Naive Bayes
Naive Bayes è una famiglia di algoritmi di classificazione semplice ma potente che sfrutta il Teorema di Bayes, comunemente utilizzata per attività scalabili come il rilevamento dello spam e la classificazione del testo.
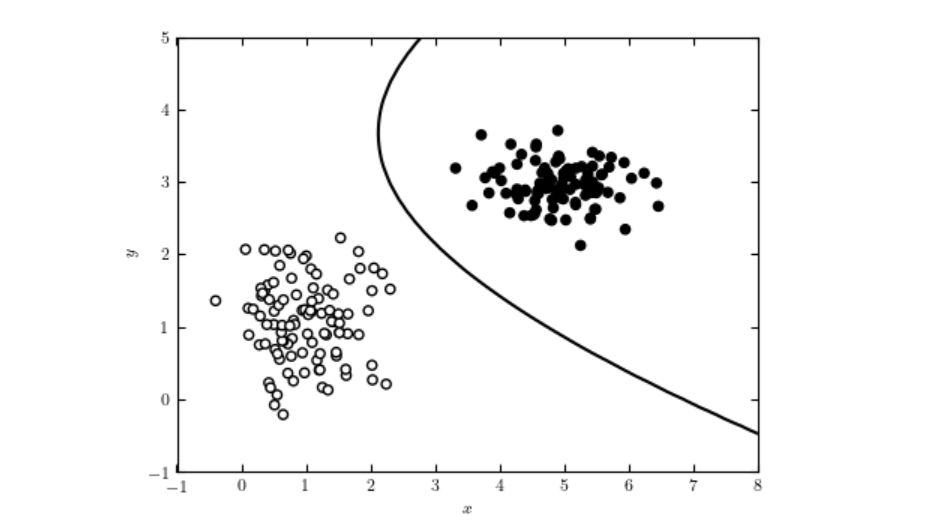
Naive Bayes
Naive Bayes è una famiglia di algoritmi di classificazione semplici ed efficaci basati sul Teorema di Bayes, che assume l’indipendenza condizionata tra le caratteristiche. È ampiamente utilizzato per il rilevamento dello spam, la classificazione del testo e molto altro grazie alla sua semplicità e scalabilità.
Naive Bayes è una famiglia di algoritmi di classificazione basati sul Teorema di Bayes, che applica il principio della probabilità condizionata. Il termine “naive” si riferisce all’assunzione semplificata che tutte le caratteristiche di un dataset siano condizionatamente indipendenti tra loro dato l’etichetta di classe. Nonostante questa assunzione sia spesso violata nei dati reali, i classificatori Naive Bayes sono riconosciuti per la loro semplicità ed efficacia in varie applicazioni, come la classificazione del testo e il rilevamento dello spam.
Concetti Chiave
Teorema di Bayes
Questo teorema costituisce la base del Naive Bayes, fornendo un metodo per aggiornare la stima di probabilità di un’ipotesi man mano che si raccolgono nuove evidenze o informazioni. Matematicamente, è espresso come:![Bayes Theorem Formula]()
dove ( P(A|B) ) è la probabilità a posteriori, ( P(B|A) ) è la verosimiglianza, ( P(A) ) è la probabilità a priori e ( P(B) ) è l’evidenza.
Indipendenza Condizionata
L’assunzione ingenua che ogni caratteristica sia indipendente dalle altre dato l’etichetta di classe. Questa assunzione semplifica i calcoli e permette all’algoritmo di scalare bene su grandi dataset.Probabilità a Posteriori
La probabilità dell’etichetta di classe dato i valori delle caratteristiche, calcolata usando il Teorema di Bayes. Questo è l’elemento centrale nelle previsioni con Naive Bayes.Tipi di Classificatori Naive Bayes
- Gaussian Naive Bayes: Presuppone che le caratteristiche continue seguano una distribuzione gaussiana.
- Multinomial Naive Bayes: Adatto per dati discreti, spesso usato per la classificazione del testo dove i dati possono essere rappresentati come conteggi di parole.
- Bernoulli Naive Bayes: Utilizzato per caratteristiche binarie/booleane, come la presenza o assenza di una parola specifica nella classificazione del testo.

Come Funziona
I classificatori Naive Bayes lavorano calcolando la probabilità a posteriori per ciascuna classe dato un insieme di caratteristiche e selezionando la classe con la probabilità a posteriori più alta. Il processo si articola nei seguenti passaggi:
- Fase di Addestramento: Calcolare la probabilità a priori di ciascuna classe e la verosimiglianza di ogni caratteristica dato ciascuna classe utilizzando i dati di addestramento.
- Fase di Predizione: Per una nuova istanza, calcolare la probabilità a posteriori di ciascuna classe utilizzando le probabilità a priori e le verosimiglianze ottenute nella fase di addestramento. Assegnare all’istanza la classe con la probabilità a posteriori più alta.
Applicazioni
I classificatori Naive Bayes sono particolarmente efficaci nelle seguenti applicazioni:
- Filtro Antispam: Classificare le email come spam o non spam in base alla frequenza di determinate parole.
- Classificazione del Testo: Categorizzare documenti in classi predefinite in base alla frequenza o presenza di parole.
- Analisi del Sentiment: Analizzare un testo per determinare il sentimento, come positivo, negativo o neutro.
- Sistemi di Raccomandazione: Utilizzare tecniche di collaborative filtering per suggerire prodotti o contenuti agli utenti in base ai comportamenti passati.
Vantaggi
- Semplicità ed Efficienza: Naive Bayes è facile da implementare ed efficiente dal punto di vista computazionale, rendendolo adatto a grandi dataset.
- Scalabilità: L’algoritmo scala bene con il numero di caratteristiche e di dati.
