Naive Bayes
Naive Bayes is een eenvoudige maar krachtige familie van classificatie-algoritmen die de stelling van Bayes gebruiken, vaak ingezet voor schaalbare taken zoals spamdetectie en tekstclassificatie.
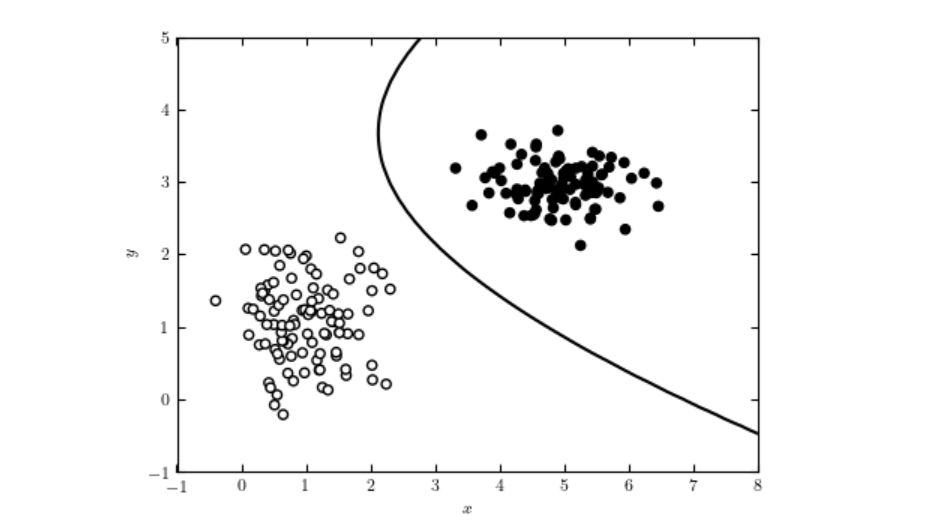
Naive Bayes
Naive Bayes is een familie van eenvoudige, effectieve classificatie-algoritmen gebaseerd op de stelling van Bayes, met de aanname van voorwaardelijke onafhankelijkheid tussen kenmerken. Het wordt veel gebruikt voor spamdetectie, tekstclassificatie en meer vanwege de eenvoud en schaalbaarheid.
Naive Bayes is een familie van classificatie-algoritmen gebaseerd op de stelling van Bayes, die het principe van voorwaardelijke waarschijnlijkheid toepast. De term “naive” verwijst naar de vereenvoudigde aanname dat alle kenmerken in een dataset voorwaardelijk onafhankelijk van elkaar zijn gegeven het klasselabel. Ondanks dat deze aanname vaak wordt geschonden in echte data, staan Naive Bayes-classificaties bekend om hun eenvoud en effectiviteit in diverse toepassingen, zoals tekstclassificatie en spamdetectie.
Belangrijke concepten
Stelling van Bayes
Deze stelling vormt de basis van Naive Bayes en biedt een methode om de waarschijnlijkheidsschatting van een hypothese bij te werken naarmate er meer bewijs of informatie beschikbaar komt. Wiskundig wordt dit uitgedrukt als:![Bayes Theorem Formula]()
waarbij ( P(A|B) ) de posterior waarschijnlijkheid is, ( P(B|A) ) de likelihood, ( P(A) ) de prior waarschijnlijkheid en ( P(B) ) het bewijs.
Voorwaardelijke onafhankelijkheid
De naive aanname dat elk kenmerk onafhankelijk is van elk ander kenmerk gegeven het klasselabel. Deze aanname vereenvoudigt de berekening en maakt het mogelijk dat het algoritme goed schaalt met grote datasets.Posterior waarschijnlijkheid
De waarschijnlijkheid van het klasselabel gegeven de waarde van de kenmerken, berekend met de stelling van Bayes. Dit is het centrale onderdeel bij het maken van voorspellingen met Naive Bayes.Typen Naive Bayes-classifiers
- Gaussian Naive Bayes: Gaat ervan uit dat de continue kenmerken een Gaussische verdeling volgen.
- Multinomial Naive Bayes: Geschikt voor discrete data, vaak gebruikt voor tekstclassificatie waarbij data kan worden weergegeven als woordenaantallen.
