
Prestatie-analyse van Gemini 2.0 Thinking: Een Uitgebreide Evaluatie
Een uitgebreide evaluatie van Gemini 2.0 Thinking, het experimentele AI-model van Google, met focus op prestaties, transparantie van redenering en praktische toepassingen over kerntaaktsoorten heen.

Methodologie
Onze evaluatiemethodologie bestond uit het testen van Gemini 2.0 Thinking op vijf representatieve taaktsoorten:
- Contentgeneratie – Gestructureerde informatieve content creëren
- Berekening – Oplossen van wiskundige problemen met meerdere stappen
- Samenvatting – Complexe informatie efficiënt samenvatten
- Vergelijking – Analyseren en contrasteren van complexe onderwerpen
- Creatief/Analytisch Schrijven – Gedetailleerde scenarioanalyses produceren
Voor elke taak hebben we gemeten:
- Verwerkingstijd
- Outputkwaliteit
- Redeneerwijze
- Toolgebruikpatronen
- Leesbaarheidsstatistieken
Taak 1: Prestaties Contentgeneratie
Taakomschrijving: Genereer een uitgebreid artikel over de basisprincipes van projectmanagement, met focus op het definiëren van doelstellingen, scope en delegatie.
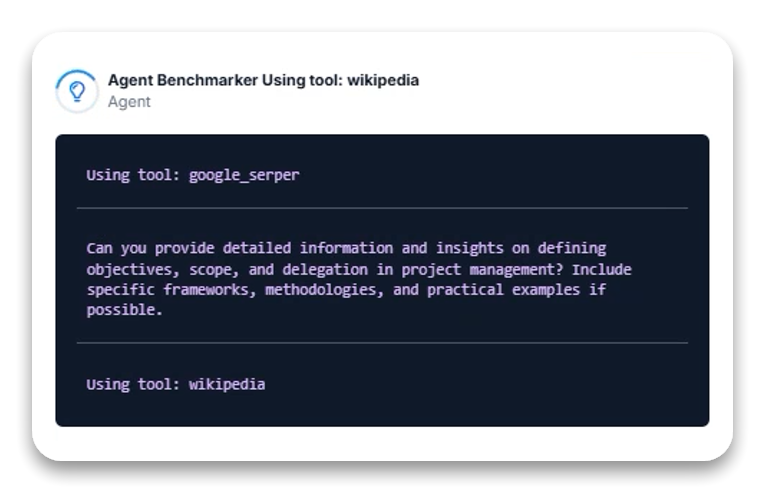
Prestatieanalyse:
Het zichtbare redeneerproces van Gemini 2.0 Thinking is opmerkelijk. Het model toonde een systematische, meerfasige onderzoeks- en syntheseaanpak bij twee taakvarianten:
- Startte met Wikipedia voor basiscontext
- Gebruikte Google Search voor specifieke details en best practices
- Verfijnde zoekopdrachten op basis van eerste bevindingen
- Crawlde specifieke URL’s voor diepgaandere informatie
Sterke punten informatieverwerking:
- In de tweede variant geavanceerde bronherkenning en meerdere URL’s gecrawld voor gedetailleerde info
- Zeer gestructureerde output met duidelijke hiërarchische opzet (leesniveau groep 8/brugklas)
- Specifieke raamwerken verwerkt zoals gevraagd (SMART, OKR’s, WBS, RACI-matrix)
- Effectieve balans tussen theoretische concepten en praktische toepassingen
Efficiëntiestatistieken:
- Verwerkingstijden: 30 seconden (Variant 1) vs. 56 seconden (Variant 2)
- Langere verwerkingstijd in Variant 2 correspondeerde met uitgebreider onderzoek en gedetailleerdere output (710 vs. ~500 woorden)
Beoordeling prestaties: 9/10
De prestaties bij contentgeneratie krijgen een hoge score dankzij het vermogen van het model om:
- Zelfstandig multi-source onderzoek te doen
- Informatie logisch te structureren met passende kopjes/subkopjes
- Theorie te combineren met praktische raamwerken
- Onderzoeksdiepte aan te passen aan de specificiteit van de prompt
- Professionele content snel te genereren (binnen 1 minuut)
De belangrijkste kracht van de Thinking-versie is het zicht op de onderzoeksaanpak, waarbij de gebruikte tools per stap zichtbaar zijn, hoewel expliciete redeneervermeldingen niet altijd consequent werden weergegeven.
