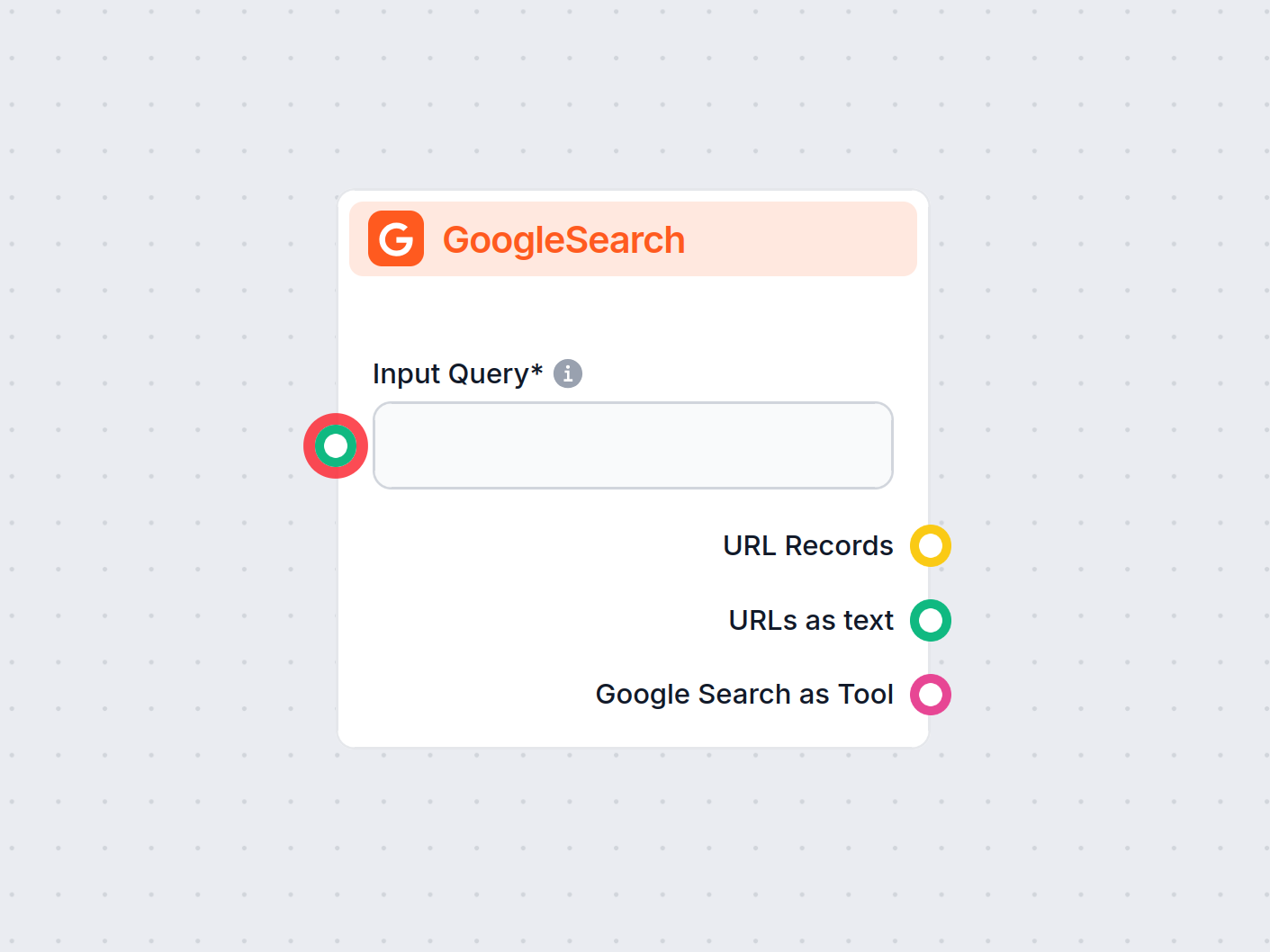
Document Retriever
Document Retriever koppelt AI-modellen aan jouw geselecteerde documenten en URL’s, waardoor je accurate, actuele en relevante AI-antwoorden krijgt voor jouw specifieke toepassing.
