NLTK
NLTK is een krachtig open-source Python-pakket voor tekstanalyse en natuurlijke taalverwerking, met uitgebreide functies voor academische en industriële toepassingen.
NLTK
NLTK is een uitgebreide Python-toolkit voor symbolische en statistische NLP, met functies zoals tokenisatie, stemming, lemmatizatie, POS-tagging en meer. Het wordt veel gebruikt in de academische wereld en het bedrijfsleven voor tekstanalyse en taalverwerkingstaken.
Natural Language Toolkit (NLTK) is een uitgebreide suite van bibliotheken en programma’s ontworpen voor symbolische en statistische natuurlijke taalverwerking die de interactie tussen mens en computer overbrugt. Ontdek vandaag nog de belangrijkste kenmerken, werking en toepassingen!") (NLP) voor de programmeertaal Python. NLTK is oorspronkelijk ontwikkeld door Steven Bird en Edward Loper en is een gratis open-source project dat breed wordt ingezet in zowel academische als industriële omgevingen voor tekstanalyse en taalverwerking. Het staat vooral bekend om het gebruiksgemak en de uitgebreide verzameling bronnen, waaronder meer dan 50 corpora en lexicale bronnen. NLTK ondersteunt diverse NLP-taken, zoals tokenisatie, stemming, tagging, parsing en semantisch redeneren, waardoor het een veelzijdig hulpmiddel is voor taalkundigen, ingenieurs, docenten en onderzoekers.
Belangrijkste functies en mogelijkheden
Tokenisatie
Tokenisatie is het proces waarbij tekst wordt opgedeeld in kleinere eenheden, zoals woorden of zinnen. In NLTK kan tokenisatie worden uitgevoerd met functies als word_tokenize en sent_tokenize, die essentieel zijn voor het voorbereiden van tekstdata voor verdere analyse. De toolkit biedt gebruiksvriendelijke interfaces voor deze taken, waardoor gebruikers efficiënt tekstdata kunnen voorbewerken.
Voorbeeld:
from nltk.tokenize import word_tokenize, sent_tokenize
text = "NLTK is a great tool. It is widely used in NLP."
word_tokens = word_tokenize(text)
sentence_tokens = sent_tokenize(text)
Verwijderen van stopwoorden
Stopwoorden zijn veelvoorkomende woorden die vaak uit tekstdata worden verwijderd om ruis te verminderen en de focus op betekenisvolle inhoud te leggen. NLTK biedt een lijst met stopwoorden voor verschillende talen, wat helpt bij taken als frequentieanalyse en sentimentanalyse. Deze functionaliteit is cruciaal om de nauwkeurigheid van tekstanalyse te verbeteren door irrelevante woorden te filteren.
Voorbeeld:
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtered_words = [word for word in word_tokens if word.lower() not in stop_words]
Stemming
Stemming houdt in dat woorden worden teruggebracht tot hun stamvorm, vaak door voor- of achtervoegsels te verwijderen. NLTK biedt verschillende stemming-algoritmen, zoals de Porter Stemmer, die veel wordt gebruikt om woorden te vereenvoudigen voor analyse. Stemming is vooral nuttig bij toepassingen waar de exacte woordvorm minder belangrijk is dan de stam.
Voorbeeld:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stems = [stemmer.stem(word) for word in word_tokens]
Lemmatizatie
Lemmatizatie lijkt op stemming maar levert woorden op die taalkundig correct zijn, vaak met behulp van een woordenboek om de stamvorm van een woord te bepalen. NLTK’s WordNetLemmatizer is een populair hulpmiddel hiervoor en maakt een nauwkeurige normalisatie van tekst mogelijk.
Voorbeeld:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmas = [lemmatizer.lemmatize(word) for word in word_tokens]
Part-of-Speech (POS) Tagging
POS-tagging kent elk woord in een tekst een woordsoort toe, zoals zelfstandig naamwoord, werkwoord, bijvoeglijk naamwoord, enzovoort, wat cruciaal is voor het begrijpen van de syntactische structuur van zinnen. NLTK’s pos_tag-functie faciliteert dit proces, waardoor diepgaandere taalkundige analyse mogelijk wordt.