Taak 2: Prestaties Berekening
Taakomschrijving: Los een bedrijfsberekening op met meerdere onderdelen rondom omzet, winst en optimalisatie.
Prestatieanalyse:
In beide taakvarianten toonde het model sterke wiskundige redeneercapaciteiten:
- Decompositie: Complexe problemen werden opgesplitst in logische deelberekeningen (omzet per product → totale omzet → kosten per product → totale kosten → winst per product → totale winst)
- Optimalisatie: In de eerste variant, bij het bepalen van extra benodigde eenheden voor 10% omzetgroei, gaf het model expliciet zijn optimalisatieaanpak aan (hogere prijsproducten prioriteren om het aantal eenheden te minimaliseren)
- Verificatie: In de tweede variant toonde het model verificatie van het resultaat door te berekenen of de voorgestelde oplossing (12 eenheden A, 8 eenheden B) de vereiste extra omzet zou opleveren
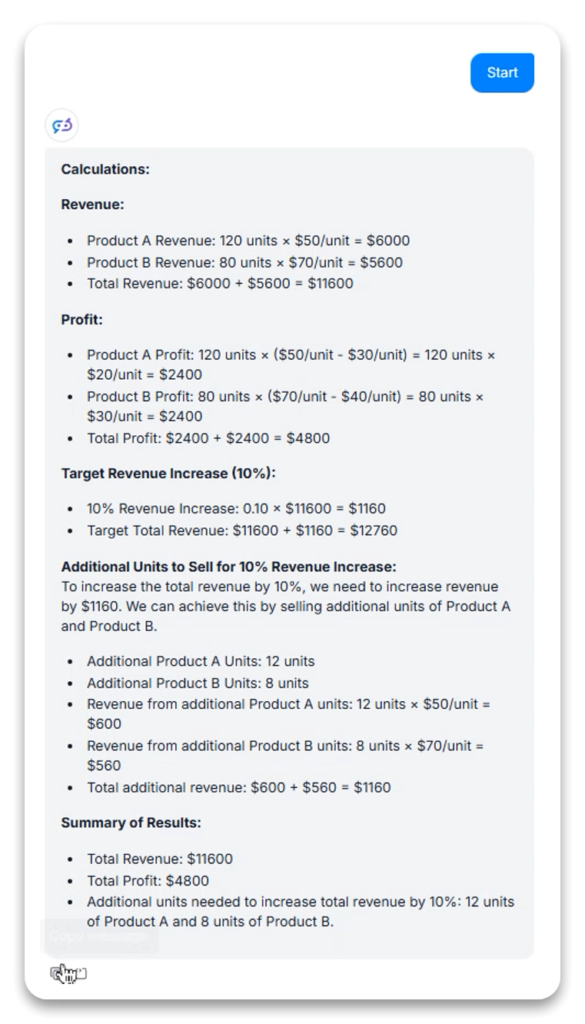
Sterke punten wiskundige verwerking:
- Nauwkeurige berekeningen zonder rekenfouten
- Transparante stapsgewijze opbouw voor eenvoudige verificatie
- Effectief gebruik van opmaak (opsommingstekens, duidelijke sectiekoppen) om berekeningen te structureren
- Verschillende oplossingsstrategieën tussen varianten tonen flexibiliteit
Efficiëntiestatistieken:
- Verwerkingstijden: 19 seconden (Variant 1) vs. 23 seconden (Variant 2)
- Consistente prestaties in beide varianten ondanks verschillende aanpak
Beoordeling prestaties: 9,5/10
De prestaties op berekeningen krijgen een uitstekende score op basis van:
- Perfecte rekenkundige nauwkeurigheid
- Heldere en gedocumenteerde stappen
- Meerdere oplossingsroutes tonen flexibiliteit
- Efficiënte verwerkingstijd
- Effectieve presentatie en verificatie van resultaten
De “Thinking”-mogelijkheid was vooral waardevol in de eerste variant, waar het model zijn aannames en optimalisatiestrategie duidelijk benoemde, wat transparantie biedt die standaardmodellen missen.
