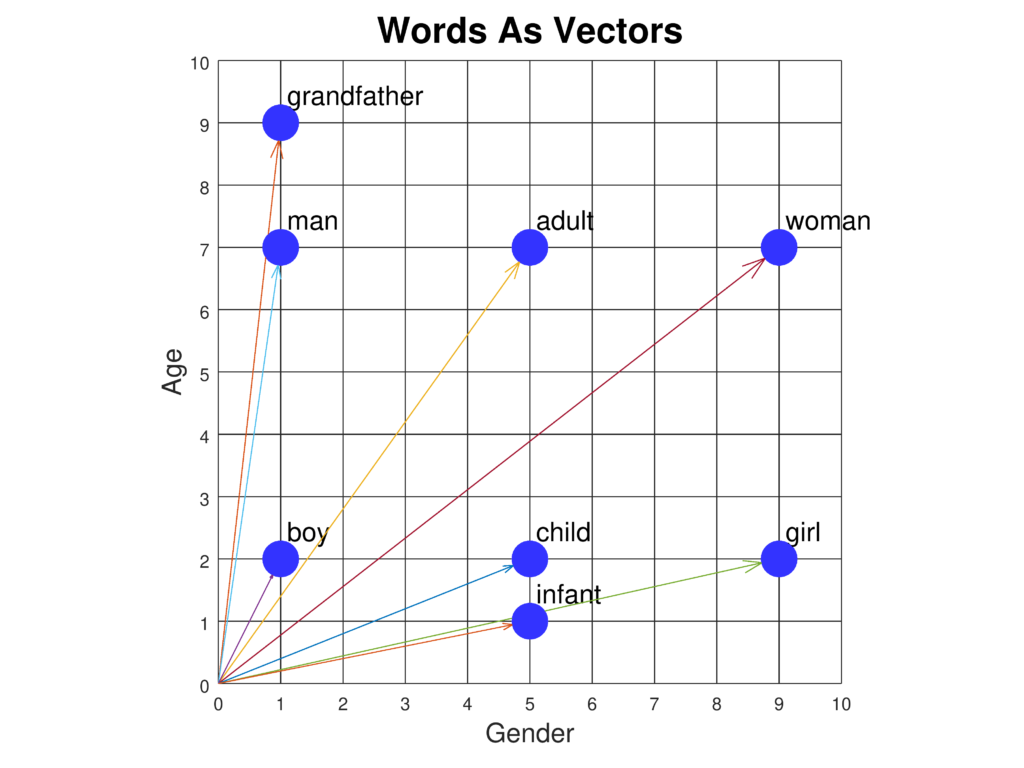
Finestratura
La finestratura nell’IA suddivide i dati in segmenti gestibili, migliorando la gestione del contesto e l’efficienza in NLP, chatbot, traduzione e analisi di serie temporali.
La finestratura nell’intelligenza artificiale si riferisce al metodo di elaborazione dei dati in segmenti o “finestre” per analizzare e generare intuizioni da informazioni sequenziali. Nel campo dell’elaborazione del linguaggio naturale (NLP), la finestratura è particolarmente significativa poiché permette ai modelli di considerare un sottoinsieme di dati alla volta, facilitando la comprensione e la generazione di testo basandosi su indizi contestuali. Esaminando i dati a blocchi, i sistemi di IA possono gestire efficientemente le risorse computazionali mantenendo la capacità di cogliere pattern rilevanti all’interno dei dati.
Nel contesto dell’NLP e dei grandi modelli linguistici (LLM), la finestratura è spesso collegata al concetto di finestre di contesto. Queste sono porzioni fisse di token che il modello può elaborare simultaneamente. I token rappresentano parti di testo, come parole o sotto-parole, e il numero di token che il modello può gestire in una volta sola definisce la dimensione della finestra di contesto. Questo approccio consente ai modelli di IA di concentrarsi su porzioni specifiche di testo, assicurando che generino risposte basate su informazioni contestuali rilevanti.
Come viene utilizzata la finestratura nell’IA
La finestratura viene utilizzata nell’IA per gestire ed elaborare efficacemente dati sequenziali. Nell’elaborazione del linguaggio naturale, permette ai modelli di gestire testi lunghi suddividendoli in segmenti gestibili. Ogni finestra contiene un certo numero di token che forniscono il contesto per il modello di IA per analizzare e generare risposte. Questo metodo è essenziale per compiti che coinvolgono la comprensione e la generazione del linguaggio umano, poiché consente ai modelli di considerare il contesto necessario senza essere sopraffatti dall’intera sequenza di dati.
In pratica, la finestratura aiuta i modelli a concentrarsi sulle parti rilevanti del testo ignorando informazioni non necessarie. Questo è particolarmente utile in applicazioni come la traduzione automatica, l’analisi del sentiment e l’IA conversazionale, dove la comprensione del contesto immediato è fondamentale per produrre output accurati e coerenti. Utilizzando la finestratura, i sistemi di IA possono mantenere prestazioni ed efficienza anche quando trattano dati lunghi o complessi.