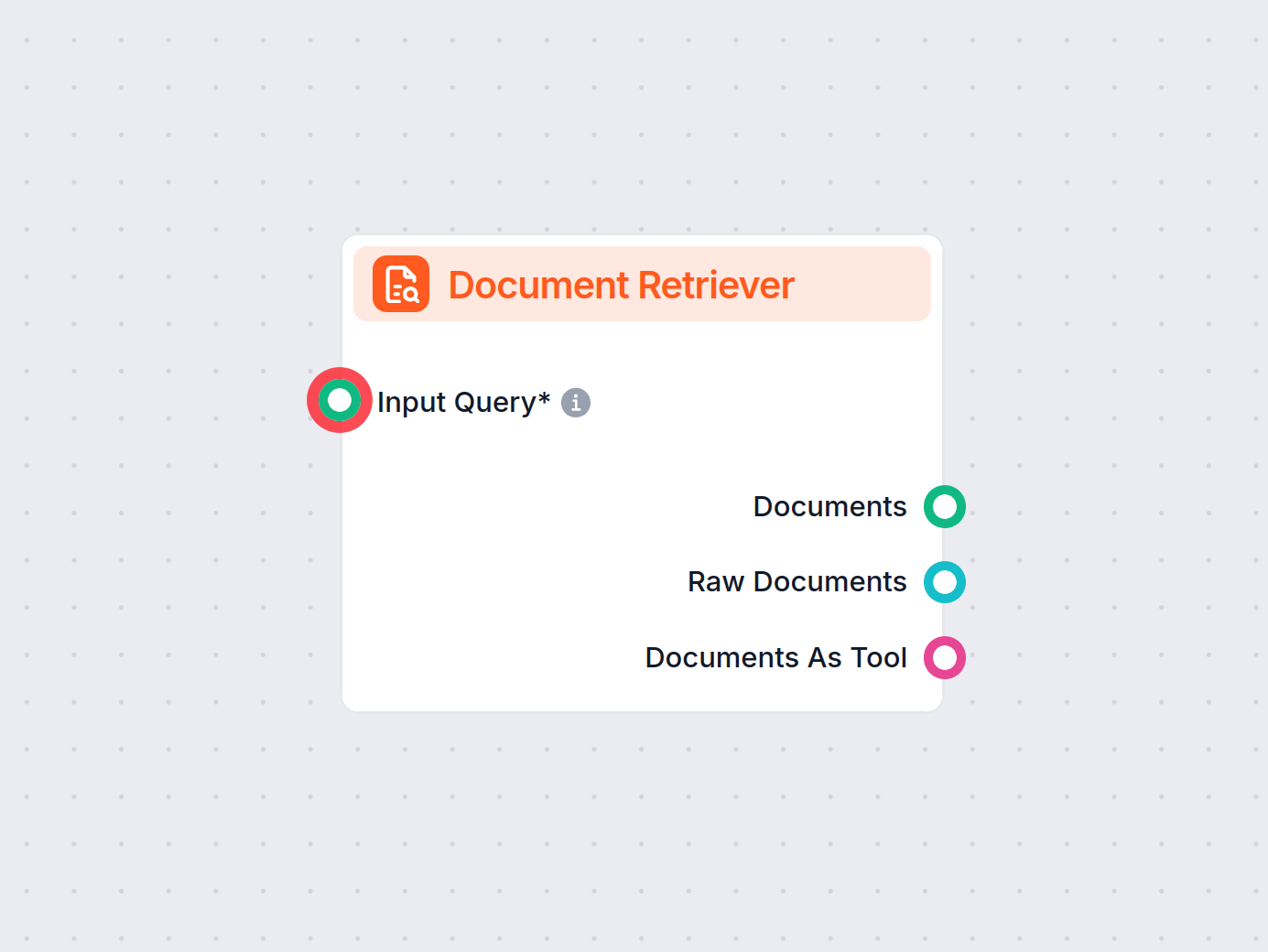
Componentbeschrijving
Hoe de Document Retriever-component werkt
Het grootste nadeel van grote taalmodellen is hun neiging om vage, verouderde of zelfs onjuiste informatie te presenteren. Om ervoor te zorgen dat de antwoorden altijd up-to-date en relevant zijn voor jouw toepassing, moeten generatieve modellen naar de juiste kennisbronnen worden geleid.
