Vraagbeantwoording
Vraagbeantwoording met RAG verbetert LLM’s door realtime data-ophaling en natuurlijke taal generatie te integreren voor nauwkeurige, contextueel relevante antwoorden.
Vraagbeantwoording
Vraagbeantwoording met Retrieval-Augmented Generation (RAG) versterkt taalmodellen door realtime externe gegevens te integreren voor nauwkeurige en relevante antwoorden. Het optimaliseert prestaties in dynamische sectoren, biedt verbeterde nauwkeurigheid, dynamische inhoud en verhoogde relevantie.
Vraagbeantwoording met Retrieval-Augmented Generation (RAG) is een innovatieve methode die de sterke punten van informatieophaling en natuurlijke taal generatie combineert om mensachtige tekst uit gegevens te creëren, waarmee AI, chatbots, rapporten worden verbeterd en ervaringen gepersonaliseerd. Deze hybride aanpak versterkt de mogelijkheden van grote taalmodellen (LLM’s) door hun antwoorden aan te vullen met relevante, actuele informatie opgehaald uit externe databronnen. In tegenstelling tot traditionele methoden die uitsluitend op voorgetrainde modellen vertrouwen, integreert RAG dynamisch externe gegevens, waardoor systemen accuratere en contextueel relevantere antwoorden kunnen geven, vooral in domeinen die de nieuwste informatie of gespecialiseerde kennis vereisen.
RAG optimaliseert de prestaties van LLM’s door ervoor te zorgen dat antwoorden niet alleen uit een interne dataset worden gegenereerd, maar ook gebaseerd zijn op realtime, gezaghebbende bronnen. Deze aanpak is essentieel voor vraagbeantwoordingstaken in dynamische sectoren waar informatie voortdurend evolueert.
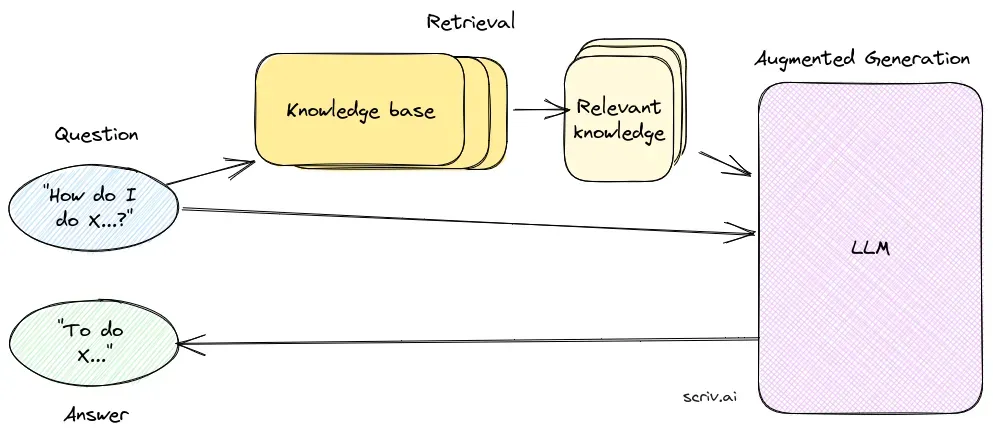
Kerncomponenten van RAG
1. Retrievalcomponent
De retrievalcomponent is verantwoordelijk voor het ophalen van relevante informatie uit grote datasets, meestal opgeslagen in een vector database. Deze component gebruikt semantische zoektechnieken om tekstsegmenten of documenten te identificeren en te extraheren die sterk aansluiten bij de vraag van de gebruiker.
- Vector database: Een gespecialiseerde database die vectorrepresentaties van documenten opslaat. Deze embeddings maken efficiënte zoekopdrachten en ophaling mogelijk door de semantische betekenis van de gebruikersvraag te matchen met relevante tekstsegmenten.
- Semantisch zoeken: Maakt gebruik van vectorembeddings om documenten te vinden op basis van semantische overeenkomsten in plaats van eenvoudige zoekwoorden, wat de relevantie en nauwkeurigheid van de opgehaalde informatie verbetert.
