME e SHAP sono spesso utilizzati per ottenere interpretabilità locale, approssimando la frontiera decisionale del modello attorno a una specifica istanza.
Importanza dell’Interpretabilità del Modello
Fiducia e Trasparenza
I modelli interpretabili sono più propensi a essere considerati affidabili da utenti e stakeholder. La trasparenza su come un modello giunge alle sue decisioni è fondamentale, specialmente in settori come sanità o finanza dove le decisioni possono avere importanti implicazioni etiche e legali. L’interpretabilità facilita la comprensione e il debug, garantendo che i modelli possano essere utilizzati con fiducia nei processi decisionali critici.
Sicurezza e Conformità Normativa
In contesti ad alto rischio come la diagnostica medica o la guida autonoma, l’interpretabilità è necessaria per garantire la sicurezza e rispettare gli standard normativi. Ad esempio, il Regolamento Generale sulla Protezione dei Dati (GDPR) nell’Unione Europea impone che gli individui abbiano diritto a una spiegazione delle decisioni algoritmiche che li riguardano significativamente. L’interpretabilità del modello aiuta le organizzazioni a rispettare tali normative fornendo spiegazioni chiare degli output algoritmici.
Individuazione e Mitigazione dei Bias
L’interpretabilità è fondamentale per identificare e mitigare i bias nei modelli di machine learning. I modelli addestrati su dati distorti possono apprendere e propagare inconsapevolmente bias sociali. Comprendendo il processo decisionale, i professionisti possono individuare le feature responsabili del bias e adattare i modelli di conseguenza, favorendo equità e uguaglianza nei sistemi IA.
Debug e Miglioramento dei Modelli
I modelli interpretabili facilitano il debug perché consentono ai data scientist di comprendere e correggere errori nelle previsioni. Questa comprensione può condurre a miglioramenti ed evoluzioni del modello, garantendo prestazioni e accuratezza superiori. L’interpretabilità aiuta a scoprire le ragioni sottostanti errori o comportamenti inattesi, guidando lo sviluppo successivo.
Metodi per Ottenere Interpretabilità
Esistono diverse tecniche e approcci per aumentare l’interpretabilità del modello, che si dividono in due categorie principali: metodi intrinseci e post-hoc.
Interpretabilità Intrinseca
Prevede l’uso di modelli intrinsecamente interpretabili grazie alla loro semplicità e trasparenza. Esempi includono:
- Regressione Lineare: Offre insight immediati su come le feature in input influenzano le previsioni, rendendola facile da comprendere e analizzare.
- Alberi Decisionali: Forniscono una rappresentazione visiva e logica delle decisioni, risultando semplici da interpretare e comunicare agli stakeholder.
- Modelli Basati su Regole: Utilizzano insiemi di regole per prendere decisioni, facilmente analizzabili e comprensibili, offrendo chiarezza sul processo decisionale.
Interpretabilità Post-hoc
Questi metodi si applicano a modelli complessi dopo l’addestramento per renderli più interpretabili:
- LIME (Local Interpretable Model-agnostic Explanations): Fornisce spiegazioni locali approssimando le previsioni del modello con modelli interpretabili attorno all’istanza di interesse, aiutando a comprendere previsioni specifiche.
- SHAP (SHapley Additive exPlanations): Offre una misura unificata dell’importanza delle feature considerando il contributo di ciascuna caratteristica alla previsione, fornendo insight sul processo decisionale del modello.
- Partial Dependence Plots (PDPs): Visualizzano la relazione tra una feature e l’output previsto, marginalizzando sulle altre, permettendo di capire l’effetto delle feature.
- Mappe di Salienza: Evidenziano le aree degli input che più influenzano le previsioni, spesso usate nell’elaborazione di immagini per capire dove si concentra il modello.
Casi d’Uso dell’Interpretabilità del Modello
Sanità
Nella diagnostica medica, l’interpretabilità è cruciale per validare le previsioni dell’IA e garantire che siano in linea con le conoscenze cliniche. I modelli utilizzati nella diagnosi di patologie o nella raccomandazione di trattamenti devono essere interpretabili per ottenere la fiducia di medici e pazienti, favorendo migliori risultati sanitari.
Finanza
Le istituzioni finanziarie impiegano il machine learning per credit scoring, rilevamento frodi e valutazione del rischio. L’interpretabilità garantisce la conformità normativa e aiuta a comprendere le decisioni finanziarie, facilitando la loro giustificazione verso stakeholder e regolatori. Questo è essenziale per mantenere fiducia e trasparenza nelle operazioni finanziarie.
Sistemi Autonomi
Nei veicoli autonomi e nella robotica, l’interpretabilità è fondamentale per sicurezza e affidabilità. Comprendere il processo decisionale dei sistemi IA aiuta a prevederne il comportamento in situazioni reali e assicura che operino entro limiti etici e legali, aspetto essenziale per sicurezza pubblica e fiducia.
Automazione IA e Chatbot
Nell’automazione IA e nei chatbot, l’interpretabilità aiuta a perfezionare i modelli conversazionali e garantire che forniscano risposte rilevanti e accurate. Facilita la comprensione della logica dietro le interazioni del chatbot e migliora la soddisfazione dell’utente, potenziando l’esperienza complessiva.