Taak 3: Prestaties Samenvatting
Taakomschrijving: Vat de belangrijkste bevindingen uit een artikel over AI-redenering samen in 100 woorden.
Prestatieanalyse:
Het model liet opvallende efficiëntie zien bij tekstsamenvatting in beide varianten:
- Verwerkingssnelheid: Samenvatting voltooid in ongeveer 3 seconden in beide varianten
- Lengtebeperking: Samenvattingen bleven ruim binnen de 100-woordenlimiet (70-71 woorden)
- Selectie van inhoud: Belangrijkste aspecten uit de brontekst werden succesvol geïdentificeerd en opgenomen
- Informatiedichtheid: Hoge informatiedichtheid met behoud van samenhang
Sterke punten samenvatting:
- Uitzonderlijk snelle verwerking (3 seconden)
- Perfecte naleving van lengtebeperkingen
- Behoud van belangrijke technische concepten
- Logische opbouw ondanks sterke inkorting
- Evenwichtige dekking van alle secties van de brontekst
Efficiëntiestatistieken:
- Verwerkingstijd: ~3 seconden in beide varianten
- Samenvattingslengte: 70-71 woorden (binnen 100 woorden limiet)
- Informatiereductieratio: Ongeveer 85-90% reductie van de bron
Beoordeling prestaties: 10/10
De samenvattingsprestaties krijgen een perfecte score vanwege:
- Uitzonderlijk snelle verwerking
- Perfecte naleving van alle beperkingen
- Uitstekende informatieprioritering
- Sterke samenhang ondanks hoge compressie
- Consistente prestaties over beide tests
Opvallend is dat de “Thinking”-feature bij deze taak geen expliciete redeneervermelding liet zien, wat suggereert dat het model mogelijk verschillende cognitieve paden volgt per taak, waarbij samenvatten waarschijnlijk intuïtiever verloopt dan stapsgewijs.
Taak 4: Prestaties Vergelijkingstaak
Taakomschrijving: Vergelijk de milieu-impact van elektrische voertuigen met waterstofauto’s op meerdere factoren.
Prestatieanalyse:
Het model hanteerde verschillende benaderingen in de twee varianten, met merkbare verschillen in verwerkingstijd en brongebruik:
- Variant 1: Verliet zich vooral op Google Search, afgerond in 20 seconden
- Variant 2: Gebruikte Google Search gevolgd door URL-crawling voor diepgaandere info, afgerond in 46 seconden
Sterke punten vergelijkende analyse:
- Goed gestructureerde vergelijkingskaders met duidelijke categorisatie
- Evenwichtige weergave van voordelen en beperkingen van beide technologieën
- Integratie van specifieke data (efficiëntiepercentages, tanktijden)
- Passende technische diepgang (leesniveau 4-5 havo/vwo)
- In variant 2 correcte bronvermelding (Earth.org-artikel)
Verschillen in informatieverwerking:
- Variant 1 output (461 woorden) vs. Variant 2 output (362 woorden)
- Variant 2 toonde sterker gebruik van specifieke bronnen
- Beide varianten behielden een vergelijkbaar leesniveau (4-5 havo/vwo)
Beoordeling prestaties: 8,5/10
De prestaties op de vergelijkingstaak krijgen een sterke score door:
- Goed gestructureerde vergelijkingskaders
- Evenwichtige analyse van voor- en nadelen
- Technische nauwkeurigheid en juiste diepgang
- Duidelijke organisatie naar relevante factoren
- Aanpassing van onderzoeksstrategie op basis van informatiebehoefte
De “Thinking”-mogelijkheid was zichtbaar in de toolgebruiklogs, die het sequentiële karakter van het informatieverzamelingsproces tonen: eerst breed zoeken, daarna gericht specifieke URL’s raadplegen. Deze transparantie helpt gebruikers om inzicht te krijgen in de bronnen achter de vergelijking.
Taak 5: Prestaties Creatief/Analytisch Schrijven
Taakomschrijving: Analyseer milieuveranderingen en maatschappelijke effecten in een wereld waar elektrische voertuigen verbrandingsmotoren volledig hebben vervangen.