2. Generatiecomponent
De generatiecomponent, meestal een LLM zoals GPT-3 of BERT, synthetiseert een antwoord door de oorspronkelijke vraag van de gebruiker te combineren met de opgehaalde context. Deze component is essentieel voor het genereren van samenhangende en contextueel passende antwoorden.
- Taalmodellen (LLM’s): Getraind om tekst te genereren op basis van inputprompts, gebruiken LLM’s in RAG-systemen opgehaalde documenten als context om de kwaliteit en relevantie van gegenereerde antwoorden te verbeteren.
Workflow van een RAG-systeem
- Documentvoorbereiding: Het systeem begint met het laden van een grote collectie documenten en zet deze om in een formaat dat geschikt is voor analyse. Dit houdt vaak in dat documenten worden opgesplitst in kleinere, beheersbare stukken.
- Vector embedding: Elk documentdeel wordt omgezet in een vectorrepresentatie met behulp van embeddings gegenereerd door taalmodellen. Deze vectoren worden opgeslagen in een vector database voor efficiënte ophaling.
- Vraagverwerking: Bij ontvangst van een gebruikersvraag zet het systeem de vraag om in een vector en voert een vergelijkbaarheidszoektocht uit in de vector database om relevante documentdelen te identificeren.
- Contextuele antwoordgeneratie: De opgehaalde documentdelen worden gecombineerd met de gebruikersvraag en aangeboden aan de LLM, die een definitief, contextueel verrijkt antwoord genereert.
- Uitvoer: Het systeem levert een antwoord dat zowel nauwkeurig als relevant is voor de vraag, verrijkt met contextueel passende informatie.
Voordelen van RAG
- Verbeterde nauwkeurigheid: Door relevante context op te halen, minimaliseert RAG het risico op het genereren van onjuiste of verouderde antwoorden, een veelvoorkomend probleem bij op zichzelf staande LLM’s.
- Dynamische inhoud: RAG-systemen kunnen de nieuwste informatie uit bijgewerkte kennisbanken integreren, wat ze ideaal maakt voor domeinen die actuele gegevens vereisen.
- Verhoogde relevantie: Het retrievalproces zorgt ervoor dat gegenereerde antwoorden zijn afgestemd op de specifieke context van de vraag, wat de kwaliteit en relevantie van het antwoord verbetert.
Toepassingen
- Chatbots en virtuele assistenten: RAG-aangedreven systemen verbeteren chatbots en virtuele assistenten door nauwkeurige en contextbewuste antwoorden te geven, waardoor gebruikersinteractie en tevredenheid toenemen.
- Klantenondersteuning: In toepassingen voor klantenondersteuning kunnen RAG-systemen relevante beleidsdocumenten of productinformatie ophalen om precieze antwoorden te geven op gebruikersvragen.
- Contentcreatie: RAG-modellen kunnen documenten en rapporten genereren door opgehaalde informatie te integreren, waardoor ze nuttig zijn voor geautomatiseerde contentgeneratie.
- Educatieve tools: In het onderwijs kunnen RAG-systemen leerassistenten aandrijven die uitleggen en samenvatten op basis van de nieuwste educatieve inhoud.
Technische Implementatie
Het implementeren van een RAG-systeem omvat verschillende technische stappen:
- Vectoropslag en -ophaling: Gebruik vector databases zoals Pinecone of FAISS om documentembeddings efficiënt op te slaan en op te halen.
- Integratie van taalmodellen: Integreer LLM’s zoals GPT-3 of aangepaste modellen met frameworks als HuggingFace Transformers om het generatieaspect te beheren.
- Pipelineconfiguratie: Stel een pipeline in die het proces van documentophaling tot antwoordgeneratie beheert en zorgt voor een soepele integratie van alle componenten.
Uitdagingen en aandachtspunten
- Kosten- en middelenbeheer: RAG-systemen kunnen veel middelen vereisen en moeten geoptimaliseerd worden om de computationele kosten effectief te beheersen.
- Feitelijke nauwkeurigheid: Het is cruciaal dat opgehaalde informatie accuraat en actueel is om het genereren van misleidende antwoorden te voorkomen.
