Inbeddingsvector
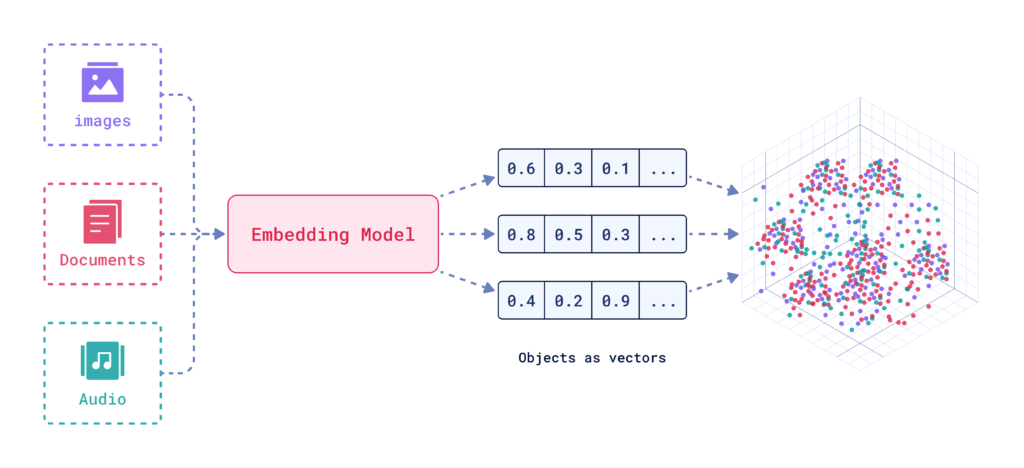
Een inbeddingsvector geeft data numeriek weer in een multidimensionale ruimte, waardoor AI-systemen semantische relaties kunnen vastleggen voor taken als classificatie, clusteren en aanbevelingen.
Een inbeddingsvector is een compacte numerieke representatie van data waarbij elk stukje data wordt gekoppeld aan een punt in een multidimensionale ruimte. Deze mapping is ontworpen om de semantische informatie en contextuele relaties tussen verschillende datapunten vast te leggen. Soortgelijke datapunten worden dichter bij elkaar gepositioneerd in deze ruimte, wat taken als classificatie, clusteren en aanbevelingen vergemakkelijkt.
Definiëren van inbeddingsvectoren
Inbeddingsvectoren zijn in wezen arrays van getallen die de intrinsieke eigenschappen en relaties van de data die ze vertegenwoordigen samenvatten. Door complexe datatypes om te zetten in deze vectoren kunnen AI-systemen diverse bewerkingen efficiënter uitvoeren.
Belang en toepassingen
Inbeddingsvectoren vormen de basis voor veel AI- en ML-toepassingen. Ze vereenvoudigen de representatie van hoog-dimensionale data, waardoor analyse en interpretatie eenvoudiger wordt.
1. Natural Language Processing (NLP)
- Woordinbeddingen: Technieken zoals Word2Vec en GloVe zetten individuele woorden om in vectoren, waarbij semantische relaties en contextuele informatie worden vastgelegd.
- Zinsinbeddingen: Modellen zoals Universal Sentence Encoder (USE) genereren vectoren voor volledige zinnen, waarmee de algemene betekenis en context worden vastgelegd.
- Documentinbeddingen: Technieken zoals Doc2Vec representeren volledige documenten als vectoren, waarbij de semantische inhoud en context worden gevangen.
2. Beeldverwerking
- Beeldinbeddingen: Convolutionele neurale netwerken (CNN’s) en voorgetrainde modellen zoals ResNet genereren vectoren voor afbeeldingen, waarbij verschillende visuele kenmerken worden vastgelegd voor taken zoals classificatie en objectherkenning.
3. Aanbevelingssystemen
- Gebruikersinbeddingen: Deze vectoren geven gebruikersvoorkeuren en -gedrag weer, waardoor gepersonaliseerde aanbevelingen mogelijk zijn.
- Productinbeddingen: Vectoren die de kenmerken en eigenschappen van een product vastleggen, waardoor productvergelijking en aanbeveling worden vergemakkelijkt.
Hoe worden inbeddingsvectoren gecreëerd
Het creëren van inbeddingsvectoren omvat verschillende stappen:
- Dataverzameling: Verzamel een grote dataset die relevant is voor het type inbeddingen dat je wilt maken (bijvoorbeeld tekst, afbeeldingen).
- Preprocessing: Maak de data schoon en bereid deze voor door ruis te verwijderen, tekst te normaliseren, afbeeldingen te schalen, enzovoorts.
