URL Retriever
Met de URL Retriever kun je inhoud van weblinks ophalen en verwerken, met ondersteuning voor OCR, metadata-extractie en flexibele output voor AI-workflows.
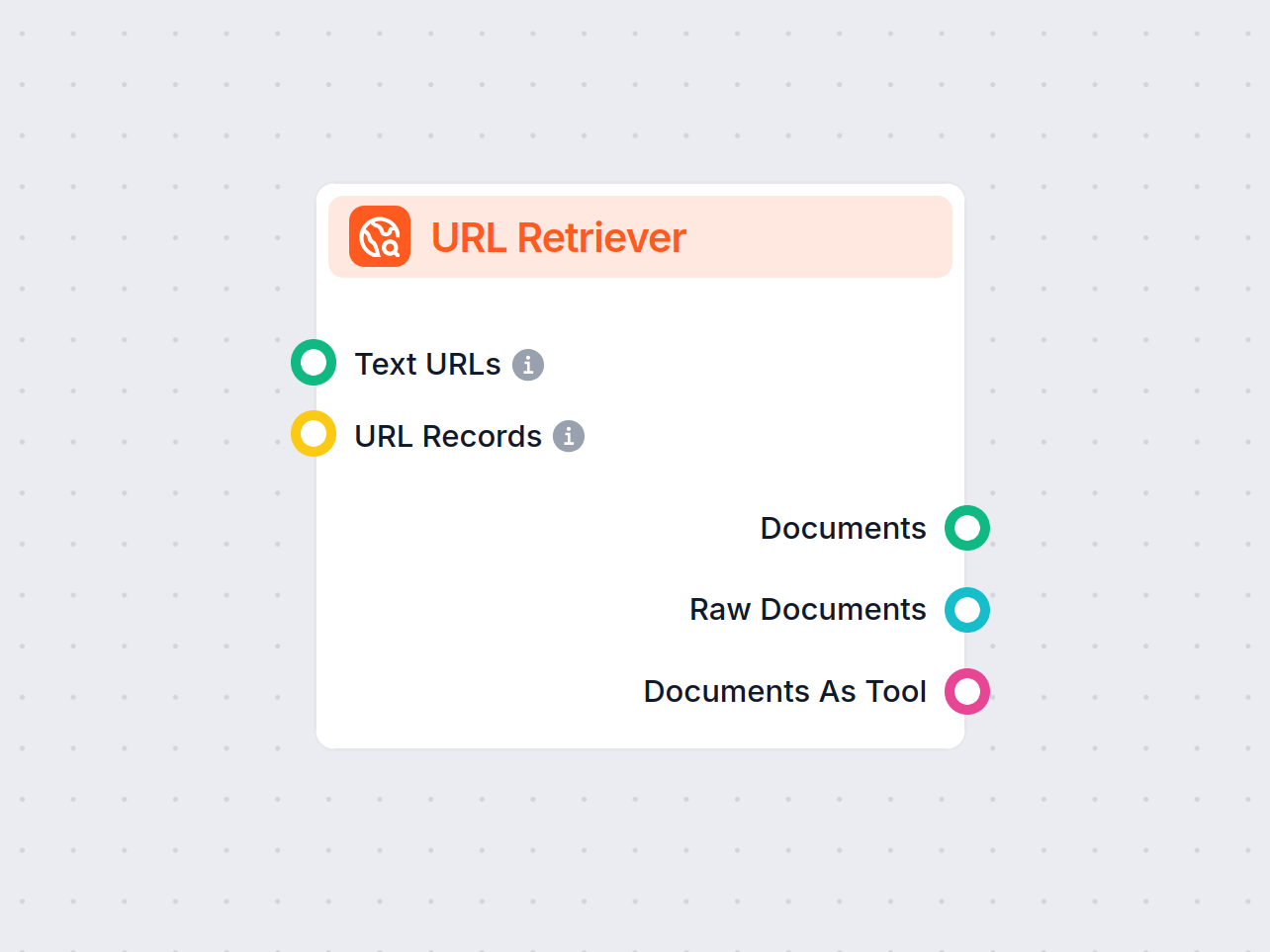
Componentbeschrijving
Hoe de URL Retriever-component werkt
URL Retriever-component
De URL Retriever is een veelzijdige flowcomponent die is ontworpen om webinhoud van opgegeven URL’s op te halen en te verwerken, en deze informatie terug te geven als gestructureerde documenten. Het vormt een brug tussen externe online inhoud en je AI-workflow, waardoor je webgebaseerde informatie efficiënt kunt integreren, analyseren of verwerken.
