Risposta alle Domande
La Risposta alle Domande con RAG potenzia gli LLM integrando il recupero dati in tempo reale e la generazione di linguaggio naturale per risposte accurate e contestualmente pertinenti.
Risposta alle Domande
La Risposta alle Domande con Retrieval-Augmented Generation (RAG) potenzia i modelli linguistici integrando dati esterni in tempo reale per risposte accurate e pertinenti. Ottimizza le prestazioni in campi dinamici, offrendo maggiore precisione, contenuti dinamici e pertinenza migliorata.
La Risposta alle Domande con Retrieval-Augmented Generation (RAG) è un metodo innovativo che combina i punti di forza del recupero delle informazioni e della generazione di linguaggio naturale per creare testo umano partendo dai dati, migliorando l’IA, i chatbot, i report e personalizzando le esperienze. Questo approccio ibrido potenzia le capacità dei grandi modelli linguistici (LLM) integrando alle loro risposte informazioni pertinenti e aggiornate recuperate da fonti di dati esterne. A differenza dei metodi tradizionali che si basano solo su modelli pre-addestrati, la RAG integra dinamicamente dati esterni, consentendo ai sistemi di fornire risposte più accurate e contestualmente rilevanti, in particolare in ambiti che richiedono informazioni aggiornate o conoscenze specialistiche.
La RAG ottimizza le prestazioni degli LLM assicurando che le risposte non siano generate solo da un dataset interno, ma siano anche informate da fonti autorevoli e in tempo reale. Questo approccio è cruciale per attività di risposta alle domande in settori dinamici dove le informazioni sono in continua evoluzione.
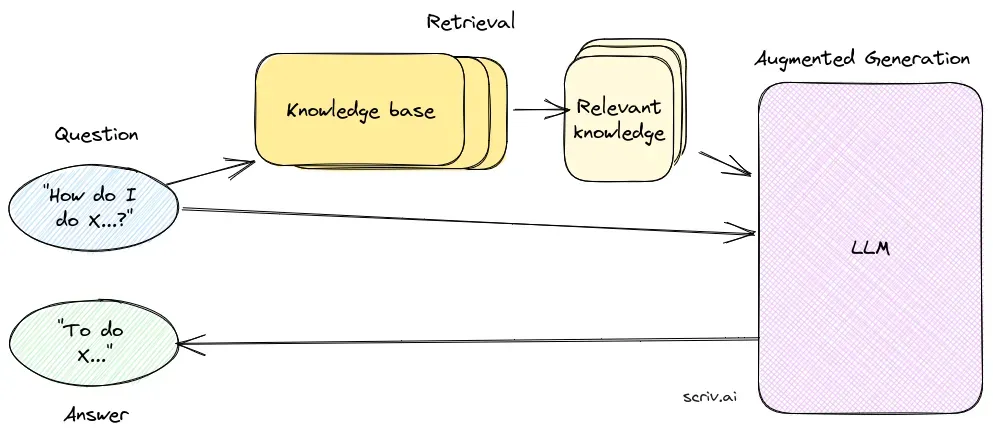
Componenti Fondamentali della RAG
1. Componente di Recupero
Il componente di recupero è responsabile della ricerca di informazioni pertinenti da vasti dataset, solitamente archiviati in un database vettoriale. Questo componente utilizza tecniche di ricerca semantica per individuare ed estrarre segmenti di testo o documenti altamente pertinenti alla query dell’utente.
- Database Vettoriale: Un database specializzato che archivia rappresentazioni vettoriali dei documenti. Questi embedding facilitano la ricerca e il recupero efficienti abbinando il significato semantico della query dell’utente ai segmenti di testo pertinenti.
- Ricerca Semantica: Utilizza embedding vettoriali per trovare documenti in base a similarità semantiche piuttosto che al semplice abbinamento di parole chiave, migliorando la pertinenza e la precisione delle informazioni recuperate.