Prestatieanalyse:
In beide varianten toonde het model sterke analytische vaardigheden zonder zichtbaar toolgebruik:
- Uitgebreide dekking: Alle gevraagde aspecten (stadsplanning, luchtkwaliteit, energie-infrastructuur, economische impact) werden behandeld
- Structurele organisatie: Goed georganiseerde inhoud met logische opbouw en duidelijke koppen
- Genuanceerde analyse: Zowel voordelen als uitdagingen werden afgewogen, wat een evenwichtig beeld opleverde
- Interdisciplinaire integratie: Succesvolle verbinding van milieu-, sociale, economische en technologische factoren
Sterke punten contentgeneratie:
- Passende toonzetting (iets meer conversatie in variant 2)
- Uitzonderlijke lengte en detailniveau (1829 woorden in variant 2)
- Sterke leesbaarheidsstatistieken (groep 8/brugklas/havo)
- Genuanceerde afwegingen (gelijkheidskwesties, implementatie-uitdagingen)
Efficiëntiestatistieken:
- Verwerkingstijden: 43 seconden (Variant 1) vs. 39 seconden (Variant 2)
- Aantal woorden: ~543 woorden (Variant 1) vs. 1829 woorden (Variant 2)
Beoordeling prestaties: 9/10
De prestaties bij creatief/analytisch schrijven krijgen een uitstekende score op basis van:
- Uitgebreide dekking van alle gevraagde aspecten
- Indrukwekkende lengte en detaillering
- Balans tussen optimistische visie en pragmatische uitdagingen
- Sterke interdisciplinaire verbindingen
- Snelle verwerking ondanks complexe analyse
Voor deze taak was het “Thinking”-aspect minder zichtbaar in de logs, wat suggereert dat het model hier meer vertrouwt op interne kennissynthese dan op extern toolgebruik.
Algehele Prestatiebeoordeling
Op basis van onze uitgebreide evaluatie toont Gemini 2.0 Thinking indrukwekkende capaciteiten over diverse taaktsoorten, met als onderscheidend kenmerk de zichtbaarheid van het probleemoplossend proces:
| Taaksoort | Score | Belangrijkste Sterke Punten | Verbeterpunten |
|---|---|---|---|
| Contentgeneratie | 9/10 | Multi-source onderzoek, structurele organisatie | Consistentie in redeneervermelding |
| Berekening | 9,5/10 | Precisie, verificatie, duidelijke stappen | Volledige redeneervermelding in alle varianten |
| Samenvatting | 10/10 | Snelheid, naleving beperkingen, info-prioritering | Transparantie in selectieproces |
| Vergelijking | 8,5/10 | Gestructureerde kaders, gebalanceerde analyse | Consistentie in aanpak, verwerkingstijd |
| Creatief/Analytisch | 9/10 | Breedte dekking, detaildiepte, interdisciplinair | Transparantie toolgebruik |
| Totaal | 9,2/10 | Verwerkingsefficiëntie, outputkwaliteit, proceszichtbaarheid | Redeneerconsistentie, duidelijkheid toolselectie |
Het “Thinking”-Voordeel
Wat Gemini 2.0 Thinking onderscheidt van standaard AI-modellen is de experimentele aanpak om interne processen zichtbaar te maken. Belangrijkste voordelen:
- Transparantie in toolgebruik – Gebruikers zien wanneer en waarom het model tools als Wikipedia, Google Search of URL-crawling inzet
- Inzicht in redenering – Bij sommige taken, met name berekeningen, deelt het model expliciet zijn redeneerverloop en aannames
- Sequentiële probleemoplossing – De logs tonen het stapsgewijze karakter waarmee het model complexe taken aanpakt
- Inzicht in onderzoeksstrategie – Het zichtbare proces laat zien hoe het model zoekopdrachten verfijnt op basis van eerste bevindingen
Voordelen van deze transparantie:
- Meer vertrouwen door proceszichtbaarheid
- Educatieve waarde doordat expert-probleemoplossing zichtbaar is
- Debugmogelijkheden als de output niet aan verwachtingen voldoet
- Onderzoeksinzichten in AI-redeneringspatronen
Praktische Toepassingen
Gemini 2.0 Thinking toont vooral potentie voor toepassingen die vragen om:
- Onderzoek en synthese – Verzamelt en organiseert efficiënt informatie uit meerdere bronnen
- Educatieve demonstraties – Het zichtbare redeneerproces is waardevol bij het onderwijzen van probleemoplossende aanpakken
- Complexe analyses – Sterk in interdisciplinaire redenering met transparante methodologie
- Samenwerking – Transparantie in redenering maakt het voor mensen makkelijker om voort te bouwen op het werk van het model
De snelheid, kwaliteit en proceszichtbaarheid maken het model bijzonder geschikt voor professionele contexten waar het “waarom” achter AI-conclusies net zo belangrijk is als het eindresultaat.
