Trefwoordfrequentie Evaluator
De Trefwoordfrequentie Evaluator identificeert en retourneert de meest relevante trefwoorden uit één of meerdere teksten, met opties om stopwoorden uit te sluiten en te focussen op trefwoorden die overlappen in bronnen.
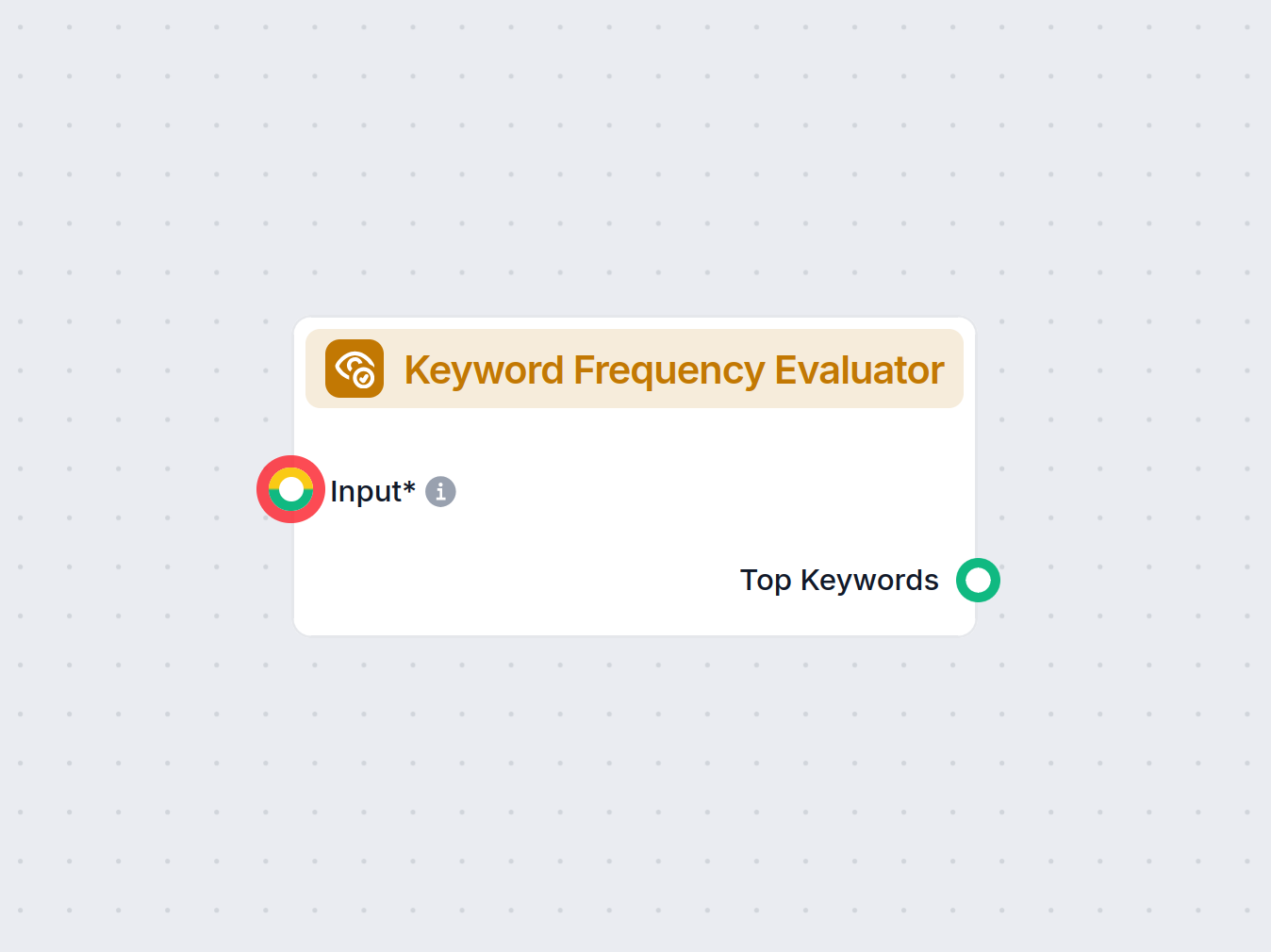
Componentbeschrijving
Hoe de Trefwoordfrequentie Evaluator-component werkt
Trefwoordfrequentie Evaluator
De Trefwoordfrequentie Evaluator is een component die is ontworpen om één of meerdere teksten te analyseren en de belangrijkste trefwoorden te identificeren op basis van hun frequentie en andere instelbare criteria. Dit maakt het bijzonder nuttig voor het extraheren van hoofdonderwerpen, het uitvoeren van inhoudsanalyse of het voorbereiden van data voor vervolg-AI-taken zoals samenvatten, clusteren of zoeken.
Wat doet deze component?
Deze component neemt een lijst van tekstinvoeren (zoals documenten, berichten of URL-records), verwerkt deze en geeft een gerangschikte lijst van de meest frequente en relevante trefwoorden die in de ingevoerde data voorkomen. Er zijn verschillende opties om het extractieproces te verfijnen, zoals het uitsluiten van stopwoorden, focussen op trefwoorden die in meerdere teksten voorkomen en het beheersen van de omvang en lengte van geëxtraheerde trefwoorden.