Deze aanpak, Retrieval-Augmented Generation (RAG) genoemd, voorziet generatieve modellen van je eigen kennisbronnen. De retriever-componenten, waaronder de Document Retriever, maken het mogelijk om deze methode te gebruiken.
Wat is de Document Retriever-component?
Met deze component kan de chatbot kennis ophalen uit je eigen bronnen, zodat de informatie relevant, betrouwbaar en actueel is. Deze informatie komt rechtstreeks uit de bronnen die je hebt opgegeven bij Documenten en Schema’s. De rol van deze component is het beheren van de opvraging.
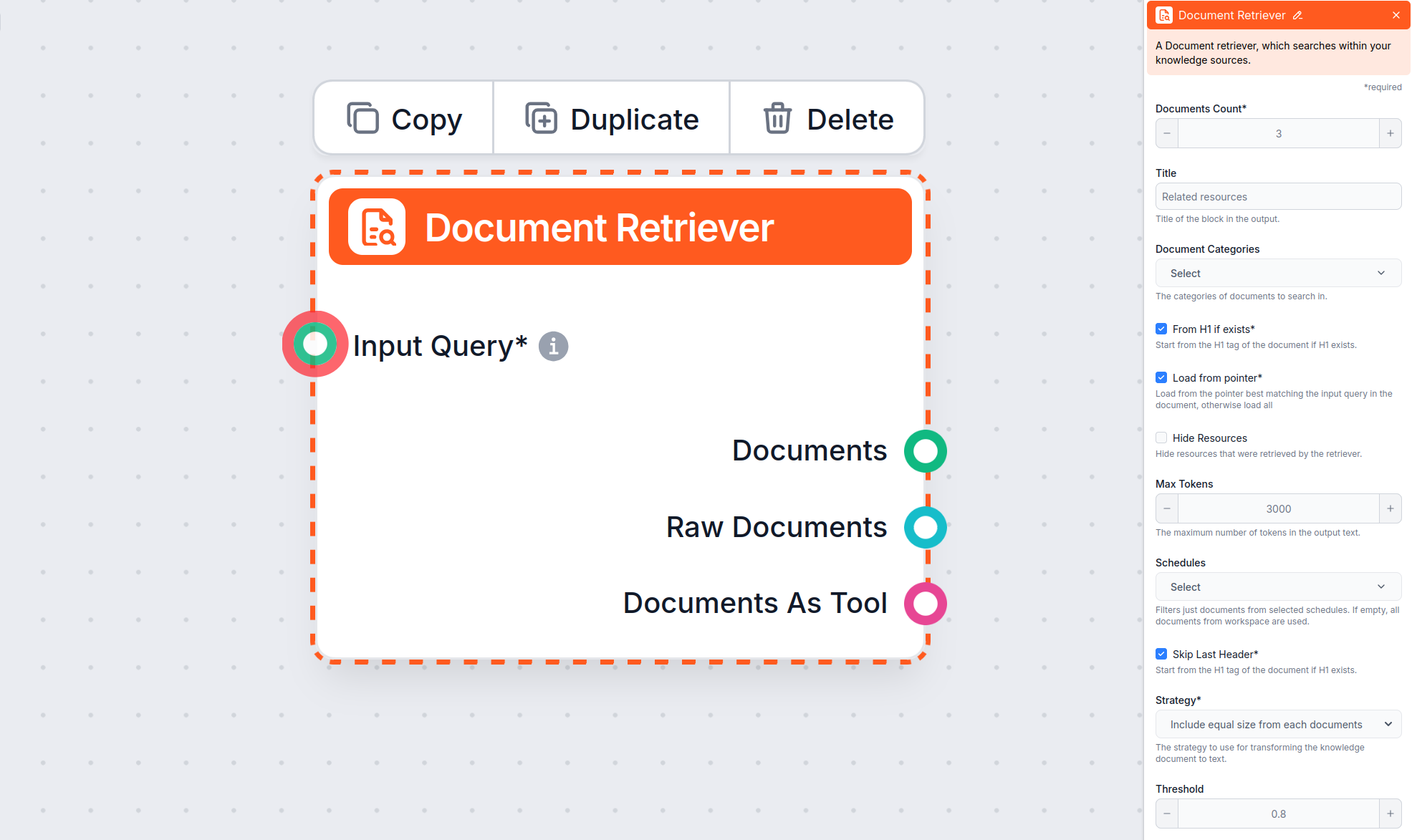
Invoervraag
Geeft de zoekopdracht op waarmee relevante informatie wordt opgezocht. Dit kan worden gekoppeld vanuit een andere component of handmatig worden ingevoerd. In de meeste gevallen is je invoervraag de Chat Input.
