SpaCy
spaCy è una libreria NLP veloce ed efficiente in Python, ideale per la produzione con funzionalità come tokenizzazione, POS tagging e riconoscimento di entità.
spaCy è una solida libreria open-source pensata per l’elaborazione avanzata del linguaggio naturale (NLP) in Python. Rilasciata nel 2015 da Matthew Honnibal e Ines Montani, è mantenuta da Explosion AI. spaCy è apprezzata per efficienza, facilità d’uso e supporto NLP completo, rendendola la scelta preferita in produzione rispetto a librerie orientate alla ricerca come NLTK. Implementata in Python e Cython, garantisce un’elaborazione del testo rapida ed efficace.
Storia e Confronto con Altre Librerie NLP
spaCy è emersa come un’alternativa potente alle altre librerie NLP grazie a velocità e accuratezza di livello industriale. Mentre NLTK offre un approccio algoritmico flessibile adatto a ricerca ed educazione, spaCy è pensata per una rapida implementazione in ambienti di produzione con modelli pre-addestrati per un’integrazione senza soluzione di continuità. spaCy fornisce un’API user-friendly, ideale per gestire grandi dataset in modo efficiente, risultando adatta ad applicazioni commerciali. I confronti con altre librerie, come Spark NLP e Stanford CoreNLP, spesso mettono in luce la velocità e la facilità d’uso di spaCy, posizionandola come scelta ottimale per gli sviluppatori che necessitano di soluzioni robuste e pronte per la produzione.
Funzionalità Chiave di spaCy
Tokenizzazione
Segmenta il testo in parole, segni di punteggiatura, ecc., mantenendo la struttura originale del testo—fondamentale per le attività NLP.POS tagging (Part-of-Speech Tagging)
Assegna tipologie di parole ai token come nomi e verbi, offrendo informazioni sulla struttura grammaticale del testo.Dependency Parsing
Analizza la struttura della frase stabilendo relazioni tra le parole, identificando funzioni sintattiche come soggetto o oggetto.Riconoscimento di Entità Nominate (NER)
Identifica e categorizza entità nominate nel testo, come persone, organizzazioni e luoghi, essenziale per l’estrazione di informazioni.Classificazione del Testo
Categoriza documenti o parti di documenti, facilitando l’organizzazione e il recupero delle informazioni.Similarità
Misura la similarità tra parole, frasi o documenti utilizzando word vector.Matching Basato su Regole
Trova sequenze di token in base al testo e alle annotazioni linguistiche, simile alle espressioni regolari.Apprendimento Multi-task con Transformer
Integra modelli basati su transformer come BERT, migliorando accuratezza e performance nelle attività NLP.Strumenti di Visualizzazione
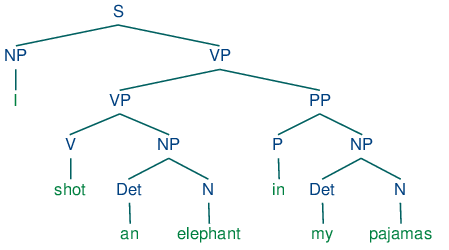
Include displaCy, uno strumento per visualizzare la sintassi e le entità nominate, migliorando l’interpretabilità dell’analisi NLP.Pipeline Personalizzabili
Consente agli utenti di personalizzare i flussi di lavoro NLP aggiungendo o modificando componenti nella pipeline di elaborazione.
Casi d’Uso
Data Science e Machine Learning
spaCy è preziosa nella data science per il pre-processing del testo, l’estrazione di feature e l’addestramento dei modelli. L’integrazione con framework come TensorFlow e PyTorch è fondamentale per sviluppare e distribuire modelli NLP. Ad esempio, spaCy può pre-processare i dati testuali tramite tokenizzazione, normalizzazione ed estrazione di feature come le entità nominate, che possono poi essere usate per analisi del sentiment o classificazione del testo.
Chatbot e Assistenti AI
Le capacità di comprensione del linguaggio naturale di spaCy la rendono ideale per lo sviluppo di chatbot e assistenti AI. Gestisce attività come il riconoscimento delle intenzioni e l’estrazione di entità, fondamentali per la creazione di sistemi conversazionali. Ad esempio, un chatbot che utilizza spaCy può comprendere le richieste degli utenti identificando intenzioni ed estraendo le entità rilevanti, permettendogli di generare risposte appropriate.
Estrazione di Informazioni e Analisi del Testo
Ampio l’uso di spaCy per estrarre informazioni strutturate da testo non strutturato, categorizzando entità, relazioni ed eventi. Questo è utile in applicazioni come l’analisi dei documenti e l’estrazione di conoscenza. Ad esempio, nell’analisi di documenti legali, spaCy può estrarre informazioni chiave come le parti coinvolte e i termini legali, automatizzando la revisione dei documenti e aumentando l’efficienza dei flussi di lavoro.
Ricerca e Applicazioni Accademiche
Le complete capacità NLP di spaCy la rendono uno strumento prezioso per la ricerca e l’accademia. I ricercatori possono esplorare pattern linguistici, analizzare corpora testuali e sviluppare modelli NLP specifici per dominio. Ad esempio, spaCy può essere utilizzata in uno studio linguistico per identificare pattern d’uso del linguaggio in diversi contesti.