- Bernoulli Naive Bayes: Wordt gebruikt voor binaire/booleaanse kenmerken, zoals de aanwezigheid of afwezigheid van een bepaald woord in tekstclassificatie.

Hoe werkt het
Naive Bayes-classificaties werken door de posterior waarschijnlijkheid voor elke klasse te berekenen gegeven een set kenmerken en selecteren de klasse met de hoogste posterior waarschijnlijkheid. Het proces omvat de volgende stappen:
- Trainingsfase: Bereken de prior waarschijnlijkheid van elke klasse en de likelihood van elk kenmerk gegeven elke klasse met behulp van de trainingsdata.
- Voorspellingsfase: Bereken voor een nieuw voorbeeld de posterior waarschijnlijkheid van elke klasse met de prior waarschijnlijkheden en likelihoods uit de trainingsfase. Wijs het klasselabel toe met de hoogste posterior waarschijnlijkheid.
Toepassingen
Naive Bayes-classificaties zijn bijzonder effectief in de volgende toepassingen:
- Spamfiltering: E-mails classificeren als spam of niet-spam op basis van de frequentie van bepaalde woorden.
- Tekstclassificatie: Documenten indelen in vooraf bepaalde categorieën op basis van woordfrequentie of aanwezigheid.
- Sentimentanalyse: Tekst analyseren om het sentiment te bepalen, zoals positief, negatief of neutraal.
- Aanbevelingssystemen: Gebruikmaken van collaboratieve filteringstechnieken om producten of content aan gebruikers aan te bevelen op basis van eerder gedrag.
Voordelen
- Eenvoud en efficiëntie: Naive Bayes is eenvoudig te implementeren en computationeel efficiënt, waardoor het geschikt is voor grote datasets.
- Schaalbaarheid: Het algoritme schaalt goed met het aantal kenmerken en datapunten.
- Omgaan met hoge dimensionaliteit: Presteert goed met een groot aantal kenmerken, zoals bij tekstclassificatie waarbij elk woord een kenmerk is.
Nadelen
- Onafhankelijkheidsaanname: De aanname van onafhankelijkheid tussen kenmerken kan tot onnauwkeurige waarschijnlijkheidsschattingen leiden wanneer kenmerken gecorreleerd zijn.
- Nulfrequentie: Als een kenmerkwaarde niet geobserveerd is in de trainingsset, wijst het model een nulwaarschijnlijkheid toe aan de overeenkomstige klasse. Dit kan worden opgelost met technieken zoals Laplace-smoothing.
Voorbeeldtoepassing
Neem een spamfiltertoepassing met Naive Bayes. De trainingsdata bestaat uit e-mails gelabeld als “spam” of “niet spam”. Elke e-mail wordt weergegeven door een set kenmerken, zoals de aanwezigheid van specifieke woorden. Tijdens de training berekent het algoritme de waarschijnlijkheid van elk woord gegeven het klasselabel. Voor een nieuwe e-mail berekent het algoritme de posterior waarschijnlijkheid voor “spam” en “niet spam” en wijst het label met de hoogste waarschijnlijkheid toe.
Koppeling met AI en chatbots
Naive Bayes-classificaties kunnen worden geïntegreerd in AI-systemen en chatbots om hun natuurlijke taalverwerking te verbeteren en de brug te slaan tussen mens en computer. Ze kunnen bijvoorbeeld worden gebruikt om de intentie van gebruikersvragen te detecteren, teksten in vooraf bepaalde categorieën te classificeren of ongepaste content te filteren. Deze functionaliteit verbetert de kwaliteit en relevantie van AI-gedreven oplossingen. Daarnaast maakt de efficiëntie van het algoritme het geschikt voor realtime toepassingen, wat belangrijk is voor AI-automatisering en chatbotsystemen.