Voorbeeld:
import nltk
pos_tags = nltk.pos_tag(word_tokens)
Named Entity Recognition (NER)
Named Entity Recognition identificeert en categoriseert belangrijke entiteiten in tekst, zoals namen van personen, organisaties en locaties. NLTK biedt functies om NER uit te voeren: een belangrijk AI-hulpmiddel in NLP voor het identificeren en classificeren van entiteiten in tekst, wat de data-analyse versterkt."), waardoor geavanceerdere tekstanalyse mogelijk is en waardevolle inzichten uit documenten kunnen worden gehaald.
Voorbeeld:
from nltk import ne_chunk
entities = ne_chunk(pos_tags)
Frequentieverdeling
Frequentieverdeling wordt gebruikt om de meest voorkomende woorden of zinnen in een tekst te bepalen. Met NLTK’s FreqDist-functie kun je woordfrequenties visualiseren en analyseren, wat fundamenteel is voor taken zoals het extraheren van kernwoorden en topic modeling.
Voorbeeld:
from nltk import FreqDist
freq_dist = FreqDist(word_tokens)
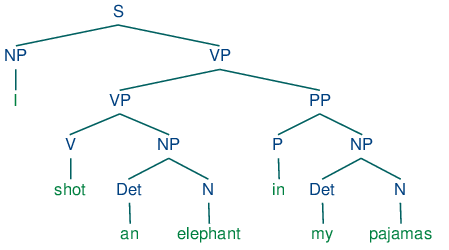
Parsing en genereren van syntaxisbomen
Parsing houdt in dat de grammaticale structuur van zinnen wordt geanalyseerd. NLTK kan syntaxisbomen genereren die de syntactische structuur weergeven en helpen bij diepgaandere taalkundige analyse. Dit is essentieel voor toepassingen zoals automatische vertaling en syntactische parsing.
Voorbeeld:
from nltk import CFG
from nltk.parse.generate import generate
grammar = CFG.fromstring("""
S -> NP VP
NP -> 'NLTK'
VP -> 'is' 'a' 'tool'
""")
parser = nltk.ChartParser(grammar)
Tekstcorpora
NLTK bevat toegang tot diverse tekstcorpora, die essentieel zijn voor het trainen en evalueren van NLP-modellen. Deze bronnen zijn eenvoudig toegankelijk en inzetbaar voor verschillende verwerkingstaken, en bieden een rijke dataset voor taalkundig onderzoek en applicatieontwikkeling.
Voorbeeld:
from nltk.corpus import gutenberg
sample_text = gutenberg.raw('austen-emma.txt')
Toepassingen en gebruikssituaties
Academisch onderzoek
NLTK wordt veel gebruikt in academisch onderzoek voor het onderwijzen en experimenteren met concepten uit de natuurlijke taalverwerking. Door de uitgebreide documentatie en bronnen is het een voorkeurskeuze voor docenten en studenten. Dankzij de community-gedreven ontwikkeling blijft NLTK up-to-date met de nieuwste ontwikkelingen in NLP.
Tekstverwerking en analyse
Voor taken zoals sentimentanalyse, topic modeling en informatie-extractie biedt NLTK een scala aan tools die kunnen worden geïntegreerd in grotere systemen voor tekstverwerking. Deze mogelijkheden maken het tot een waardevol hulpmiddel voor bedrijven die inzichten uit tekstdata willen halen.
Integratie met machine learning
NLTK kan worden gecombineerd met machine learning-bibliotheken zoals scikit-learn en TensorFlow om intelligentere systemen te bouwen die menselijke taal begrijpen en verwerken. Deze integratie maakt de ontwikkeling mogelijk van geavanceerde NLP-toepassingen, zoals chatbots en AI-gedreven systemen.
Computationele taalkunde
Onderzoekers in de computationele taalkunde gebruiken NLTK om taalkundige fenomenen te bestuderen en te modelleren, waarbij ze de uitgebreide toolkit inzetten om taaldata te analyseren en te interpreteren. Dankzij de ondersteuning van meerdere talen is NLTK een veelzijdig hulpmiddel voor cross-linguïstische studies.