Esempi di Utilizzo di spaCy
Riconoscimento di Entità Nominate
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("Apple is looking at buying U.K. startup for $1 billion") for ent in doc.ents: print(ent.text, ent.label_) # Output: Apple ORG, U.K. GPE, $1 billion MONEYDependency Parsing
for token in doc: print(token.text, token.dep_, token.head.text) # Output: Apple nsubj looking, is aux looking, looking ROOT looking, ...Classificazione del Testo
spaCy può essere estesa con modelli personalizzati di classificazione del testo per categorizzare il testo in base a etichette predefinite.
Packaging e Deployment dei Modelli
spaCy offre strumenti robusti per il packaging e la distribuzione di modelli NLP, assicurando prontezza per la produzione e integrazione semplificata nei sistemi esistenti. Questo include supporto per versioning dei modelli, gestione delle dipendenze e automazione dei flussi di lavoro.
Ricerca su SpaCy e Tematiche Correlate
SpaCy è una libreria open-source ampiamente utilizzata in Python per l’elaborazione avanzata del linguaggio naturale (NLP). È pensata per l’uso in produzione e supporta vari task NLP come tokenizzazione, POS tagging e riconoscimento di entità nominate. Recenti pubblicazioni scientifiche ne evidenziano applicazioni, miglioramenti e confronti con altri strumenti NLP, accrescendo la comprensione delle sue capacità e implementazioni.
Articoli Scientifici Selezionati
| Titolo | Autori | Pubblicato | Sintesi | Link |
|---|---|---|---|---|
| Multi hash embeddings in spaCy | Lester James Miranda, Ákos Kádár, Adriane Boyd, Sofie Van Landeghem, Anders Søgaard, Matthew Honnibal | 2022-12-19 | Discute l’implementazione degli embedding multi hash in spaCy per ridurre l’occupazione di memoria degli embedding di parole. Valuta questo approccio su dataset NER, confermando le scelte progettuali e rivelando risultati inaspettati. | Leggi di più |
| Resume Evaluation through Latent Dirichlet Allocation and Natural Language Processing for Effective Candidate Selection | Vidhita Jagwani, Smit Meghani, Krishna Pai, Sudhir Dhage | 2023-07-28 | Introduce un metodo per la valutazione dei CV tramite LDA e il rilevamento di entità di spaCy, raggiungendo l’82% di accuratezza e dettagliando la performance NER di spaCy. | Leggi di più |
| LatinCy: Synthetic Trained Pipelines for Latin NLP | Patrick J. Burns | 2023-05-07 | Presenta LatinCy, pipeline NLP per latino compatibili con SpaCy, che dimostrano elevata accuratezza in POS tagging e lemmatizzazione, mostrando l’adattabilità di spaCy. | Leggi di più |
| Launching into clinical space with medspaCy: a new clinical text processing toolkit in Python | Hannah Eyre, Alec B Chapman, et al. | 2021-06-14 | Introduce medspaCy, toolkit di elaborazione testuale clinica basato su spaCy, che integra approcci basati su regole e ML per il NLP clinico. | Leggi di più |
Domande frequenti
- Cos'è spaCy?
spaCy è una libreria Python open-source per l’elaborazione avanzata del linguaggio naturale (NLP), progettata per velocità, efficienza e uso produttivo. Supporta attività come tokenizzazione, POS tagging, dependency parsing e riconoscimento di entità nominate.
- In cosa spaCy si differenzia da NLTK?
spaCy è ottimizzato per ambienti di produzione con modelli pre-addestrati e un’API veloce e intuitiva, rendendolo ideale per la gestione di grandi dataset e per l’uso commerciale. NLTK, invece, è più orientato alla ricerca e offre approcci algoritmici flessibili adatti a scopo educativo e di sperimentazione.
- Quali sono alcune funzionalità chiave di spaCy?
Le funzionalità principali includono tokenizzazione, POS tagging, dependency parsing, riconoscimento di entità nominate, classificazione del testo, misurazione della similarità, matching basato su regole, integrazione di transformer, strumenti di visualizzazione e pipeline NLP personalizzabili.
- Quali sono i casi d’uso comuni per spaCy?
spaCy è ampiamente utilizzato in data science per il pre-processing del testo e l’estrazione di feature, nella costruzione di chatbot e assistenti AI, per l’estrazione di informazioni da documenti e nella ricerca accademica per l’analisi di pattern linguistici.
- spaCy può essere integrato con framework di deep learning?
Sì, spaCy può essere integrato con framework come TensorFlow e PyTorch, consentendo uno sviluppo e una distribuzione fluida di modelli NLP avanzati.
- spaCy è adatto a domini specializzati come quello sanitario o legale?
Sì, l’API flessibile e l’estensibilità di spaCy permettono di adattarlo a domini specializzati, come l’elaborazione di testi clinici (ad esempio, medspaCy) e l’analisi di documenti legali.
Esplora l’AI con spaCy
Scopri come spaCy può potenziare i tuoi progetti NLP, dai chatbot all’estrazione di informazioni e applicazioni di ricerca.
Scopri di più