Esempi e casi d’uso della finestratura nell’IA
Elaborazione del Linguaggio Naturale
Nell’elaborazione del linguaggio naturale, la finestratura viene impiegata per analizzare e comprendere i dati testuali. Ad esempio, nell’analisi del sentiment, un modello di IA può utilizzare la finestratura per esaminare un numero fisso di parole attorno a una frase target per determinare il sentimento espresso. Concentrandosi su una specifica finestra di testo, il modello può cogliere il contesto immediato che influenza il sentiment, come negazioni o intensificatori.
Traduzione Automatica
I sistemi di traduzione automatica utilizzano la finestratura per tradurre testo da una lingua all’altra. Il modello elabora segmenti del testo sorgente all’interno di una finestra di contesto, assicurando che la traduzione prenda in considerazione il contesto linguistico rilevante. Questo approccio aiuta a mantenere il significato e la correttezza grammaticale del testo tradotto, specialmente quando si trattano lingue con strutture frasali diverse.
Chatbot e IA Conversazionale
I chatbot utilizzano la finestratura per gestire il flusso della conversazione. Concentrandosi sulle interazioni recenti all’interno di una finestra di contesto, il chatbot può generare risposte pertinenti e coerenti. Questo è cruciale per mantenere un dialogo naturale e coinvolgente con gli utenti. Ad esempio, un chatbot di assistenza clienti può usare la finestratura per ricordare le richieste precedenti dell’utente e fornire assistenza accurata in base alla conversazione in corso.
Analisi di Serie Temporali
Nell’analisi di serie temporali, la finestratura viene utilizzata per elaborare punti dati raccolti nel tempo analizzando segmenti all’interno di una finestra mobile. Questa tecnica consente ai modelli di IA di rilevare tendenze, pattern o anomalie entro intervalli di tempo specifici. Ad esempio, nella previsione finanziaria, un sistema di IA può utilizzare la finestratura per analizzare i prezzi delle azioni all’interno di una finestra temporale mobile al fine di prevedere i movimenti futuri del mercato.
Finestratura nell’Elaborazione del Linguaggio Naturale
Permette ai sistemi di IA di concentrarsi su porzioni rilevanti di testo, il che è essenziale per compiti che richiedono comprensione contestuale. Elaborando i dati all’interno di una finestra di contesto, i modelli possono cogliere le sfumature e le dipendenze linguistiche necessarie per interpretazioni e generazioni accurate.
Inoltre, la finestratura aiuta a gestire le risorse computazionali limitando la quantità di dati elaborati alla volta. Questo è cruciale per consentire ai modelli NLP di gestire grandi dataset o operare in applicazioni in tempo reale. La finestratura garantisce che i modelli rimangano efficienti e reattivi, anche quando gestiscono dati linguistici estesi o complessi.
Finestre di Contesto nei Grandi Modelli Linguistici (LLM)
Definizione di Finestre di Contesto
Nei grandi modelli linguistici, una finestra di contesto si riferisce alla sequenza di token che il modello considera durante l’elaborazione dei dati in ingresso. La dimensione della finestra di contesto determina quanta parte del testo il modello può analizzare contemporaneamente. Finestre di contesto più ampie permettono ai modelli di considerare porzioni di testo più estese, catturando dipendenze a lungo raggio e migliorando la coerenza delle risposte generate.
Impatto sulle Prestazioni del Modello
La dimensione della finestra di contesto influisce direttamente sulle prestazioni dei LLM. Con una finestra di contesto più ampia, i modelli possono gestire input più lunghi e generare output più contestualmente rilevanti. Questo è particolarmente importante per compiti come la sintesi di documenti o la generazione di contenuti lunghi, dove è essenziale comprendere il contesto più ampio.
Tuttavia, aumentare la dimensione della finestra di contesto comporta anche delle sfide. Finestre più grandi richiedono maggiori risorse computazionali e i benefici in termini di prestazioni possono ridursi oltre una certa soglia. Bilanciare la dimensione della finestra di contesto con l’efficienza è una considerazione chiave nella progettazione e distribuzione dei LLM.
Esempi di Dimensioni delle Finestre di Contesto
Diversi LLM hanno dimensioni di finestra di contesto variabili. Ad esempio:
- GPT-3: Ha una finestra di contesto di circa 2.048 token, permettendogli di elaborare porzioni sostanziali di testo e generare risposte coerenti basate sul contesto fornito.
- GPT-4: Estende ulteriormente la finestra di contesto, consentendo una gestione del contesto ancora più ampia, che migliora le prestazioni nei compiti che richiedono la comprensione di sequenze di testo più lunghe.
- Llama 2: Offre diverse dimensioni di finestra di contesto a seconda della variante di modello specifica, adattandosi a vari casi d’uso che richiedono diversi livelli di elaborazione del contesto.
Processo di Tokenizzazione e Codifica Posizionale
Processo di Tokenizzazione
La tokenizzazione è il processo che suddivide il testo in unità più piccole chiamate token. Nell’NLP, questo è un passaggio fondamentale che consente ai modelli di IA di elaborare e analizzare i dati testuali. I token possono essere parole, sotto-parole o persino singoli caratteri, a seconda della lingua e dell’algoritmo di tokenizzazione utilizzato.
