Document naar Tekst
Zet gestructureerde data om in leesbare markdown-tekst met FlowHunt’s Document naar Tekst-component, die aanpasbare controles biedt voor efficiënte en relevante AI-aangedreven output.
Componentbeschrijving
Hoe de Document naar Tekst-component werkt
AI kan grote hoeveelheden data in seconden analyseren, maar slechts een deel van die data zal relevant of geschikt zijn voor output. De Document naar Tekst-component geeft je controle over hoe de gegevens uit retrievers worden verwerkt en omgezet naar tekst.
Document naar Tekst-component
De Document naar Tekst-component is ontworpen om invoer van kennisdocumenten om te zetten in platte tekst. Dit is vooral handig in AI- en gegevensverwerkingsworkflows waarbij tekstuele data nodig is voor verdere verwerking, analyse of als invoer voor taalmodellen.
Wat doet de component?
Deze component neemt één of meerdere gestructureerde documenten (zoals HTML, Markdown, PDF’s of andere ondersteunde formaten) en extraheert de tekstuele inhoud. Je kunt precies aangeven welke delen van de documenten geëxporteerd moeten worden, of metadata moet worden opgenomen en hoe om te gaan met documentsecties of koppen. De uitvoer is een gecombineerd berichtobject met de geëxtraheerde tekst, klaar voor vervolgtaken zoals samenvatten, classificeren of vraagbeantwoording.
Invoer
De component accepteert verschillende configureerbare invoervelden:
| Invoerveldnaam | Type | Vereist | Beschrijving | Standaardwaarde |
|---|---|---|---|---|
| Documenten | Lijst[Document] | Ja | De kennisdocumenten die naar tekst omgezet moeten worden. | N.v.t. (door gebruiker geleverd) |
| Vanaf H1 indien aanwezig | Boolean | Ja | Start extractie vanaf de eerste H1-kop indien aanwezig. | true |
| Laden vanaf pointer | Boolean | Ja | Start extractie vanaf de pointer die het beste bij de invoervraag past, of laad alles indien geen match. | true |
| Max Tokens | Integer | Nee | Maximum aantal tokens in de uitvoertekst. | 3000 |
| Sla laatste kop over | Boolean | Ja | Sla de laatste kop (vaak een footer) over om de output te optimaliseren. | false |
| Strategie | String | Ja | Tekstextractiestrategie: documenten samenvoegen of gelijke grootte uit elk document opnemen. | “Gelijke grootte uit elk document opnemen” |
| Inhoud exporteren | Multi-select | Nee | Welke type inhoud opnemen (bijv. H1, H2, Paragraaf). | Alle typen geselecteerd |
| Metadata opnemen | Multi-select | Nee | Metadata-velden om in de output op te nemen indien beschikbaar. | Product |
Beschikbare inhoudstypen: H1, H2, H3, H4, H5, H6, Paragraaf
Metadata-opties: Auteur, Product, BreadcrumbList, VideoObject, BlogPosting, FAQPage, WebSite, opengraph
Uitvoer
De component levert het volgende op:
- Bericht: Een berichtobject met de omgezette tekst en eventuele opgenomen metadata.
Belangrijkste kenmerken & nut
- Flexibele inhoudsextractie: Bepaal precies welke delen van je documenten worden geëxtraheerd (bijv. alleen hoofdheaders en paragrafen, of alle inhoud).
- Metadata opnemen: Voeg optioneel rijke metadata toe (bijv. auteur, product of gestructureerde data) aan de output, handig voor contextuele verwerking verderop.
- Beheer van tokenlimiet: Beperk de outputgrootte zodat deze past bij de vereisten van vervolgmodellen via een maximaal tokenaantal.
- Aangepaste extractiestrategie:
- Documenten samenvoegen, vullen vanaf de eerste tot de tokenlimiet: Prioriteert het sequentieel vullen van de output vanuit het eerste document.
- Gelijke grootte uit elk document opnemen: Verdeelt de inhoud van meerdere documenten binnen de tokenlimiet.
- Slim omgaan met secties: Opties om footers over te slaan of te starten vanaf het meest relevante gedeelte voor je vraag, waardoor de relevantie van de geëxtraheerde tekst toeneemt.
Typische toepassingsscenario’s
- Voorbewerken van kennisbanken voor AI-modellen (bijv. vóór embedding of indexering).
- Samenvatten of inkorten van grote documenten door alleen relevante secties te extraheren.
- Gestructureerde inhoud voeden aan chatbots, zoekmachines of andere natural language processing pipelines.
- Hybride retrieval-systemen bouwen die tekst combineren met metadata voor meer context.