Wat doet het?
Deze component haalt de inhoud op van één of meerdere URL’s die als input worden meegegeven. Het kan de hoofdtekst, metadata en zelfs inhoud uit afbeeldingen halen met behulp van Optical Character Recognition (OCR). De opgehaalde data wordt vervolgens beschikbaar gesteld in diverse gestructureerde formaten, geschikt voor AI-taken zoals samenvatten, vraagbeantwoording of kennisextractie.
Invoeropties
Je kunt URL’s op twee manieren aanleveren aan de component:
Tekst-URL’s:
- Input Type:
Message - Beschrijving: Een lijst met gewone URL-links waarvan de component inhoud moet ophalen.
- Input Type:
URL Records:
- Input Type:
UrlRecord - Beschrijving: Een lijst van gestructureerde URL-gegevens, die extra metadata kunnen bevatten.
- Input Type:
Geavanceerde invoerparameters
| Parameter | Type | Standaard | Beschrijving |
|---|---|---|---|
| OCR toepassen | Boolean | false | Indien ingeschakeld, past OCR toe om tekst uit afbeeldingen in het document te halen. |
| Cache TTL | Dropdown | 2 weken | Hoe lang de inhoud moet worden gecached, met opties van geen cache tot 1 jaar. |
| Vanaf H1 indien aanwezig | Boolean | true | Start extractie vanaf de H1-tag indien aanwezig, met focus op hoofdinhoud. |
| Laden vanaf pointer | Boolean | true | Laadt inhoud vanaf het meest relevante gedeelte op basis van je query. |
| Bronnen verbergen | Boolean | false | Verbergt de opgehaalde bronnen voor output of weergave. |
| Max tokens | Integer | 3000 | Stelt het maximaal aantal tokens voor de outputtekst in. |
| Laatste kop overslaan | Boolean | true | Slaat de laatste kop over bij extractie voor gestroomlijnde inhoud. |
| Strategie | Dropdown | Include equal size from each documents | Bepaalt hoe inhoud wordt gecombineerd: volledig samenvoegen of gelijke delen van elk document opnemen. |
| Inhoud exporteren | Multi-select | All | Kies welke HTML-elementen geëxporteerd moeten worden (H1-H6, Paragraaf). |
| Metadata opnemen | Multi-select | Product | Geef aan welke metadata-velden moeten worden opgenomen (bijv. Product, Auteur, Website, enz.). |
| Uitgebreid | Boolean | false | Schakelt gedetailleerde output in voor debugging of informatieve doeleinden. |
| Toolnaam | String | (leeg) | Geef optioneel een aangepaste naam aan de tool voor agent-referentie. |
| Toolbeschrijving | Multiline | (leeg) | Voeg een beschrijving toe om agents te helpen het doel van de tool te begrijpen. |
Uitvoer
De URL Retriever levert zijn output in verschillende formaten, zodat je flexibel kunt integreren met diverse AI-processen:
| Uitvoernaam | Type | Beschrijving |
|---|---|---|
| Documenten | Message | De verwerkte inhoud van de URL’s, klaar voor gebruik in berichtgeoriënteerde workflows. |
| Ruwe documenten | Document | De ruwe, onverwerkte documentobjecten voor geavanceerde verdere verwerking. |
| Documenten als tool | Tool | De inhoud verpakt als een tool, waardoor agentgebaseerde workflows de documenten kunnen gebruiken. |
Waarom de URL Retriever gebruiken?
- Externe kennis integreren: Breng webgebaseerde informatie naadloos naar je AI-toepassingen, zoals chatbots, zoekmachines of kennisbanken.
- Aanpasbare extractie: Bepaal zelf welke inhoud en metadata je wilt, beheer de hoeveelheid data en gebruik OCR voor afbeeldingen.
- Prestaties & efficiëntie: Gebruik caching om dubbele downloads te voorkomen en beperk het aantal tokens voor betere prestaties.
- Flexibele outputformaten: Kies het outputformaat dat het beste past bij jouw volgende workflowstap—gestructureerd document, bericht of tool.
Voorbeeldtoepassingen
- Het bouwen van kennisgedreven conversatie-agents die vragen beantwoorden met up-to-date webinhoud.
- Productdata verzamelen van e-commercesites voor vergelijking of analyse.