Aantal documenten
Deze instelling beperkt het aantal documenten waaruit de flow informatie mag ophalen, zodat de resultaten relevant blijven en niet te lang duren om te genereren.
Documentcategorieën
Met deze optionele instelling kun je de opvraging beperken tot een van de categorieën die je hebt aangemaakt in het Documenten-scherm van Kennisbronnen.
Schema’s
Hiermee kun je de opvraging beperken tot een van de schema’s die je hebt opgegeven in het Schema’s-scherm van Kennisbronnen.
Drempelwaarde
De bronnen in je kennisdatabase komen in meer of mindere mate overeen met de zoekopdracht. AI rangschikt deze op relevantie van 0 tot 1. Met deze instelling bepaal je hoe goed het resultaat moet overeenkomen met de zoekopdracht.
De exacte drempelwaarde hangt af van je toepassing, maar doorgaans wordt 0,7-0,8 aanbevolen voor zeer relevante antwoorden vanuit een redelijk aantal bronnen.
Stel dat je de drempel op 0,6 zet en je hebt de volgende artikelen:
- Artikel A: 0,8
- Artikel B: 0,65
- Artikel C: 0,5
- Artikel D: 0,9
Alleen de artikelen met een relevantiescore boven 0,6 komen in het resultaat, dus alleen A, B en D.
- Een hoge drempel, zoals 0,9, levert zeer relevante resultaten op die sterk overeenkomen met de zoekopdracht, maar het kan lastig zijn om genoeg documenten te vinden en je mist mogelijk relevante informatie.
- Een lage drempel, bijvoorbeeld lager dan 0,5, levert informatie uit meer documenten op, maar het risico bestaat dat er ook irrelevante informatie tussen zit.
Hoe verbind je de Document Retriever-component met je flow
De component heeft slechts één invoer- en één uitvoerhandle:
- Invoervraag: De zoekopdracht kan elke tekstoutput zijn. Veelgebruikte toepassingen zijn het koppelen van menselijke Chat Input of een Generator.
- Uitvoer: De uitvoer van elke retriever-component is altijd een Document.
De Document-uitvoer bevat gestructureerde data die niet geschikt is voor de uiteindelijke chatoutput. Alle componenten die Documenten als invoer accepteren, zetten deze om naar een gebruiksvriendelijk formaat. Dit zijn ofwel Widget-componenten of de Document naar Tekst-converter.
Waarom de Document Retriever gebruiken?
- AI-modellen verankeren: Verbeter de feitelijke juistheid en relevantie van AI-uitvoer door echte, contextuele informatie uit de kennisbank van je organisatie te leveren.
- Contextuele aanvulling: Geef LLM’s of chatbots ondersteunende documenten of referentiemateriaal voor beter geïnformeerde antwoorden.
- Flexibel filteren: De zoekopdracht kan fijn worden afgestemd op categorie, schema, URL, documentstructuur of metadata, zodat je altijd de meest relevante informatie naar boven haalt.
- Aangepaste output: Kies hoeveel inhoud je wilt ophalen, hoe je deze wilt splitsen en welke metadata je wilt meenemen, zodat je eenvoudig kunt aanpassen voor AI-processen verderop of voor de gebruikersinterface.
- Agent-integratie: Dankzij tool-omschrijvingen en naamgeving kan de component als tool worden gebruikt in agent-gebaseerde architecturen.