Onderzoek
Naive Bayes is een familie van eenvoudige maar krachtige probabilistische algoritmen gebaseerd op het toepassen van de stelling van Bayes, met sterke onafhankelijkheidsaannames tussen de kenmerken. Het wordt veel gebruikt voor classificatietaken vanwege zijn eenvoud en effectiviteit. Hier zijn enkele wetenschappelijke artikelen die diverse toepassingen en verbeteringen van de Naive Bayes-classifier bespreken:
Verbetering van spamfiltering door Naive Bayes te combineren met eenvoudige k-nearest neighbor zoekopdrachten
Auteur: Daniel Etzold
Gepubliceerd: 30 november 2003
Dit artikel onderzoekt het gebruik van Naive Bayes voor e-mailclassificatie, waarbij de eenvoud van implementatie en efficiëntie worden benadrukt. De studie toont empirische resultaten die laten zien hoe het combineren van Naive Bayes met k-nearest neighbor zoekopdrachten de nauwkeurigheid van spamfilters kan verhogen. De combinatie leverde lichte verbeteringen op bij een groot aantal kenmerken en significante verbeteringen bij minder kenmerken. Lees het artikel.Locally Weighted Naive Bayes
Auteurs: Eibe Frank, Mark Hall, Bernhard Pfahringer
Gepubliceerd: 19 oktober 2012
Dit artikel behandelt de belangrijkste zwakte van Naive Bayes, namelijk de aanname van onafhankelijkheid tussen attributen. Er wordt een lokaal gewogen versie van Naive Bayes geïntroduceerd die lokale modellen leert op het moment van voorspellen, waardoor de onafhankelijkheidsaanname wordt versoepeld. De experimentele resultaten tonen aan dat deze aanpak zelden de nauwkeurigheid vermindert en deze vaak aanzienlijk verbetert. De methode wordt geprezen om haar conceptuele eenvoud en computationele efficiëntie ten opzichte van andere technieken. Lees het artikel.Naive Bayes Entrapment Detection for Planetary Rovers
Auteur: Dicong Qiu
Gepubliceerd: 31 januari 2018
In deze studie wordt de toepassing van Naive Bayes-classificaties voor het detecteren van vastlopen bij planetaire rovers besproken. De criteria voor het vastlopen van een rover worden gedefinieerd en het gebruik van Naive Bayes bij het detecteren van dergelijke scenario’s wordt aangetoond. Het artikel beschrijft experimenten met AutoKrawler rovers en geeft inzicht in de effectiviteit van Naive Bayes voor autonome reddingsprocedures. Lees het artikel.
Veelgestelde vragen
- Wat is Naive Bayes?
Naive Bayes is een familie van classificatie-algoritmen gebaseerd op de stelling van Bayes, waarbij wordt aangenomen dat alle kenmerken voorwaardelijk onafhankelijk zijn gegeven het klasselabel. Het wordt veel gebruikt voor tekstclassificatie, spamfiltering en sentimentanalyse.
- Wat zijn de belangrijkste typen Naive Bayes-classificaties?
De belangrijkste typen zijn Gaussian Naive Bayes (voor continue kenmerken), Multinomial Naive Bayes (voor discrete kenmerken zoals woordenaantallen) en Bernoulli Naive Bayes (voor binaire/booleaanse kenmerken).
- Wat zijn de voordelen van Naive Bayes?
Naive Bayes is eenvoudig te implementeren, computationeel efficiënt, schaalbaar naar grote datasets en kan goed omgaan met data met veel dimensies.
- Wat zijn de beperkingen van Naive Bayes?
De belangrijkste beperking is de aanname van onafhankelijkheid tussen kenmerken, wat vaak niet klopt voor echte data. Het kan ook nulwaarschijnlijkheid toekennen aan niet-geziene kenmerken, wat kan worden verminderd met technieken zoals Laplace-smoothing.
- Waar wordt Naive Bayes gebruikt in AI en chatbots?
Naive Bayes wordt in AI-systemen en chatbots gebruikt voor intentiedetectie, tekstclassificatie, spamfiltering en sentimentanalyse, waarmee natuurlijke taalverwerkingsmogelijkheden worden versterkt en realtime beslissingen mogelijk worden gemaakt.
Klaar om je eigen AI te bouwen?
Slimme chatbots en AI-tools onder één dak. Verbind intuïtieve blokken om je ideeën om te zetten in geautomatiseerde Flows.