- Blogs of nieuwsartikelen monitoren en analyseren op basis van specifieke onderwerpen of trefwoorden.
- Informatie extraheren van webpagina’s met gemengde media (tekst en afbeeldingen).
Samenvattingstabel
| Functie | Beschrijving |
|---|---|
| URL’s ophalen | Haalt webinhoud op en verwerkt deze van opgegeven URL’s. |
| OCR-ondersteuning | Extraheert tekst uit afbeeldingen in documenten indien ingeschakeld. |
| Metadata-extractie | Voegt optioneel metadata toe zoals auteur, product of schema.org-typen. |
| Aanpasbare output | Selecteer welke HTML-elementen of metadata geëxporteerd moeten worden. |
| Caching | Instelbare cachelevensduur voor efficiëntie. |
| Meerdere outputtypes | Ondersteunt bericht-, ruwe document- en tooloutput voor workflowflexibiliteit. |
De URL Retriever is een krachtige en flexibele brug tussen webinhoud en je AI-workflows, met gedetailleerde controle over extractie en integratie van inhoud.
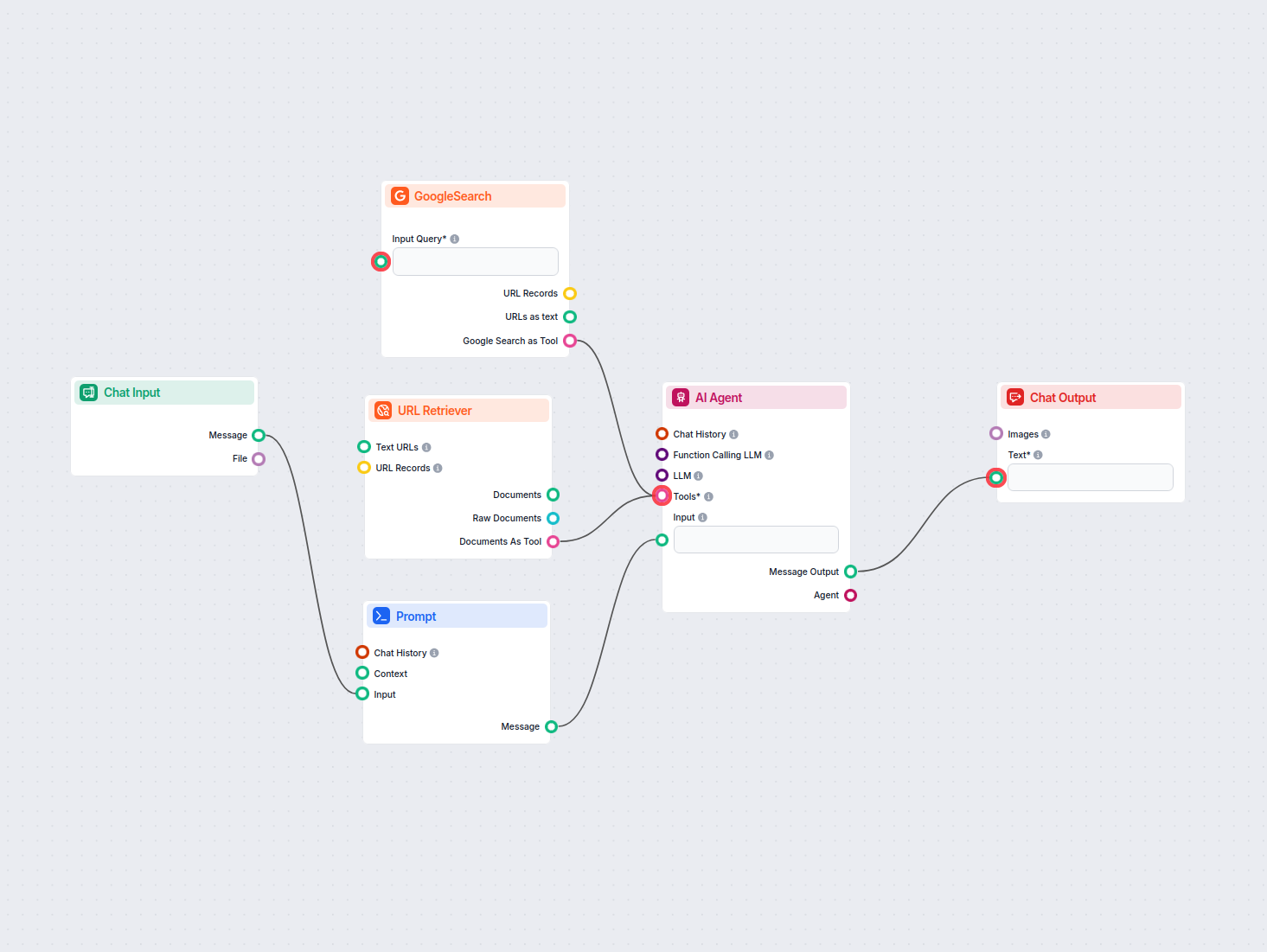
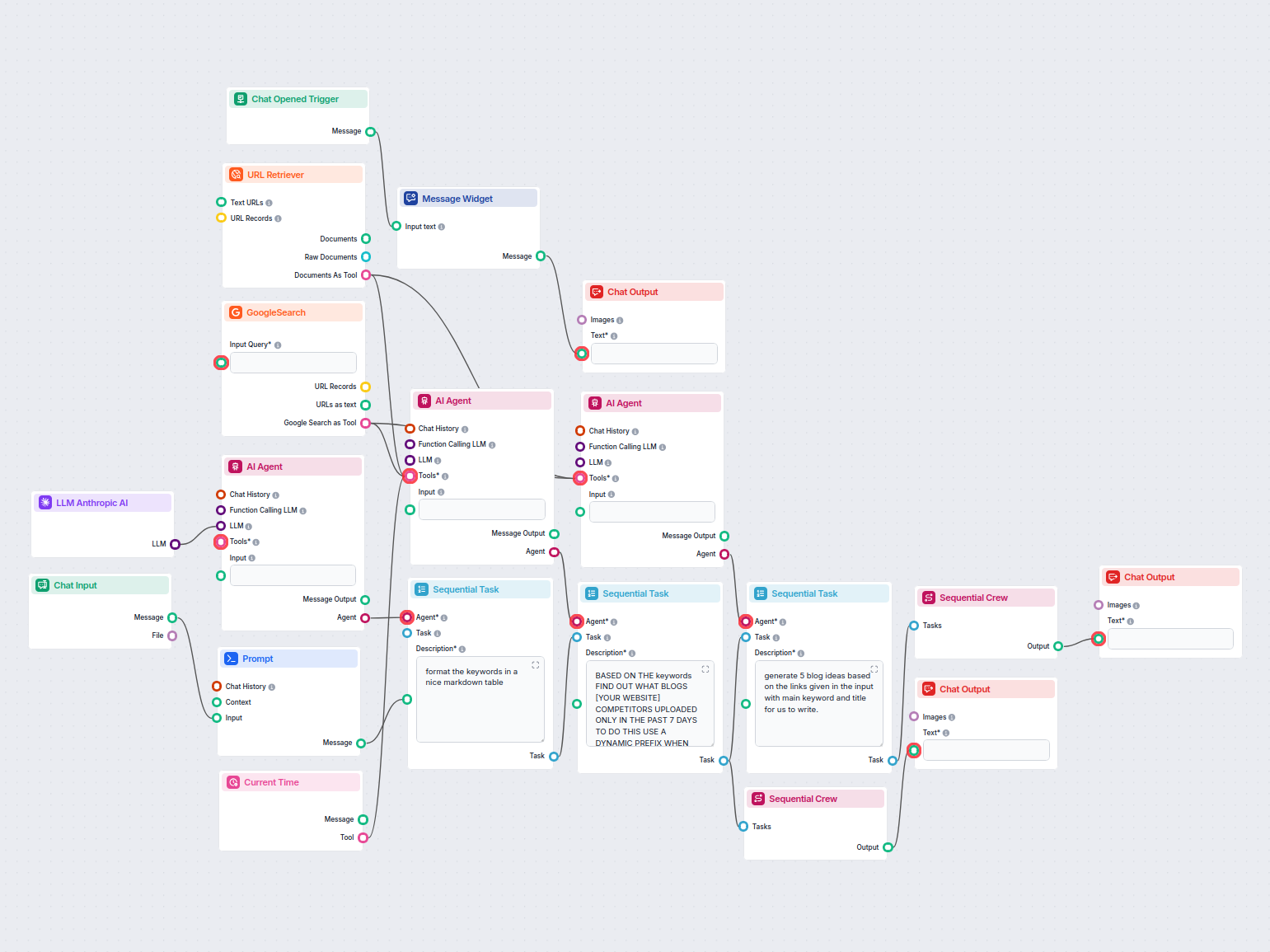
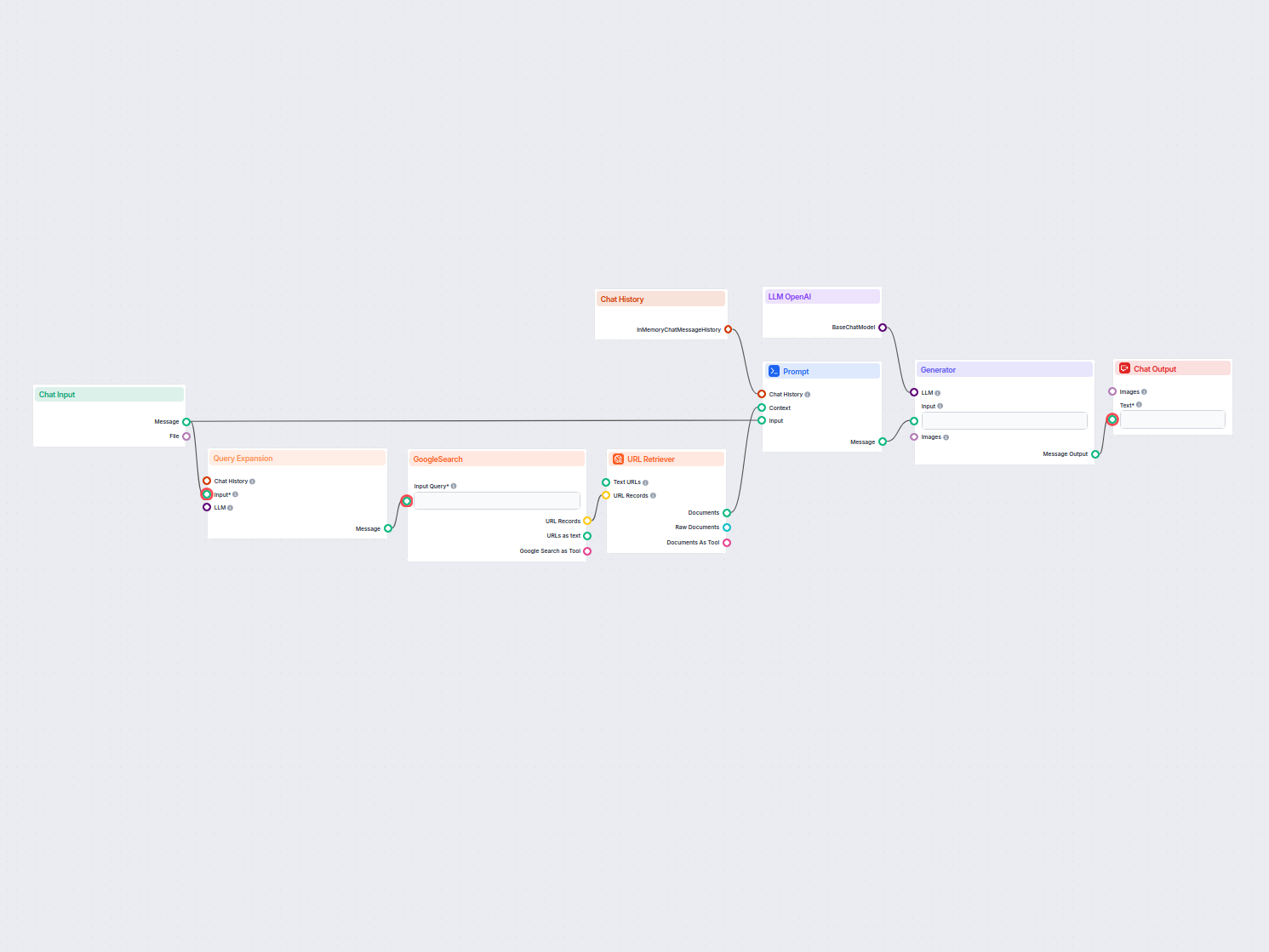
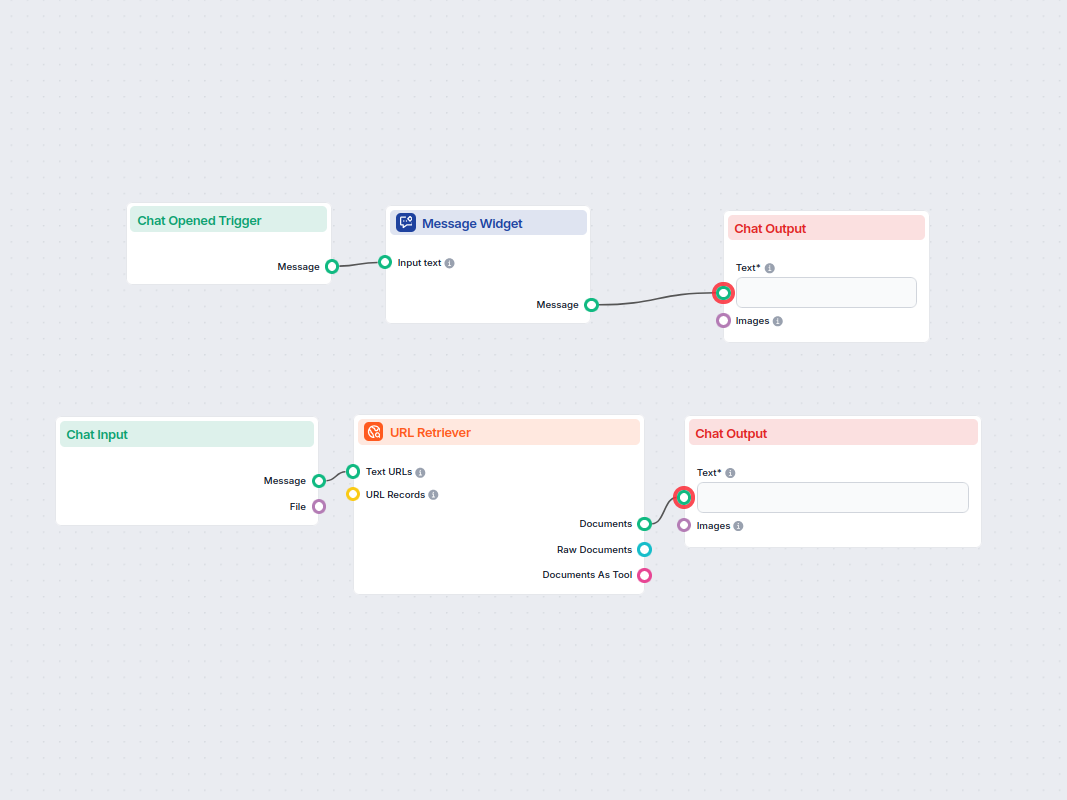
Voorbeelden van flowsjablonen met URL Retriever-component
Om u snel op weg te helpen, hebben we verschillende voorbeeld-flowsjablonen voorbereid die laten zien hoe u de URL Retriever-component effectief kunt gebruiken. Deze sjablonen tonen verschillende gebruikscases en best practices, waardoor het voor u gemakkelijker wordt om de component