Invoer
De component biedt de volgende instelbare invoeropties:
| Invoernaam | Type | Standaardwaarde | Omschrijving |
|---|---|---|---|
| Invoer | Lijst van teksten | - | De hoofdtekst(en) om te analyseren. Accepteert UrlRecord, Bericht of Document types. |
| Stopwoorden uitsluiten | Boolean | true | Indien ingeschakeld, worden veelvoorkomende stopwoorden (zoals “de”, “en”, enz.) uitgesloten. |
| Alleen overlappende | Boolean | true | Indien ingeschakeld, worden alleen trefwoorden geretourneerd die in meer dan één tekst voorkomen. |
| Maximaal aantal trefwoorden | Integer | 50 | Het maximale aantal trefwoorden dat in de uiteindelijke uitvoer wordt teruggegeven. |
| Minimale frequentie | Integer | 3 | Minimaal aantal keer dat een woord moet voorkomen om als trefwoord te gelden. |
| Minimale woordlengte | Integer | 3 | Het minimale aantal karakters dat een woord moet hebben om als trefwoord te gelden. |
| Qgrams | Multi-select (1-6) | 2, 3, 4 | De grootte(n) van woordreeksen (n-grams) die meegenomen worden bij het extraheren van trefwoorden. |
Belangrijkste kenmerken
- Flexibele invoer: Werkt met verschillende soorten tekstrecords en ondersteunt batchverwerking.
- Geavanceerd filteren: Verfijn de uitvoer door stopwoorden uit te sluiten en minimale woordlengte en frequentiedrempels in te stellen.
- Beheer de uitvoergrootte: Beperk het aantal geretourneerde trefwoorden om te focussen op de meest prominente termen.
- N-gram ondersteuning: Extraheer meerwoordige zinnen (Q-grams), niet alleen losse trefwoorden, voor rijkere semantische inzichten.
- Overlappende trefwoorden: Optioneel kun je focussen op trefwoorden die in meerdere documenten gemeenschappelijk zijn voor vergelijkende analyses.
Uitvoer
De component levert de volgende uitvoer:
- Top trefwoorden:
Een lijst van de meest significante trefwoorden (als eenBerichttype), op basis van de extractielogica en ingestelde parameters. Deze uitvoer kan gebruikt worden voor verdere verwerking of visualisatie in je AI-workflow.
Voorbeeldtoepassingen
- Documenten samenvatten: Snel de hoofdonderwerpen in een set documenten identificeren.
- Inhoud clusteren: Gebruik geëxtraheerde trefwoorden om vergelijkbare documenten of berichten te groeperen.
- Zoeken en indexeren: Genereer indextermen voor efficiënte terugvindbaarheid in informatiesystemen.
- Trendanalyses: Volg terugkerende thema’s in communicatie-logs of datasets.
Waarom is dit nuttig?
De Trefwoordfrequentie Evaluator stroomlijnt het proces van het extraheren van betekenisvolle termen uit grote of meerdere tekstbestanden. Door gedetailleerde configuratie aan te bieden, past het zich aan uiteenlopende behoeften aan—van eenvoudige trefwoordextractie tot geavanceerde vergelijkende analyses. Als onderdeel van een AI-workflow maakt het mogelijk dat vervolgstappen gebruik kunnen maken van compacte, informatieve representaties van je tekstdata, wat efficiëntie en uitlegbaarheid ten goede komt.
Voorbeelden van flowsjablonen met Trefwoordfrequentie Evaluator-component
Om u snel op weg te helpen, hebben we verschillende voorbeeld-flowsjablonen voorbereid die laten zien hoe u de Trefwoordfrequentie Evaluator-component effectief kunt gebruiken. Deze sjablonen tonen verschillende gebruikscases en best practices, waardoor het voor u gemakkelijker wordt om de component te begrijpen en te implementeren in uw eigen projecten.

Veelgestelde vragen
- Wat doet de Trefwoordfrequentie Evaluator?
Deze analyseert ingevoerde teksten om de meest frequente en relevante trefwoorden te extraheren, zodat je snel belangrijke onderwerpen en termen kunt identificeren.
- Kan ik veelvoorkomende woorden uitsluiten van de resultaten?
Ja, je kunt automatisch stopwoorden uitsluiten zodat alleen betekenisvolle trefwoorden getoond worden.
- Is het mogelijk om te focussen op trefwoorden die in meerdere teksten voorkomen?
Ja, de component kan zo ingesteld worden dat alleen trefwoorden die in meer dan één tekst voorkomen worden weergegeven.
- Hoe aanpasbaar is de trefwoordextractie?
Je kunt parameters aanpassen zoals minimale frequentie, woordlengte, maximaal aantal trefwoorden en de grootte van q-grams voor nauwkeurige resultaten.
- Welke invoerformaten worden ondersteund?
Het werkt met URL's, berichten en documenten, en biedt zo flexibiliteit voor verschillende contenttypes.
Probeer de Trefwoordfrequentie Evaluator
Versterk je workflows met slimme trefwoordextractie—begin vandaag nog met bouwen met de Trefwoordfrequentie Evaluator in FlowHunt.
Meer informatie