- Gestione di Alta Dimensionalità: Ottiene buone prestazioni con un gran numero di caratteristiche, come nella classificazione del testo dove ogni parola è una caratteristica.
Svantaggi
- Assunzione di Indipendenza: L’assunzione di indipendenza delle caratteristiche può portare a stime di probabilità imprecise quando le caratteristiche sono correlate.
- Frequenza Zero: Se un valore di una caratteristica non è stato osservato nel set di addestramento, il modello assegnerà probabilità zero alla classe corrispondente, problema mitigabile con tecniche come la Laplace smoothing.
Esempio d’Uso
Consideriamo un’applicazione di filtro antispam che utilizza Naive Bayes. I dati di addestramento consistono in email etichettate come “spam” o “non spam”. Ogni email è rappresentata da un insieme di caratteristiche, come la presenza di parole specifiche. Durante l’addestramento, l’algoritmo calcola la probabilità di ciascuna parola dato l’etichetta di classe. Per una nuova email, l’algoritmo calcola la probabilità a posteriori per “spam” e “non spam” e assegna l’etichetta con probabilità maggiore.
Connessione con AI e Chatbot
I classificatori Naive Bayes possono essere integrati nei sistemi di intelligenza artificiale e nei chatbot per potenziare le capacità di elaborazione del linguaggio naturale e migliorare l’interazione uomo-macchina. Ad esempio, possono essere utilizzati per individuare l’intento nelle richieste degli utenti, classificare testi in categorie predefinite o filtrare contenuti inappropriati. Questa funzionalità migliora la qualità e la pertinenza delle soluzioni AI. Inoltre, l’efficienza dell’algoritmo lo rende adatto per applicazioni in tempo reale, un aspetto importante per l’automazione AI e i sistemi chatbot.
Ricerca
Naive Bayes è una famiglia di algoritmi probabilistici semplici ma potenti basati sull’applicazione del teorema di Bayes con l’ipotesi forte di indipendenza tra le caratteristiche. È ampiamente utilizzato per compiti di classificazione grazie alla sua semplicità ed efficacia. Ecco alcuni articoli scientifici che trattano varie applicazioni e miglioramenti del classificatore Naive Bayes:
Migliorare il filtro antispam combinando Naive Bayes con semplici ricerche k-nearest neighbor
Autore: Daniel Etzold
Pubblicato: 30 novembre 2003
Questo articolo esplora l’uso di Naive Bayes per la classificazione delle email, evidenziando la facilità di implementazione e l’efficienza. Lo studio presenta risultati empirici che mostrano come la combinazione di Naive Bayes con ricerche k-nearest neighbor possa migliorare l’accuratezza del filtro antispam. La combinazione ha fornito lievi miglioramenti con molte caratteristiche e miglioramenti significativi con meno caratteristiche. Leggi l’articolo.Naive Bayes Localmente Ponderato
Autori: Eibe Frank, Mark Hall, Bernhard Pfahringer
Pubblicato: 19 ottobre 2012
Questo articolo affronta la principale debolezza del Naive Bayes, ovvero l’assunzione di indipendenza tra gli attributi. Introduce una versione localmente ponderata di Naive Bayes che apprende modelli locali al momento della previsione, rilassando così l’assunzione di indipendenza. I risultati sperimentali dimostrano che questo approccio raramente peggiora l’accuratezza e spesso la migliora sensibilmente. Il metodo è apprezzato per la sua semplicità concettuale e computazionale rispetto ad altre tecniche. Leggi l’articolo.Rilevamento di Intrappolamento nei Rover Planetari con Naive Bayes
Autore: Dicong Qiu
Pubblicato: 31 gennaio 2018
In questo studio viene discussa l’applicazione dei classificatori Naive Bayes per il rilevamento di intrappolamenti nei rover planetari. Vengono definiti i criteri di intrappolamento e dimostrato l’uso di Naive Bayes nel rilevare tali situazioni. L’articolo descrive esperimenti condotti con i rover AutoKrawler, fornendo spunti sull’efficacia di Naive Bayes per procedure di salvataggio autonome. Leggi l’articolo.
Domande frequenti
- Cos'è il Naive Bayes?
Naive Bayes è una famiglia di algoritmi di classificazione basati sul Teorema di Bayes, che assume che tutte le caratteristiche siano condizionatamente indipendenti dato l’etichetta di classe. È ampiamente utilizzato per la classificazione del testo, il filtro antispam e l’analisi del sentiment.
- Quali sono i principali tipi di classificatori Naive Bayes?
I principali tipi sono Gaussian Naive Bayes (per caratteristiche continue), Multinomial Naive Bayes (per caratteristiche discrete come la frequenza delle parole) e Bernoulli Naive Bayes (per caratteristiche binarie/booleane).
- Quali sono i vantaggi del Naive Bayes?
Naive Bayes è semplice da implementare, computazionalmente efficiente, scalabile per grandi dataset e gestisce bene dati ad alta dimensionalità.
- Quali sono le limitazioni del Naive Bayes?
La principale limitazione è l’assunzione di indipendenza delle caratteristiche, che spesso non è vera nei dati reali. Inoltre, può assegnare probabilità zero a caratteristiche mai viste, il che può essere mitigato con tecniche come la Laplace smoothing.
- Dove viene utilizzato il Naive Bayes nell’AI e nei chatbot?
Naive Bayes viene utilizzato nei sistemi di intelligenza artificiale e nei chatbot per il rilevamento dell’intento, la classificazione del testo, il filtro antispam e l’analisi del sentiment, migliorando le capacità di elaborazione del linguaggio naturale e consentendo decisioni in tempo reale.
Pronto a creare la tua AI?
Chatbot intelligenti e strumenti AI sotto lo stesso tetto. Collega blocchi intuitivi per trasformare le tue idee in Flussi automatizzati.