Ophaal-pijplijn
Een ophaal-pijplijn stelt chatbots in staat om relevante externe kennis op te halen en te verwerken voor nauwkeurige, real-time en contextbewuste antwoorden, met gebruik van RAG, embeddings en vectordatabases.
Wat is een ophaal-pijplijn voor chatbots?
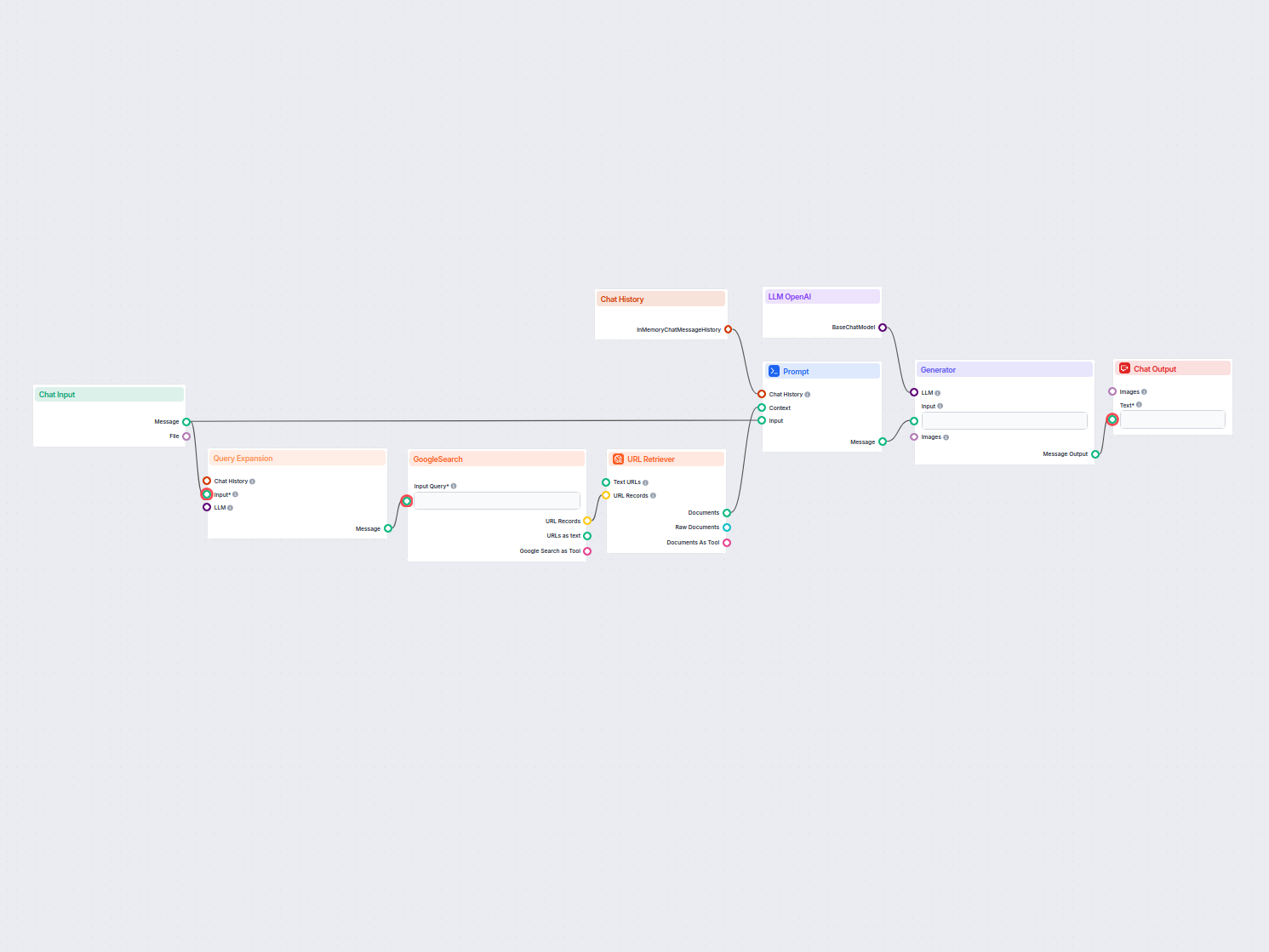
Een ophaal-pijplijn voor chatbots verwijst naar de technische architectuur en het proces waarmee chatbots relevante informatie kunnen ophalen, verwerken en terugvinden als reactie op gebruikersvragen. In tegenstelling tot eenvoudige vraag-en-antwoord-systemen die alleen vertrouwen op voorgetrainde taalmodellen, maken ophaal-pijplijnen gebruik van externe kennisbanken of databronnen. Hierdoor kan de chatbot nauwkeurige, contextueel relevante en actuele antwoorden geven, zelfs wanneer de data niet inherent aanwezig is in het taalmodel zelf.
De ophaal-pijplijn bestaat doorgaans uit meerdere componenten, waaronder data-inname, embeddingcreatie, vectoropslag, contextophaling en antwoordgeneratie. De implementatie maakt vaak gebruik van Retrieval-Augmented Generation (RAG), dat de sterke punten van dataophalingssystemen en Large Language Models (LLMs) combineert voor het genereren van antwoorden.
Hoe wordt een ophaal-pijplijn gebruikt in chatbots?
