
Documenti
Il tuo chatbot può accedere e utilizzare istantaneamente documenti, pagine HTML e persino video YouTube per personalizzare il tuo contesto unico. Perfetto per a...
2 min di lettura
AI Chatbot
Knowledge Management
+3
Scopri come impostare i parametri ‘Da H1 se esiste’, ‘Carica da puntatore’ e ‘Salta ultimo header’.
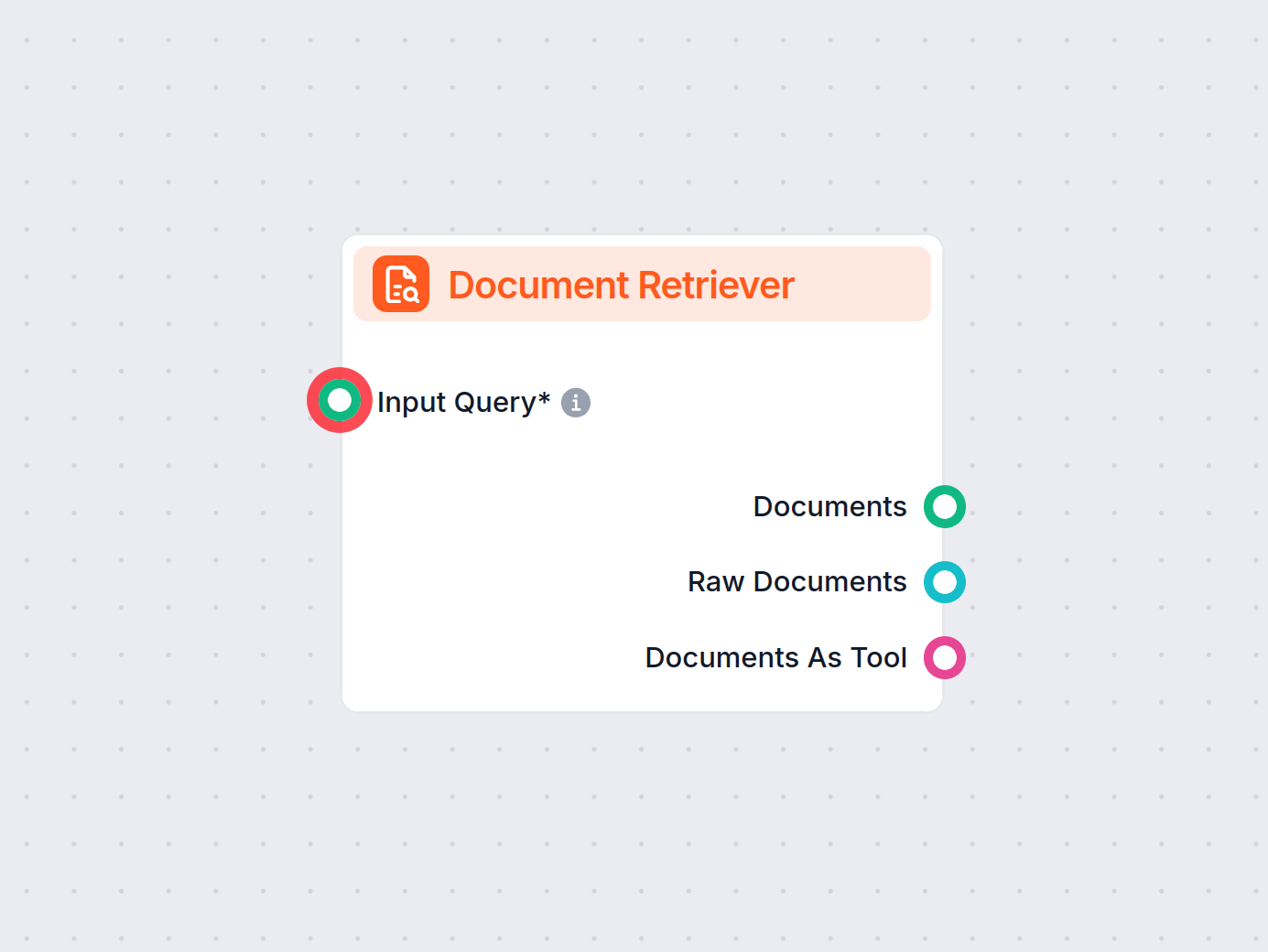
Il componente Document Retriever consente al chatbot di recuperare conoscenza dalle fonti che hai specificato nei Documenti e nelle Pianificazioni. Il ruolo di questo componente è gestire il recupero, e diversi parametri influenzano il modo in cui il componente estrae le informazioni da tali documenti.