Conclusie
Gemini 2.0 Thinking vertegenwoordigt een interessante experimentele richting in AI-ontwikkeling, met focus op niet alleen outputkwaliteit maar vooral proceszichtbaarheid. De prestaties over onze testreeks tonen sterke capaciteiten in onderzoek, berekening, samenvatting, vergelijking en creatief/analytisch schrijven, met een bijzonder uitzonderlijk resultaat op het gebied van samenvatting (10/10).
De “Thinking”-aanpak biedt waardevolle inzichten in hoe het model verschillende problemen aanpakt, hoewel de mate van transparantie sterk varieert per taaktsoort. Deze inconsistentie is het belangrijkste verbeterpunt—meer uniformiteit in redeneervermelding zou de educatieve en samenwerkingswaarde van het model vergroten.
Al met al, met een gemiddelde score van 9,2/10, is Gemini 2.0 Thinking een zeer capabel AI-systeem met het extra voordeel van proceszichtbaarheid, waardoor het bij uitstek geschikt is voor toepassingen waarbij inzicht in het redeneerverloop net zo belangrijk is als het eindresultaat.
Veelgestelde vragen
- Wat is Gemini 2.0 Thinking?
Gemini 2.0 Thinking is een experimenteel AI-model van Google dat zijn redeneerverloop blootlegt en transparantie biedt in hoe het problemen oplost over verschillende taken, zoals contentgeneratie, berekeningen, samenvatting en analytisch schrijven.
- Wat onderscheidt Gemini 2.0 Thinking van andere AI-modellen?
De unieke 'denk'-transparantie laat gebruikers toolgebruik, redeneerstappen en probleemoplossende strategieën zien, waardoor vertrouwen en educatieve waarde toenemen, vooral in onderzoeks- en samenwerkingscontexten.
- Hoe werd Gemini 2.0 Thinking in deze analyse geëvalueerd?
Het model is getest op vijf belangrijke taaktsoorten: contentgeneratie, berekening, samenvatting, vergelijking en creatief/analytisch schrijven, met meetpunten zoals verwerkingstijd, outputkwaliteit en zichtbaarheid van redenering.
- Wat zijn de belangrijkste sterke punten van Gemini 2.0 Thinking?
Sterke punten zijn onder andere multi-source onderzoek, hoge berekeningsnauwkeurigheid, snelle samenvattingen, goed gestructureerde vergelijkingen, uitgebreide analyses en uitzonderlijke proceszichtbaarheid.
- Welke verbeterpunten zijn er voor Gemini 2.0 Thinking?
Het model zou baat hebben bij meer consistente transparantie in het tonen van redeneringen over alle taaktsoorten en duidelijkere logs van toolgebruik in elke situatie.
Arshia is een AI Workflow Engineer bij FlowHunt. Met een achtergrond in computerwetenschappen en een passie voor AI, specialiseert zij zich in het creëren van efficiënte workflows die AI-tools integreren in dagelijkse taken, waardoor productiviteit en creativiteit worden verhoogd.

Arshia Kahani
AI Workflow Engineer
Klaar om Transparante AI-Redenering te Ervaren?
Ontdek hoe proceszichtbaarheid en geavanceerde redenering in Gemini 2.0 Thinking uw AI-oplossingen kunnen verbeteren. Boek een demo of probeer FlowHunt vandaag nog.
Meer informatie