Sfide e Limiti
Compromesso tra Interpretabilità e Accuratezza
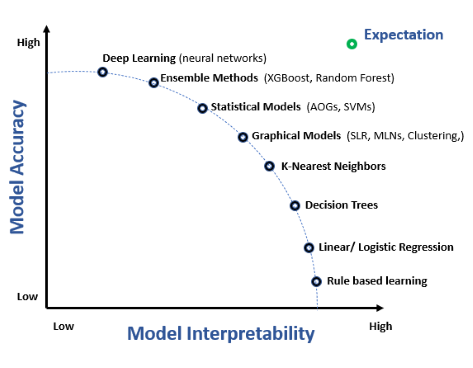
Spesso c’è un compromesso tra interpretabilità e accuratezza del modello. Modelli complessi come le reti neurali profonde possono offrire maggiore accuratezza ma risultano meno interpretabili. Raggiungere il giusto equilibrio è una sfida significativa, che richiede attenzione alle esigenze applicative e alle aspettative degli stakeholder.
Interpretabilità Specifica per il Dominio
Il livello di interpretabilità richiesto può variare notevolmente tra domini e applicazioni. I modelli devono essere adattati alle esigenze specifiche del dominio per offrire insight significativi e azionabili. Ciò implica conoscere le sfide proprie del settore e progettare modelli che le affrontino efficacemente.
Valutazione dell’Interpretabilità
Misurare l’interpretabilità è difficile perché soggettiva e dipendente dal contesto. Alcuni modelli possono risultare interpretabili per esperti, ma non per profani. Sviluppare metriche standardizzate per valutare l’interpretabilità è un’area di ricerca attiva, cruciale per l’avanzamento del settore e la diffusione di modelli interpretabili.
Ricerca sull’Interpretabilità del Modello
L’interpretabilità del modello è un tema centrale nel machine learning poiché consente di comprendere e fidarsi dei modelli predittivi, in particolare in campi come la medicina di precisione e i sistemi decisionali automatizzati. Ecco alcuni studi significativi su questo tema:
Hybrid Predictive Model: When an Interpretable Model Collaborates with a Black-box Model
Autori: Tong Wang, Qihang Lin (Pubblicato: 10-05-2019)
Questo articolo introduce un framework per la creazione di un Hybrid Predictive Model (HPM) che combina i punti di forza di modelli interpretabili e black-box. Il modello ibrido sostituisce il black-box per parti dei dati dove non è necessaria alta performance, aumentando la trasparenza con una minima perdita di accuratezza. Gli autori propongono una funzione obiettivo che bilancia accuratezza predittiva, interpretabilità e trasparenza. Lo studio dimostra l’efficacia del modello ibrido nell’equilibrare trasparenza e prestazioni, soprattutto con dati strutturati e testuali. Leggi di piùMachine Learning Model Interpretability for Precision Medicine
Autori: Gajendra Jung Katuwal, Robert Chen (Pubblicato: 28-10-2016)
Questa ricerca evidenzia l’importanza dell’interpretabilità nei modelli di machine learning per la medicina di precisione. Si utilizza l’algoritmo Model-Agnostic Explanations per rendere interpretabili modelli complessi come le random forest. Lo studio applica questo approccio al dataset MIMIC-II, prevedendo la mortalità in terapia intensiva con una accuratezza bilanciata dell’80% e chiarendo l’impatto delle singole feature, cruciale per le decisioni mediche. Leggi di piùThe Definitions of Interpretability and Learning of Interpretable Models
Autori: Weishen Pan, Changshui Zhang (Pubblicato: 29-05-2021)
Il lavoro propone una nuova definizione matematica dell’interpretabilità nei modelli di machine learning. Si definisce l’interpretabilità in termini di sistemi di riconoscimento umano e si introduce un framework per addestrare modelli completamente interpretabili per l’uomo. Lo studio mostra che questi modelli non solo forniscono processi decisionali trasparenti, ma sono anche più robusti contro attacchi avversari. Leggi di più
Domande frequenti
- Cosa si intende per interpretabilità del modello nel machine learning?
L’interpretabilità del modello è il grado in cui una persona può prevedere e comprendere costantemente i risultati di un modello, spiegando come le caratteristiche in input si collegano agli output e perché il modello prende determinate decisioni.
- Perché l’interpretabilità del modello è importante?
L’interpretabilità costruisce fiducia, assicura la conformità normativa, aiuta a individuare bias e facilita il debug e il miglioramento dei modelli IA, soprattutto in settori sensibili come sanità e finanza.
- Cosa sono i metodi di interpretabilità intrinseca e post-hoc?
I metodi intrinseci utilizzano modelli semplici e trasparenti come la regressione lineare o gli alberi decisionali, interpretabili per progettazione. I metodi post-hoc, come LIME e SHAP, aiutano a spiegare modelli complessi dopo l’addestramento approssimando o evidenziando le caratteristiche più importanti.
- Quali sono alcune sfide nel raggiungere l’interpretabilità del modello?
Le sfide includono il bilanciamento tra accuratezza e trasparenza, requisiti specifici del dominio e la natura soggettiva della misurazione dell’interpretabilità, oltre allo sviluppo di metriche di valutazione standardizzate.
Pronto a creare la tua IA?
Chatbot intelligenti e strumenti IA sotto lo stesso tetto. Collega blocchi intuitivi per trasformare le tue idee in Flows automatizzati.