- Modelselectie: Kies een geschikt neuraal netwerkmodel voor je data.
- Training: Train het model op de dataset, zodat het patronen en relaties leert.
- Vectorgeneratie: Terwijl het model leert, genereert het numerieke vectoren die de data representeren.
- Evaluatie: Beoordeel de kwaliteit van de inbeddingen door hun prestaties op specifieke taken te meten of door menselijke evaluatie.
Typen inbeddingsvectoren
- Woordinbeddingen: Leggen de betekenissen van individuele woorden vast.
- Zinsinbeddingen: Representeren volledige zinnen.
- Documentinbeddingen: Representeren grotere tekstlichamen zoals artikelen of boeken.
- Beeldinbeddingen: Leggen visuele kenmerken van afbeeldingen vast.
- Gebruikersinbeddingen: Geven gebruikersvoorkeuren en gedrag weer.
- Productinbeddingen: Leggen attributen en kenmerken van producten vast.
Inbeddingsvectoren genereren
De Transformers-bibliotheek van Huggingface biedt geavanceerde transformermodellen zoals BERT, RoBERTa en GPT-3. Deze modellen zijn voorgetraind op grote datasets en leveren hoogwaardige inbeddingen die verder kunnen worden verfijnd voor specifieke taken, waardoor ze ideaal zijn voor het creëren van robuuste NLP-toepassingen.
Huggingface Transformers installeren
Zorg er eerst voor dat je de transformers-bibliotheek hebt geïnstalleerd in je Python-omgeving. Je kunt deze installeren met pip:
pip install transformers
Een voorgetraind model laden
Laad vervolgens een voorgetraind model uit de Huggingface model hub. In dit voorbeeld gebruiken we BERT.
from transformers import BertModel, BertTokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
Tekst tokenizen
Tokeniseer je invoertekst om deze voor te bereiden op het model.
inputs = tokenizer("Hello, Huggingface!", return_tensors='pt')
Inbeddingsvectoren genereren
Haal de getokeniseerde tekst door het model om inbeddingen te verkrijgen.
outputs = model(**inputs)
embedding_vectors = outputs.last_hidden_state
4. Voorbeeld: Inbeddingsvectoren genereren met BERT
Hier volgt een volledig voorbeeld waarin de bovenstaande stappen worden gedemonstreerd:
from transformers import BertModel, BertTokenizer
# Laad voorgetraind BERT-model en tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# Tokeniseer invoertekst
text = "Hello, Huggingface!"
inputs = tokenizer(text, return_tensors='pt')
# Genereer inbeddingsvectoren
outputs = model(**inputs)
embedding_vectors = outputs.last_hidden_state
print(embedding_vectors)
Tips en best practices
- Gebruik GPU: Gebruik GPU-versnelling voor grote datasets om het genereren van inbeddingen te versnellen.
- Batchverwerking: Verwerk meerdere zinnen in batches voor meer efficiëntie.
- Modelafstemming: Stem voorgetrainde modellen af op je eigen dataset voor betere prestaties.
Veelvoorkomende valkuilen en probleemoplossing
- Geheugenproblemen: Als je geheugenfouten krijgt, probeer dan de batchgrootte te verkleinen of een efficiënter model te gebruiken.
- Tokenisatieproblemen: Zorg ervoor dat je tekst correct getokenized is om vormfouten te voorkomen.
- Modelcompatibiliteit: Controleer of de tokenizer en het model compatibel zijn met elkaar.