Installatie en setup
NLTK kan worden geïnstalleerd via pip en extra datasets kunnen worden gedownload met de functie nltk.download(). Het ondersteunt meerdere platformen, waaronder Windows, macOS en Linux, en vereist Python 3.7 of hoger. Installatie van NLTK in een virtuele omgeving wordt aanbevolen voor efficiënt beheer van afhankelijkheden.
Installatie-opdracht:
pip install nltk
Onderzoek
NLTK: The Natural Language Toolkit (Gepubliceerd: 2002-05-17)
Dit fundamentele artikel van Edward Loper en Steven Bird introduceert NLTK als een uitgebreide suite van open-source modules, tutorials en probleemsets gericht op computationele taalkunde. NLTK bestrijkt een breed spectrum aan taken in natuurlijke taalverwerking, zowel symbolisch als statistisch, en biedt een interface naar geannoteerde corpora. De toolkit is ontworpen om leren te bevorderen door praktische ervaring, zodat gebruikers met geavanceerde modellen kunnen werken en gestructureerd leren programmeren. Lees meerText Normalization for Low-Resource Languages of Africa (Gepubliceerd: 2021-03-29)
Deze studie onderzoekt de toepassing van NLTK bij tekstnormalisatie en het trainen van taalmodellen voor Afrikaanse talen met weinig middelen. Het artikel belicht de uitdagingen bij machine learning wanneer gewerkt wordt met data van twijfelachtige kwaliteit en beperkte beschikbaarheid. Met behulp van NLTK ontwikkelden de auteurs een tekstnormalizer met het Pynini-framework, waarmee de effectiviteit bij het verwerken van meerdere Afrikaanse talen werd aangetoond. Dit onderstreept de veelzijdigheid van NLTK in diverse taalkundige omgevingen. Lees meerNatural Language Processing, Sentiment Analysis and Clinical Analytics (Gepubliceerd: 2019-02-02)
Dit artikel onderzoekt de kruising van NLP, sentimentanalyse en klinische analytics, en benadrukt het nut van NLTK. Het bespreekt hoe ontwikkelingen in big data het mogelijk hebben gemaakt voor zorgprofessionals om sentiment en emotie uit social mediadata te halen. NLTK wordt genoemd als een essentieel hulpmiddel bij de implementatie van verschillende NLP-theorieën, wat de extractie en analyse van waardevolle inzichten uit tekstdata faciliteert en zo klinische besluitvorming verbetert. Lees meer
Veelgestelde vragen
- Wat is NLTK?
NLTK (Natural Language Toolkit) is een uitgebreide suite van Python-bibliotheken en programma's voor symbolische en statistische natuurlijke taalverwerking (NLP). Het biedt tools voor tokenisatie, stemming, lemmatizatie, POS-tagging, parsing en meer, waardoor het veel wordt gebruikt in zowel academische als industriële omgevingen.
- Wat kun je doen met NLTK?
Met NLTK kun je een breed scala aan NLP-taken uitvoeren, waaronder tokenisatie, verwijderen van stopwoorden, stemming, lemmatizatie, part-of-speech tagging, named entity recognition, frequentieverdelingsanalyse, parsing en werken met tekstcorpora.
- Wie gebruikt NLTK?
NLTK wordt gebruikt door onderzoekers, ingenieurs, docenten en studenten in de academische wereld en het bedrijfsleven voor het bouwen van NLP-toepassingen, experimenteren met taalverwerkingsconcepten en het onderwijzen van computationele taalkunde.
- Hoe installeer je NLTK?
Je kunt NLTK installeren met pip via het commando 'pip install nltk'. Extra datasets en bronnen kunnen binnen Python worden gedownload met 'nltk.download()'.
- Kan NLTK worden geïntegreerd met machine learning-bibliotheken?
Ja, NLTK kan worden geïntegreerd met machine learning-bibliotheken zoals scikit-learn en TensorFlow om geavanceerde NLP-toepassingen te bouwen zoals chatbots en intelligente data-analysesystemen.
Probeer NLTK met FlowHunt
Ontdek hoe NLTK je NLP-projecten kan verbeteren. Bouw slimme chatbots en AI-tools met het intuïtieve platform van FlowHunt.