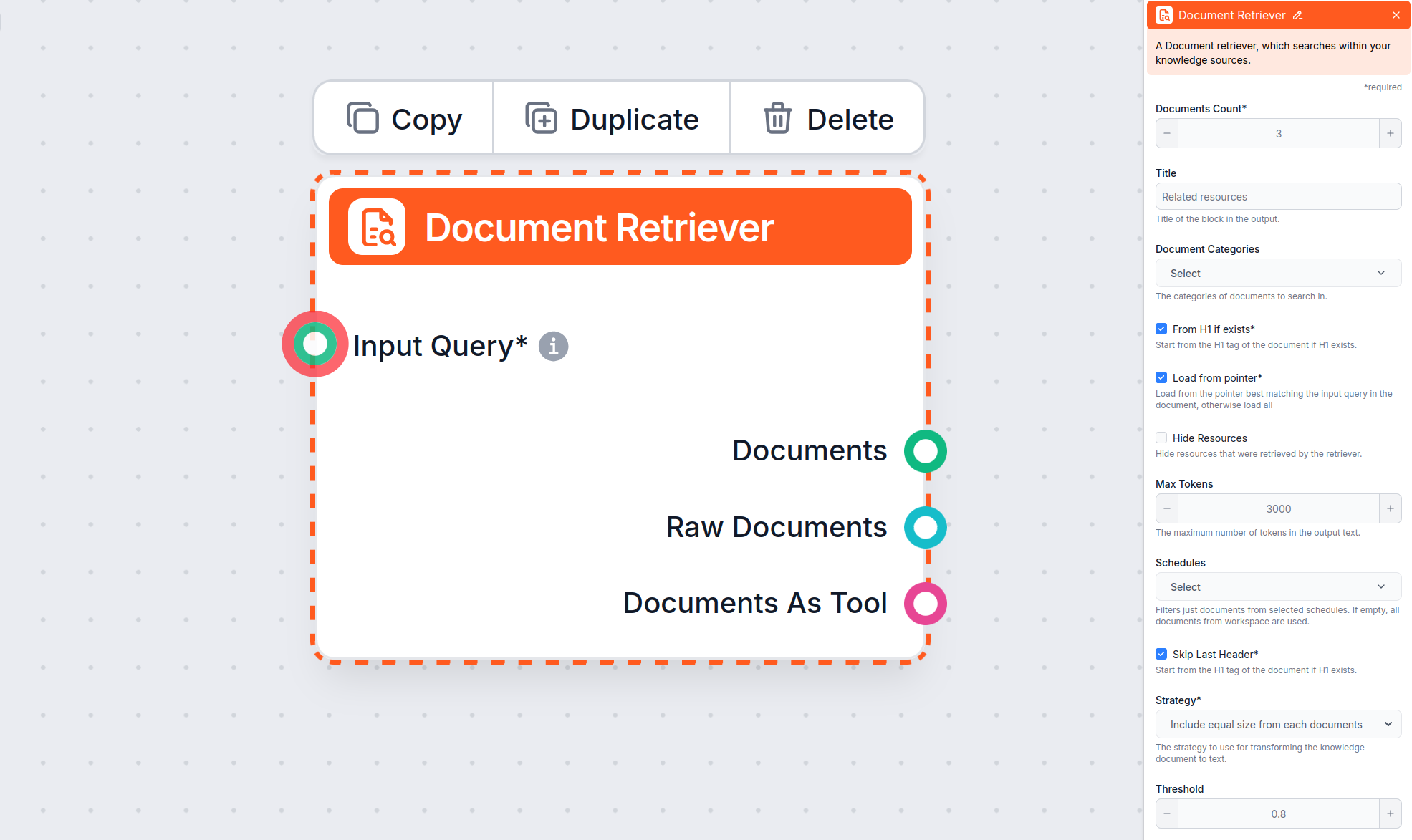
L’opzione Da H1 se esiste indica al retriever di iniziare a estrarre il contenuto dall’intestazione H1 che trova (solitamente il titolo principale dell’articolo).
Cosa succede?
Esempio d’uso:
Vuoi recuperare solo la guida vera e propria, senza la navigazione del sito o il disordine di intestazioni presenti sulla tua pagina web.
Nota:
Da H1 se esiste è abilitato di default nel componente Document Retriever.
L’opzione Carica da puntatore offre maggiore precisione consentendo al Document Retriever di caricare solo i dati a partire da un puntatore all’interno di un articolo potenzialmente lungo.
Cosa succede?
Cos’è un “puntatore”?
Un puntatore è solitamente una stringa o intestazione unica presente nel documento (ad esempio, un H2 o una frase/sezione specifica).
Esempio d’uso:
Vuoi saltare le sezioni introduttive e recuperare informazioni solo da una sezione rilevante di un articolo o documento lungo (ad esempio da “Step 4: Aggiungi un pulsante di live chat” in una guida all’installazione).
L’opzione Salta ultimo header è utile per ignorare l’ultima intestazione del documento, spesso ripetuta o utilizzata per navigazione o footer.
Cosa succede?
Esempio d’uso:
Vuoi evitare che il Document Retriever carichi un’intestazione di navigazione del footer (come “Altri articoli” alla fine di una pagina di aiuto), assicurandoti che venga elaborato solo il contenuto principale.
Nota:
Salta ultimo header può essere utile per documenti che generano automaticamente footer o elementi di navigazione ripetitivi. Tuttavia, se il documento non contiene tali sezioni, l’utilizzo di questo parametro potrebbe impedire il recupero di parti dell’articolo con informazioni valide. Si consiglia quindi di lasciare questa opzione deselezionata fino a quando non vi sia un motivo valido per abilitarla.