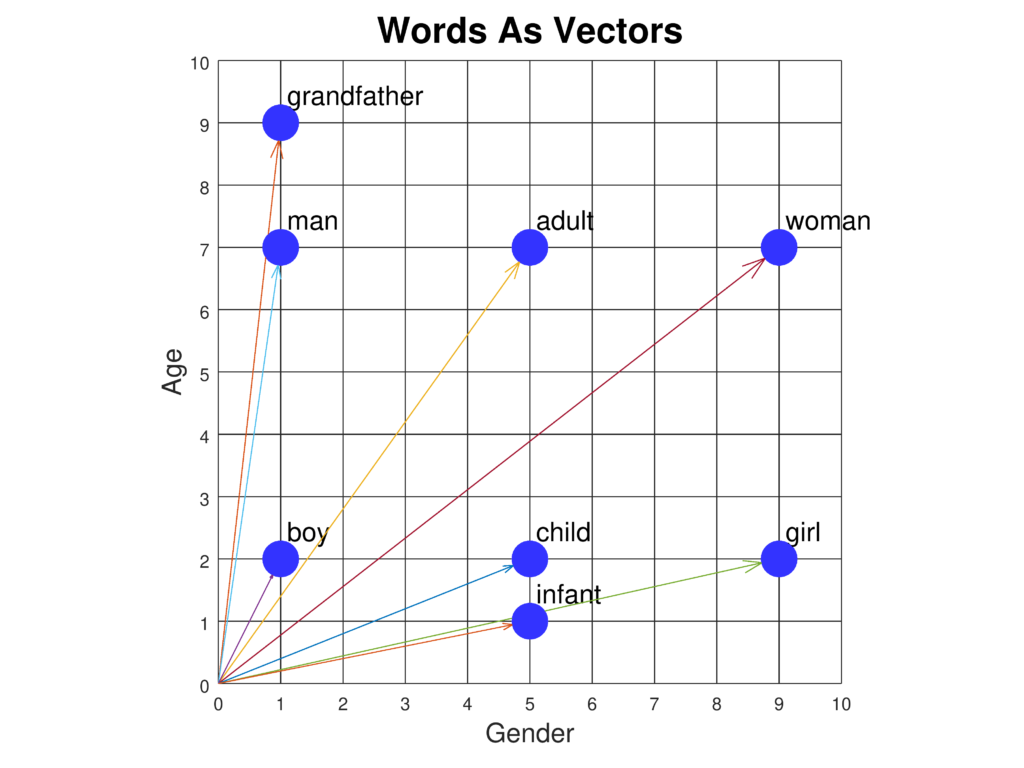
Visualisatie van inbeddingsvectoren
Dimensiereductietechnieken
SNE (Stochastic Neighbor Embedding)
SNE is een vroege methode voor dimensiereductie, ontwikkeld door Geoffrey Hinton en Sam Roweis. De techniek berekent paargewijze gelijkenissen in de hoog-dimensionale ruimte en probeert deze gelijkenissen te behouden in een lager-dimensionale ruimte.
t-SNE (t-distributed Stochastic Neighbor Embedding)
Een verbetering ten opzichte van SNE, t-SNE wordt veel gebruikt voor het visualiseren van hoog-dimensionale data. Het minimaliseert de divergentie tussen twee verdelingen: één die paargewijze gelijkenissen weergeeft in de originele ruimte en één in de gereduceerde ruimte, met behulp van een zwaarstaartige Student-t verdeling.
UMAP (Uniform Manifold Approximation and Projection)
UMAP is een recentere techniek die snellere berekeningen en betere behoud van de globale datastructuur biedt in vergelijking met t-SNE. Het werkt door een hoog-dimensionale graaf te construeren en een laag-dimensionale graaf te optimaliseren zodat deze zoveel mogelijk structurele overeenkomsten vertoont.
Tools en bibliotheken
Verschillende tools en bibliotheken maken de visualisatie van inbeddingsvectoren mogelijk:
- Matplotlib en Seaborn: Veelgebruikt voor het plotten en visualiseren van data in Python.
- t-SNE in Python: Beschikbaar in bibliotheken als Scikit-learn en TensorFlow.
- UMAP: Geïmplementeerd als een zelfstandige bibliotheek in Python.
Veelgestelde vragen
- Wat is een inbeddingsvector?
Een inbeddingsvector is een compacte numerieke representatie van data, waarbij elk datapunt wordt gekoppeld aan een positie in een multidimensionale ruimte om semantische en contextuele relaties vast te leggen.
- Hoe worden inbeddingsvectoren gebruikt in AI?
Inbeddingsvectoren zijn fundamenteel in AI voor het vereenvoudigen van complexe data, waardoor taken als tekstclassificatie, beeldherkenning en gepersonaliseerde aanbevelingen mogelijk worden.
- Hoe kan ik inbeddingsvectoren genereren?
Inbeddingsvectoren kunnen worden gegenereerd met voorgetrainde modellen zoals BERT uit de Huggingface Transformers-bibliotheek. Door je data te tokenizen en door zulke modellen te halen, verkrijg je hoogwaardige inbeddingen voor verdere analyse.
- Welke technieken zijn er om inbeddingsvectoren te visualiseren?
Dimensiereductietechnieken zoals t-SNE en UMAP worden vaak gebruikt om hoog-dimensionale inbeddingsvectoren te visualiseren, waardoor het interpreteren en analyseren van datapatronen makkelijker wordt.
Bouw AI-oplossingen met FlowHunt
Begin met het bouwen van je eigen AI-tools en chatbots met FlowHunt’s no-code platform. Zet je ideeën eenvoudig om in geautomatiseerde Flows.
Meer informatie