Samenvattende tabel
| Mogelijkheid | Beschrijving |
|---|---|
| Invoertypen | Lijst van documenten |
| Uitvoertype | Bericht (Tekst + Metadata) |
| Inhoudsniveau | Selecteer koppen/paragrafen om op te nemen |
| Metadata-opties | Meerdere metadata-velden selecteren om te exporteren |
| Outputgrootte beheren | Stel max tokens in |
| Extractiestrategieën | Samenvoegen of balanceren over documenten |
| Selectie van secties | Start vanaf H1, vanaf pointer, of sla laatste kop over |
Strategie
De bot kan veel documenten doorzoeken om de tekstoutput te genereren. Met de instelling Strategie bepaal je hoe de bot deze documenten slim benut binnen de ingestelde tokenlimiet.
Er zijn momenteel twee mogelijke strategieën:
- Gelijke grootte uit elk document opnemen: Benut alle gevonden documenten evenredig.
- Documenten samenvoegen, vullen vanaf de eerste tot de tokenlimiet: Verbindt de documenten en prioriteert ze op relevantie voor de vraag.
Hoe koppel je de Document naar Tekst-component aan je flow
Dit is een transformercomponent, wat betekent dat hij de brug vormt tussen twee outputs. Document naar Tekst verwerkt Documenten die door Retriever-componenten zijn geleverd:
- Document Retriever – haalt kennis op uit gekoppelde kennisbronnen (pagina’s, documenten, enz.).
- URL Retriever – Hiermee kun je een URL specificeren waaruit de bot kennis moet halen.
- GoogleSearch – Geeft de bot de mogelijkheid om het web te doorzoeken naar kennis.
De kennis wordt tijdens het transformeren omgezet naar leesbare Markdown-tekst. Deze tekst kan vervolgens worden gekoppeld aan componenten die tekstinvoer vereisen, zoals splitters, widgets of outputs.
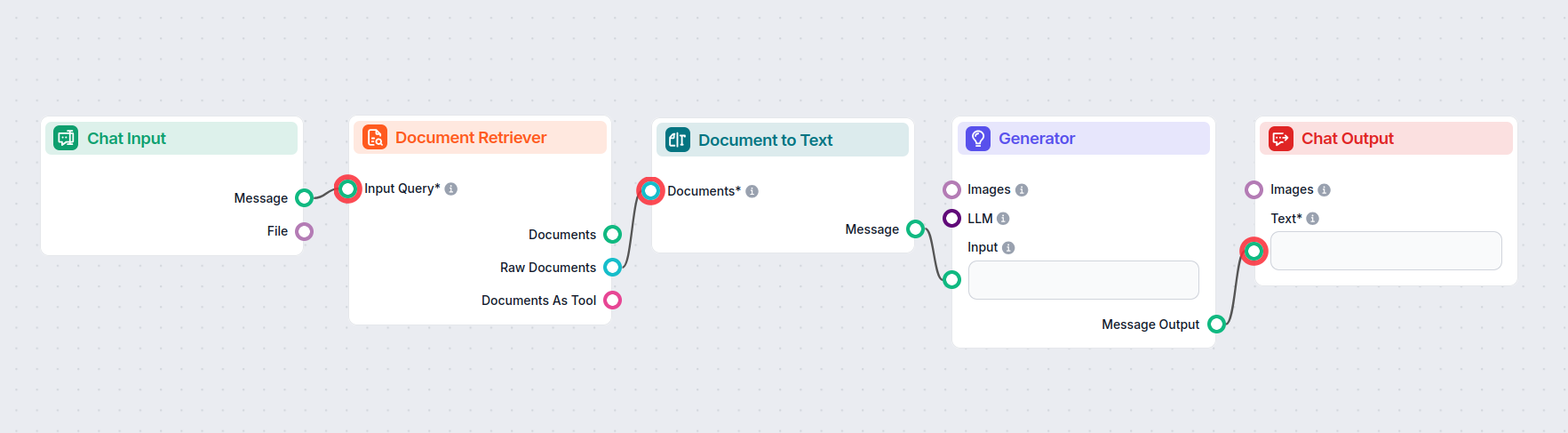
Hieronder een voorbeeldflow waarin de Document naar Tekst-component de brug vormt tussen de Document Retrievers en de AI Generator:
Veelgestelde vragen
- Wat is de Document naar Tekst-component?
De component haalt kennis op via retriever-achtige componenten en zet deze om in leesbare markdown-tekst, die vervolgens kan worden gekoppeld aan elke component die tekst als invoer accepteert.
Probeer Document naar Tekst in FlowHunt
Begin met het bouwen van slimmere AI-oplossingen met de Document naar Tekst-component van FlowHunt. Zet moeiteloos data om in bruikbare tekst en verbeter je geautomatiseerde workflows.
Meer informatie