Voorbeeldtoepassingen
- Retrieval-Augmented Generation (RAG): Voorzie LLM’s van ondersteunende documenten om accurate, kennisgedreven antwoorden te genereren.
- Chatbots en virtuele assistenten: Haal snel veelgestelde vragen of beleidsdocumenten naar voren als antwoord op vragen van medewerkers of klanten.
- Data verrijking: Haal product-, auteur- of andere metadata op voor verdere AI-analyse of workflowautomatisering.
Voorbeeld
Laten we het nu proberen! Voordat we de flow bouwen, moeten we ervoor zorgen dat we relevante Documenten of Schema’s hebben aangemaakt. Als er geen goede bron is, zal de chatbot aangeven dat hij het antwoord niet kan geven.
Stappen:
- Begin met Chat Input.
- Voeg de Document Retriever toe en verbind Chat Input als de Invoervraag.
- De output is een Document dat getransformeerd moet worden; voor dit voorbeeld gebruiken we Document naar Tekst.
- Verbind vervolgens een AI Generator.
- Je bent klaar om te chatten.
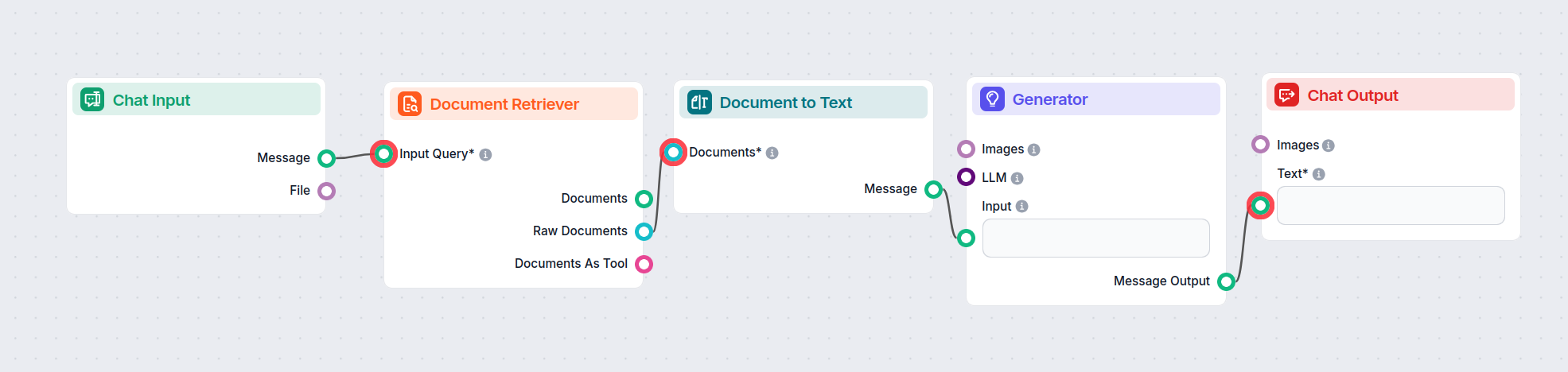
Nu kan onze Flow zoeken in onze bronnen op basis van een menselijke vraag, de gestructureerde data omzetten in leesbare tekst en deze doorgeven aan AI om een gebruiksvriendelijk antwoord te genereren.