2. Componente di Generazione
Il componente di generazione, solitamente un LLM come GPT-3 o BERT, sintetizza una risposta combinando la query originale dell’utente con il contesto recuperato. Questo componente è fondamentale per generare risposte coerenti e contestualmente appropriate.
- Modelli Linguistici (LLM): Addestrati per generare testo a partire da prompt di input, gli LLM nei sistemi RAG utilizzano i documenti recuperati come contesto per aumentare la qualità e la pertinenza delle risposte generate.
Workflow di un Sistema RAG
- Preparazione dei Documenti: Il sistema inizia caricando un ampio corpus di documenti, convertendoli in un formato adatto all’analisi. Spesso ciò implica la suddivisione dei documenti in blocchi più piccoli e gestibili.
- Vector Embedding: Ogni blocco di documento viene trasformato in una rappresentazione vettoriale tramite embedding generati da modelli linguistici. Questi vettori sono archiviati in un database vettoriale per facilitare il recupero efficiente.
- Elaborazione della Query: Al ricevimento di una query dell’utente, il sistema converte la query in un vettore ed esegue una ricerca di similarità nel database vettoriale per identificare i blocchi di documento pertinenti.
- Generazione Contestuale della Risposta: I blocchi di documento recuperati vengono combinati con la query dell’utente e passati all’LLM, che genera una risposta finale arricchita dal contesto.
- Output: Il sistema fornisce una risposta accurata e pertinente alla query, arricchita da informazioni contestualmente appropriate.
Vantaggi della RAG
- Maggiore Precisione: Recuperando il contesto pertinente, la RAG riduce il rischio di generare risposte errate o obsolete, un problema comune agli LLM standalone.
- Contenuti Dinamici: I sistemi RAG possono integrare le informazioni più recenti da basi di conoscenza aggiornate, rendendoli ideali per ambiti che richiedono dati attuali.
- Pertinenza Migliorata: Il processo di recupero garantisce che le risposte generate siano adattate al contesto specifico della query, migliorando qualità e pertinenza della risposta.
Casi d’Uso
- Chatbot e Assistenti Virtuali: I sistemi potenziati dalla RAG migliorano chatbot e assistenti virtuali fornendo risposte accurate e contestuali, aumentando l’interazione e la soddisfazione dell’utente.
- Supporto Clienti: Nelle applicazioni di supporto clienti, i sistemi RAG possono recuperare documenti di policy o informazioni di prodotto rilevanti per offrire risposte precise alle domande degli utenti.
- Creazione di Contenuti: I modelli RAG possono generare documenti e report integrando le informazioni recuperate, risultando utili per attività di generazione automatica di contenuti.
- Strumenti Educativi: In ambito educativo, i sistemi RAG possono alimentare assistenti didattici che forniscono spiegazioni e riassunti basati sui contenuti didattici più recenti.
Implementazione Tecnica
L’implementazione di un sistema RAG coinvolge diversi passaggi tecnici:
- Archiviazione e Recupero Vettoriale: Utilizza database vettoriali come Pinecone o FAISS per archiviare e recuperare efficientemente gli embedding dei documenti.
- Integrazione del Modello Linguistico: Integra LLM come GPT-3 o modelli personalizzati tramite framework come HuggingFace Transformers per gestire la generazione.
- Configurazione della Pipeline: Prepara una pipeline che gestisca il flusso dal recupero dei documenti fino alla generazione della risposta, assicurando un’integrazione fluida di tutti i componenti.
Sfide e Considerazioni
- Gestione di Costi e Risorse: I sistemi RAG possono essere ad alto consumo di risorse e richiedono ottimizzazione per gestire efficacemente i costi computazionali.
- Accuratezza Fattuale: È fondamentale assicurare che le informazioni recuperate siano accurate e aggiornate per evitare la generazione di risposte fuorvianti.
- Complessità nella Configurazione: Il setup iniziale dei sistemi RAG può essere complesso, coinvolgendo molteplici componenti che necessitano di integrazione e ottimizzazione accurata.