- Complexiteit van de setup: De initiële opzet van RAG-systemen kan complex zijn, met meerdere componenten die zorgvuldig geïntegreerd en geoptimaliseerd moeten worden.
Onderzoek naar Vraagbeantwoording met Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is een methode die vraagbeantwoording verbetert door retrievalmechanismen te combineren met generatieve modellen. Recent onderzoek heeft de effectiviteit en optimalisatie van RAG in verschillende contexten onderzocht.
- In Defense of RAG in the Era of Long-Context Language Models: Dit artikel pleit voor de blijvende relevantie van RAG ondanks de opkomst van long-context taalmodellen, die langere tekstsequenties integreren in hun verwerking. De auteurs stellen een Order-Preserve Retrieval-Augmented Generation (OP-RAG) mechanisme voor dat de prestaties van RAG optimaliseert bij het behandelen van vraagbeantwoording met lange context. Zij tonen aan dat OP-RAG met minder tokens een hoge antwoordkwaliteit kan bereiken vergeleken met long-context modellen. Lees meer.
- CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems: Deze studie introduceert ClapNQ, een benchmark dataset ontworpen voor het evalueren van RAG-systemen bij het genereren van samenhangende lange antwoorden. De dataset richt zich op antwoorden die zijn onderbouwd door specifieke passages, zonder hallucinaties, en moedigt RAG-modellen aan zich aan te passen aan beknopte en samenhangende antwoordformaten. De auteurs bieden baseline-experimenten die verbeterpunten in RAG-systemen aantonen. Lees meer.
- Optimizing Retrieval-Augmented Generation with Elasticsearch for Enhanced Question-Answering Systems: Dit onderzoek integreert Elasticsearch in het RAG-framework om de efficiëntie en nauwkeurigheid van vraagbeantwoording te vergroten. Met gebruik van de Stanford Question Answering Dataset (SQuAD) versie 2.0 vergelijkt de studie verschillende retrievalmethoden en benadrukt de voordelen van het ES-RAG-schema op het gebied van retrievalefficiëntie en nauwkeurigheid, waarmee het andere methoden met 0,51 procentpunt overtreft. Het artikel suggereert verdere verkenning van de interactie tussen Elasticsearch en taalmodellen om systeemantwoorden verder te verbeteren. Lees meer.
Veelgestelde vragen
- Wat is Retrieval-Augmented Generation (RAG) in Vraagbeantwoording?
RAG is een methode die informatieophaling en natuurlijke taal generatie combineert om nauwkeurige, actuele antwoorden te leveren door externe databronnen te integreren in grote taalmodellen.
- Wat zijn de belangrijkste componenten van een RAG-systeem?
Een RAG-systeem bestaat uit een retrievalcomponent, die relevante informatie ophaalt uit vector databases via semantisch zoeken, en een generatiecomponent, meestal een LLM, die antwoorden synthetiseert met zowel de gebruikersvraag als de opgehaalde context.
- Wat zijn de voordelen van RAG voor vraagbeantwoording?
RAG verhoogt de nauwkeurigheid door contextueel relevante informatie op te halen, ondersteunt dynamische inhoudsupdates uit externe kennisbanken en verbetert de relevantie en kwaliteit van de gegenereerde antwoorden.
- Wat zijn veelvoorkomende toepassingen van RAG-gebaseerde vraagbeantwoording?
Veelvoorkomende toepassingen zijn AI-chatbots, klantenondersteuning, geautomatiseerde contentcreatie en educatieve tools die nauwkeurige, contextbewuste en actuele antwoorden vereisen.
- Met welke uitdagingen moet rekening worden gehouden bij het implementeren van RAG?
RAG-systemen kunnen veel middelen vereisen, behoeven zorgvuldige integratie voor optimale prestaties en moeten zorgen voor feitelijke juistheid van opgehaalde informatie om misleidende of verouderde antwoorden te voorkomen.
Begin met het bouwen van AI-aangedreven Vraagbeantwoording
Ontdek hoe Retrieval-Augmented Generation jouw chatbot- en supportoplossingen kan versterken met realtime, nauwkeurige antwoorden.
Meer informatie