te begrijpen en te implementeren in uw eigen projecten.



















































Veelgestelde vragen
- Wat doet de URL Retriever-component?
De URL Retriever haalt inhoud op van opgegeven weblinks en verwerkt deze, waardoor tekst en metadata van online documenten beschikbaar worden voor je workflow of AI-agent.
- Kan het inhoud uit afbeeldingen of PDF's halen?
Ja, door de OCR-optie in te schakelen, kan de component tekst uit afbeeldingsgebaseerde documenten of gescande PDF's halen.
- Welke soorten output geeft het?
Het levert verwerkte documenten als tekstberichten, ruwe documentobjecten of als tool voor agent-workflows, afhankelijk van je instellingen.
- Hoe werkt caching in URL Retriever?
Je kunt instellen hoelang opgehaalde inhoud wordt gecached, waardoor herhaalde downloads worden verminderd en je flows worden versneld.
- Kan ik bepalen welke delen van een webpagina worden geëxtraheerd?
Ja, je kunt specificeren welke koppen, paragrafen of metadata-velden moeten worden opgenomen in de output, voor gerichte extractie.
- Is dit geschikt voor het bouwen van kennisbots of webdata-automatiseringen?
Absoluut. De URL Retriever is essentieel voor elke automatisering of chatbot die live webinhoud moet lezen, verwerken of samenvatten.
Probeer FlowHunt URL Retriever
Versnel je workflows door live webinhoud te integreren. Extraheer, verwerk en gebruik data van URL's met gemak.
Meer informatie