Ricerche sulla Risposta alle Domande con Retrieval-Augmented Generation (RAG)
La Retrieval-Augmented Generation (RAG) è un metodo che potenzia i sistemi di risposta alle domande combinando meccanismi di recupero con modelli generativi. Le ricerche recenti hanno esplorato l’efficacia e l’ottimizzazione della RAG in vari contesti.
- In Defense of RAG in the Era of Long-Context Language Models: Questo articolo sostiene la continua rilevanza della RAG nonostante l’emergere di modelli linguistici a lungo contesto, che integrano sequenze di testo più lunghe nell’elaborazione. Gli autori propongono un meccanismo Order-Preserve Retrieval-Augmented Generation (OP-RAG) che ottimizza le prestazioni della RAG nella gestione di task di risposta alle domande su lungo contesto. Dimostrano, tramite esperimenti, che OP-RAG può raggiungere elevata qualità delle risposte utilizzando meno token rispetto ai modelli long-context. Leggi di più.
- CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems: Questo studio introduce ClapNQ, un dataset di benchmark progettato per valutare i sistemi RAG nella generazione di risposte coese di lunga forma. Il dataset si concentra su risposte ancorate a passaggi specifici, senza allucinazioni, e incoraggia i modelli RAG ad adattarsi a formati di risposta concisi e coesi. Gli autori forniscono esperimenti di base che evidenziano possibili aree di miglioramento nei sistemi RAG. Leggi di più.
- Optimizing Retrieval-Augmented Generation with Elasticsearch for Enhanced Question-Answering Systems: La ricerca integra Elasticsearch nel framework RAG per aumentare efficienza e precisione dei sistemi di risposta alle domande. Utilizzando lo Stanford Question Answering Dataset (SQuAD) versione 2.0, lo studio confronta vari metodi di recupero e evidenzia i vantaggi dello schema ES-RAG in termini di efficienza e precisione, superando altri metodi di 0,51 punti percentuali. L’articolo suggerisce ulteriori esplorazioni dell’interazione tra Elasticsearch e i modelli linguistici per migliorare le risposte del sistema. Leggi di più.
Domande frequenti
- Che cos'è la Retrieval-Augmented Generation (RAG) nella Risposta alle Domande?
La RAG è un metodo che combina il recupero delle informazioni e la generazione di linguaggio naturale per fornire risposte accurate e aggiornate, integrando fonti di dati esterne nei grandi modelli linguistici.
- Quali sono i principali componenti di un sistema RAG?
Un sistema RAG è composto da un componente di recupero, che reperisce informazioni rilevanti da database vettoriali tramite ricerca semantica, e da un componente di generazione, solitamente un LLM, che sintetizza le risposte utilizzando sia la query utente che il contesto recuperato.
- Quali sono i vantaggi dell'utilizzo della RAG per la risposta alle domande?
La RAG migliora la precisione recuperando informazioni contestualmente pertinenti, supporta aggiornamenti dinamici dei contenuti da basi di conoscenza esterne e aumenta la pertinenza e la qualità delle risposte generate.
- Quali sono gli usi comuni della risposta alle domande basata su RAG?
Gli usi comuni includono chatbot IA, supporto clienti, creazione automatica di contenuti e strumenti educativi che richiedono risposte accurate, contestuali e aggiornate.
- Quali sfide devono essere considerate nell'implementazione della RAG?
I sistemi RAG possono essere ad alta intensità di risorse, richiedono un'integrazione attenta per prestazioni ottimali e devono garantire l'accuratezza delle informazioni recuperate per evitare risposte fuorvianti o obsolete.
Inizia a Creare Risposte alle Domande Potenziate dall'IA
Scopri come la Retrieval-Augmented Generation può migliorare il tuo chatbot e le soluzioni di supporto con risposte accurate e in tempo reale.
Scopri di più