Il parametro Max tokens consente di controllare il numero massimo di token (parole e segni di punteggiatura, come conteggiati dal modello AI sottostante) che il Document Retriever restituirà dal testo estratto.
Cosa succede?
Valore predefinito:
Il valore predefinito è solitamente 3000 token, ma puoi modificarlo se necessario.
Esempio d’uso:
Se stai processando documenti lunghi, impostare un valore Max tokens più basso aiuta a mantenere le risposte concise. Tuttavia, per risultati ottimali, considera di abilitare il parametro “Carica da puntatore”. In questo modo, il testo estratto inizierà dalla sezione più rilevante del documento, invece che dall’inizio, permettendoti di ottenere una porzione mirata e gestibile di informazioni entro il limite di token specificato. Questa combinazione è particolarmente utile quando desideri output concisi e contestualmente rilevanti da fonti molto grandi.
Nota:
Se noti che informazioni vengono tagliate, prova ad aumentare il valore di Max tokens. Al contrario, se desideri risposte più brevi e focalizzate, riduci il parametro Max tokens.
Quando il Document Retriever trova diversi documenti rilevanti, il parametro Strategia determina come vengono uniti in un unico output di testo per il tuo chatbot, tenendo conto del limite “Max tokens”.
Due opzioni di strategia:
Includi dimensione uguale da ciascun documento:
Il limite di token viene suddiviso in modo uniforme. Ad esempio, con tre documenti e un limite di 3.000 token, ciascuno riceve fino a 1.000 token. Ciò garantisce che tutte le fonti contribuiscano in modo equo, utile quando desideri una risposta bilanciata che attinga da più documenti.
Concatena i documenti, riempi dal primo fino al limite di token:
I documenti vengono aggiunti in ordine di rilevanza fino al raggiungimento del limite di token. Il documento più rilevante riempie lo spazio per primo; se rimane spazio, vengono aggiunti i documenti meno rilevanti in ordine. Se il primo documento è lungo, potrebbe usare da solo tutto il limite.
Come scegliere?
Nota:
Queste strategie influenzano solo il modo in cui il testo viene costruito dai documenti recuperati prima di essere passato al passaggio successivo (come la generazione AI). Non modificano quali documenti vengono recuperati, ma solo come il loro contenuto viene unito e tagliato per rientrare nel limite Max tokens.
Sebbene questo articolo si concentri sulla configurazione dei parametri ‘Da H1 se esiste’, ‘Carica da puntatore’, ‘Salta ultimo header’ e ‘Max tokens’, il Document Retriever offre anche altri parametri che aiutano a controllare come i documenti vengono selezionati e recuperati:
Questa impostazione limita il numero di documenti che il flusso dovrebbe recuperare, assicurando che i risultati restino pertinenti e le risposte siano generate rapidamente.
Questa impostazione opzionale consente di limitare il recupero a una o più categorie che hai creato nella sezione Documenti delle Fonti di conoscenza.
Questa opzione permette di includere o nascondere una sezione separata, prima della risposta effettiva del chatbot, con un elenco delle risorse recuperate dal retriever. Per l’integrazione con LiveAgent, deve essere selezionata, poiché questa sezione non è supportata e non verrà visualizzata correttamente nel widget chatbot di LiveAgent.
Consente di limitare il recupero a una o più Pianificazioni che hai specificato per la scansione o l’aggiornamento dei contenuti nelle Fonti di conoscenza.
Controlla quanto i documenti recuperati devono corrispondere alla query di input, utilizzando un punteggio di rilevanza (da 0 a 1). Ad esempio, si consiglia una soglia di 0,7–0,8 per risposte altamente pertinenti. Soglie più alte danno corrispondenze più precise, mentre soglie più basse possono includere documenti meno rilevanti.
Esempio:
Se imposti una soglia di 0,6 e hai quattro articoli con punteggi di rilevanza di 0,8, 0,65, 0,5 e 0,9, verranno utilizzati solo quelli sopra 0,6 (ossia 0,8, 0,65 e 0,9) per l’estrazione.
Se la risposta fornita dal chatbot non contiene informazioni che sei certo siano disponibili nei tuoi documenti o pianificazioni, prova a controllare la cronologia della conversazione con l’opzione “Verbose” per vedere i log dettagliati su se il Document Retriever è stato utilizzato e quali documenti sono stati recuperati. Se necessario, modifica le impostazioni e il prompt in base a questi log.
Il tuo chatbot può accedere e utilizzare istantaneamente documenti, pagine HTML e persino video YouTube per personalizzare il tuo contesto unico. Perfetto per a...
Il Document Retriever di FlowHunt migliora l'accuratezza dell’AI collegando i modelli generativi ai tuoi documenti e URL aggiornati, garantendo risposte affidab...
Integra i tuoi flussi di lavoro con Google Docs utilizzando il componente Google Docs Retriever: recupera facilmente il contenuto dei documenti da utilizzare in...