Ad esempio, la frase “The quick brown fox jumps over the lazy dog” può essere suddivisa in parole o sotto-parole, permettendo al modello di elaborare ogni elemento in sequenza. La tokenizzazione aiuta a standardizzare i dati in ingresso e a renderli gestibili dal punto di vista computazionale.
Codifica Posizionale
La codifica posizionale è una tecnica utilizzata nei modelli basati su transformer per incorporare informazioni sulla posizione dei token nella sequenza. Poiché i transformer elaborano i token in parallelo anziché in sequenza, la codifica posizionale garantisce che il modello sia consapevole dell’ordine dei token, aspetto cruciale per comprendere la sintassi e il significato del testo.
In codice Python, la codifica posizionale può essere implementata così:
import torch
import math
def positional_encoding(position, d_model):
pe = torch.zeros(position, d_model)
for pos in range(position):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))
return pe
Questo codice genera una matrice di codifica posizionale che può essere aggiunta alle embedding dei token, fornendo al modello informazioni sulla posizione di ciascun token.
Ruolo nella Finestratura
Nel contesto della finestratura, tokenizzazione e codifica posizionale lavorano insieme per consentire al modello di elaborare sequenze di token all’interno della finestra di contesto. La tokenizzazione suddivide il testo in unità comprensibili dal modello, mentre la codifica posizionale preserva l’ordine di questi token. Questa combinazione permette al sistema di IA di analizzare accuratamente il testo all’interno di ogni finestra, mantenendo coerenza e contesto necessari per generare risposte significative.
Sfide e Limitazioni della Finestratura
Complessità Computazionale
Una delle principali sfide della finestratura nell’IA è la complessità computazionale coinvolta nell’elaborazione di finestre di contesto di grandi dimensioni. All’aumentare della dimensione della finestra, crescono anche le risorse computazionali necessarie, spesso in modo esponenziale. Questo può portare a costi maggiori e tempi di elaborazione più lenti, rendendo la soluzione poco pratica per applicazioni in tempo reale o su dispositivi con risorse limitate.
Perdita di Informazioni
Sebbene la finestratura aiuti a gestire efficacemente i dati, può anche comportare una perdita di informazioni. Concentrandosi solo sui dati all’interno della finestra di contesto, il modello può perdere informazioni importanti che si trovano al di fuori di essa. Questo può influire sull’accuratezza delle previsioni o sulla pertinenza delle risposte generate, soprattutto in compiti che richiedono una comprensione più ampia dei dati.
Bilanciare Contesto ed Efficienza
Trovare il giusto equilibrio tra la dimensione della finestra di contesto e l’efficienza computazionale è una sfida significativa. Una finestra troppo piccola potrebbe non fornire abbastanza contesto affinché il modello funzioni efficacemente, mentre una finestra troppo grande potrebbe essere dispendiosa in termini di risorse e lenta. Questo richiede un’attenta valutazione e ottimizzazione durante la progettazione e la distribuzione del modello.
Gestione delle Dipendenze a Lungo Termine
La finestratura può rendere difficile per i modelli catturare le dipendenze a lungo termine nei dati sequenziali. Nell’elaborazione del linguaggio, comprendere la relazione tra parole o frasi distanti è importante per compiti come l’analisi del discorso o la comprensione narrativa. La finestratura limita la visione del modello a uno spazio fisso, il che può ostacolare la sua capacità di cogliere queste relazioni a lungo raggio.
Domande frequenti
- Cos'è la finestratura nell'intelligenza artificiale?
La finestratura nell'IA è il processo di suddividere i dati in segmenti, o finestre, per analizzare efficientemente informazioni sequenziali. Aiuta i modelli a gestire il contesto e le risorse computazionali, soprattutto nell'NLP e nei grandi modelli linguistici.
- Perché la finestratura è importante nell'NLP e nei LLM?
La finestratura permette a NLP e LLM di elaborare segmenti gestibili di testo, ottimizzando l'uso delle risorse e consentendo analisi consapevoli del contesto. Questo è fondamentale per compiti come traduzione, analisi del sentiment e IA conversazionale.
- Quali sono gli usi comuni della finestratura nell'IA?
La finestratura è usata nell'NLP per l'analisi del testo, traduzione automatica, chatbot per gestire conversazioni, e analisi di serie temporali per rilevare tendenze e pattern entro intervalli di tempo specifici.
- Quali sfide sono associate alla finestratura?
Le sfide includono la complessità computazionale con finestre più grandi, il rischio di perdita di informazioni fuori dalla finestra, il bilanciamento della dimensione della finestra tra contesto ed efficienza, e la difficoltà nel catturare dipendenze a lungo termine nei dati sequenziali.
Pronto a creare la tua IA?
Chatbot intelligenti e strumenti di IA sotto lo stesso tetto. Collega blocchi intuitivi per trasformare le tue idee in Flussi automatizzati.
Scopri di più