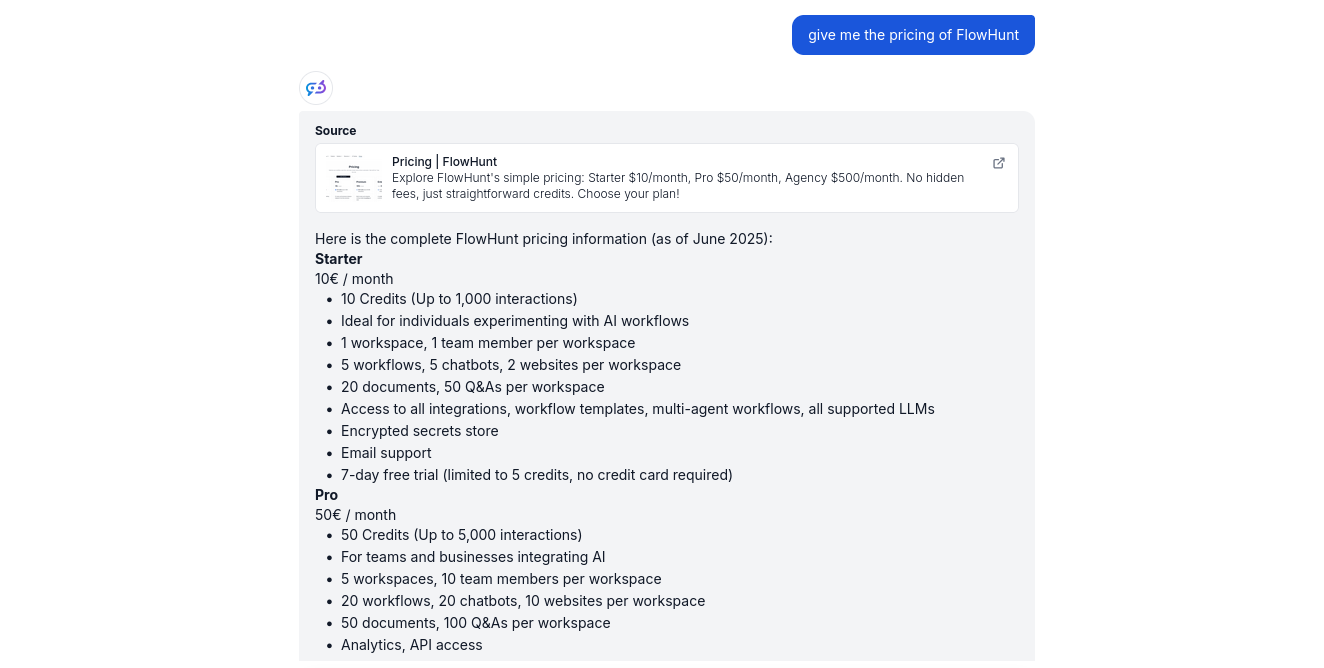
Onze Kennisbronnen bevatten een schema dat de FlowHunt-prijspagina crawlt voor actuele informatie. Laten we de bot ernaar vragen:
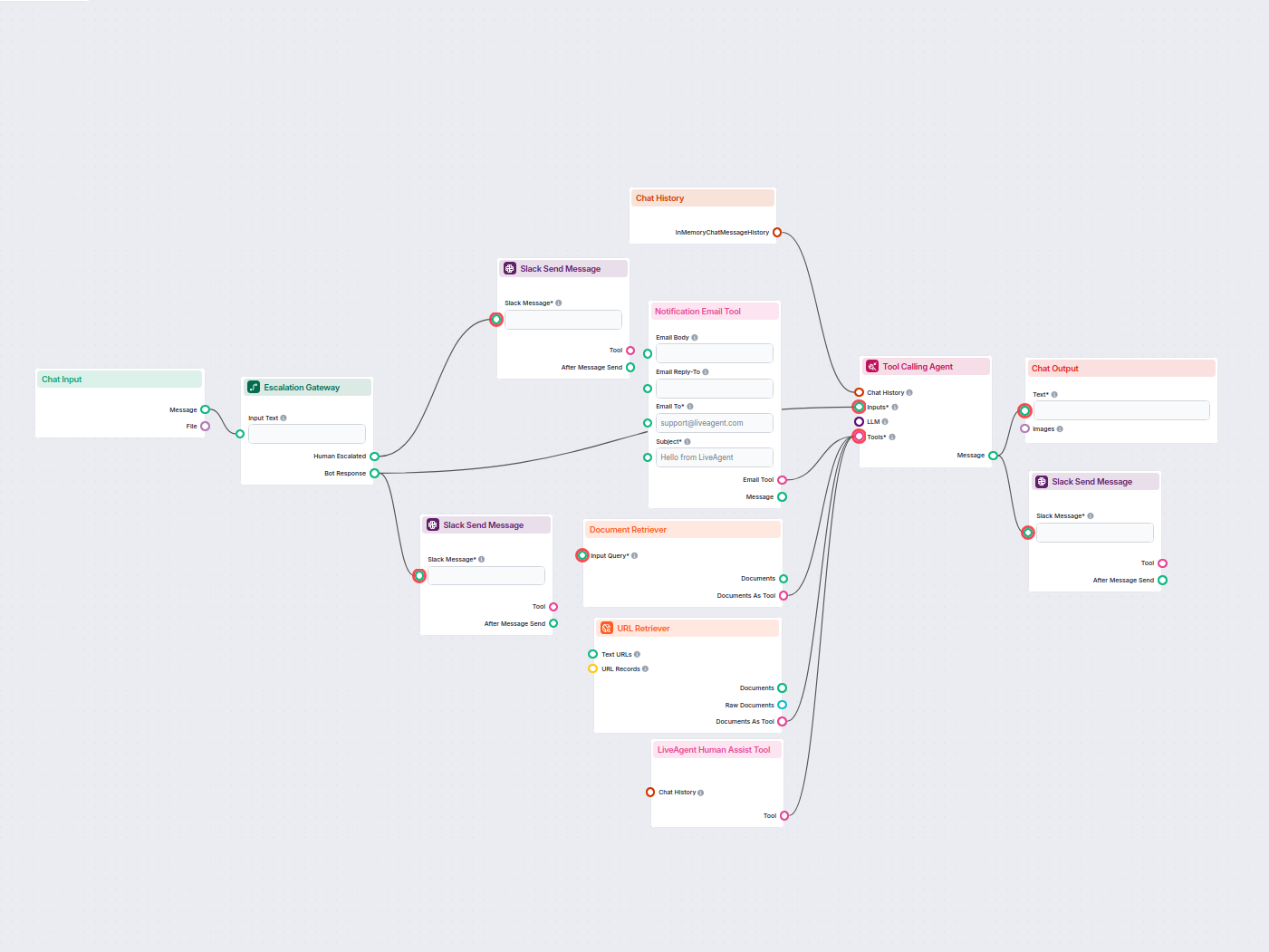
Voorbeelden van flowsjablonen met Document Retriever-component
Om u snel op weg te helpen, hebben we verschillende voorbeeld-flowsjablonen voorbereid die laten zien hoe u de Document Retriever-component effectief kunt gebruiken. Deze sjablonen tonen verschillende gebruikscases en best practices, waardoor het voor u gemakkelijker wordt om de component te begrijpen en te implementeren in uw eigen projecten.
















Veelgestelde vragen
- Wat is de Document Retriever-component?
Met deze component kan de Flow kennis ophalen uit je eigen bronnen, zoals documenten en URL's. Zo weet je zeker dat de teruggegeven informatie relevant, betrouwbaar en actueel is.
- Waarom kan ik geen Document Retriever verbinden met Chat Output?
Retriever-componenten maken gestructureerde data aan die niet geschikt is voor output. Deze moet eerst worden omgezet naar tekst of visueel formaat voordat je deze naar de Chat Output-component stuurt.
- Waar haalt de Knowledge Retriever zijn informatie vandaan?
De component zoekt naar de beste overeenkomst met je zoekopdracht binnen de informatie uit door de gebruiker opgegeven URL's, documenten en schema's.
- Hoeveel documenten worden er teruggegeven?
Je kunt een limiet instellen voor het aantal resultaten dat wordt teruggegeven, zodat alleen de meest relevante inhoud in je flow wordt opgenomen.
- Kan ik filteren op welke documenten worden doorzocht?
Ja, je kunt filteren op documentcategorieën, schema's of URL's, zodat je de zoekopdracht kunt richten op specifieke delen van je kennisbank.
- Kan ik zowel de Document Retriever als GoogleSearch koppelen? Zo ja, welke heeft dan voorrang?
Je kunt beide tegelijkertijd gebruiken. Elke retriever heeft een eigen output, waarbij de prioriteit wordt bepaald door de volgorde van outputs op het canvas. De eerste output van boven krijgt voorrang.
Probeer FlowHunt's Document Retriever
Bouw slimmere AI-oplossingen door je kennisbronnen te koppelen en ervoor te zorgen dat je chatbot altijd relevante, actuele antwoorden geeft.
Meer informatie