Een ophaal-pijplijn wordt ingezet om de mogelijkheden van een chatbot te vergroten door deze in staat te stellen om:
- Toegang tot domeinspecifieke kennis
De chatbot kan externe databases, documenten of API’s raadplegen om precieze informatie op te halen die relevant is voor de gebruikersvraag. - Contextbewuste antwoorden genereren
Door opgehaalde data te combineren met natuurlijke taal generatie produceert de chatbot samenhangende, op maat gemaakte antwoorden. - Actuele informatie garanderen
In tegenstelling tot statische taalmodellen maakt de pijplijn real-time ophaling van informatie uit dynamische bronnen mogelijk.
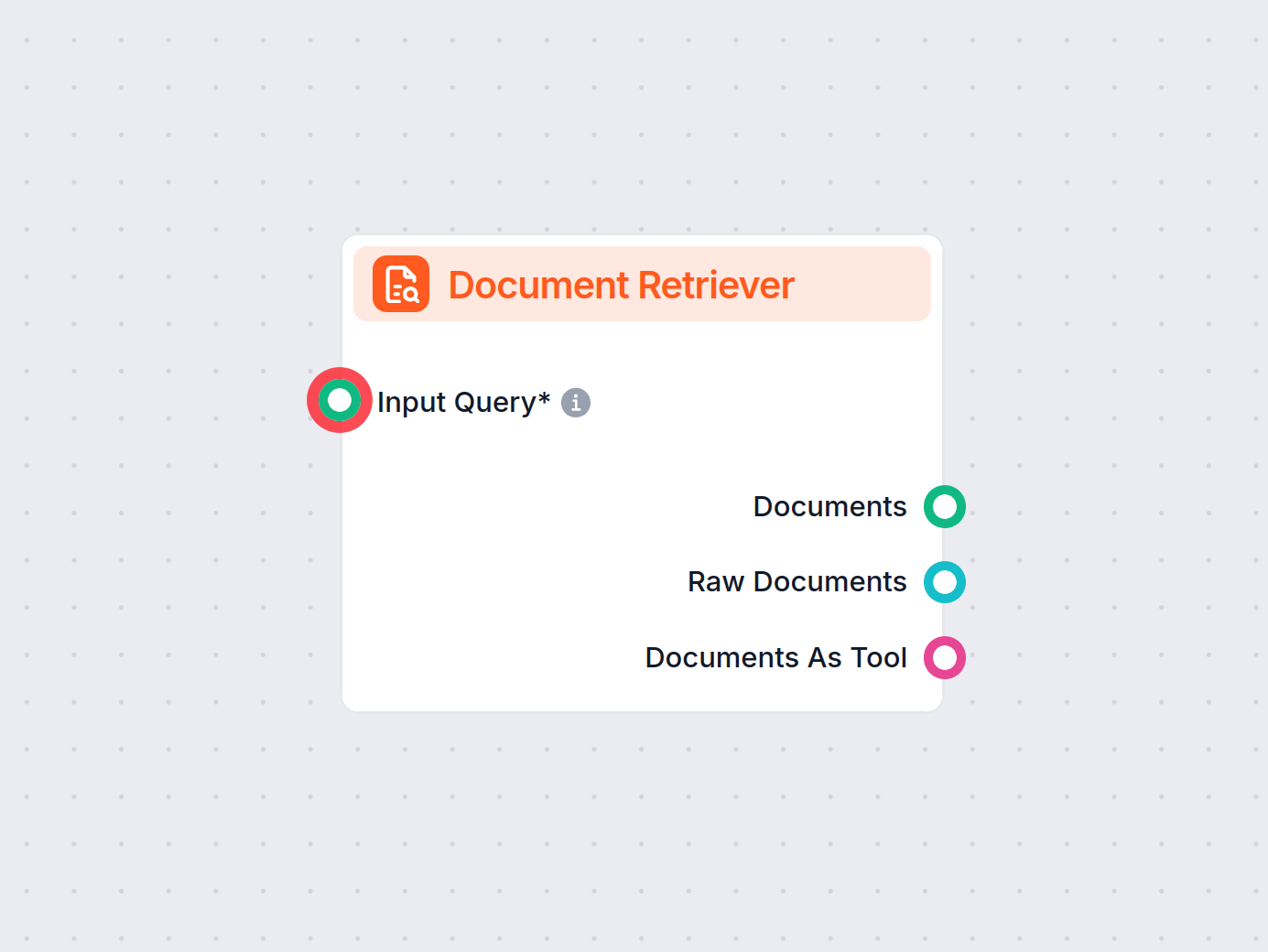
Belangrijkste componenten van een ophaal-pijplijn
Documentinname
Het verzamelen en voorbewerken van ruwe data, zoals PDF’s, tekstbestanden, databases of API’s. Tools zoals LangChain of LlamaIndex worden vaak gebruikt voor naadloze data-inname.
Voorbeeld: Klantenservice-FAQ’s of productspecificaties laden in het systeem.Documentvoorbewerking
Lange documenten worden opgesplitst in kleinere, semantisch betekenisvolle stukken. Dit is essentieel om de tekst passend te maken voor embeddingmodellen die doorgaans tokenlimieten hebben (bijvoorbeeld 512 tokens).Voorbeeld codefragment:
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) chunks = text_splitter.split_documents(document_list)Embeddinggeneratie
Tekstdata wordt omgezet in hoog-dimensionale vectorrepresentaties met behulp van embeddingmodellen. Deze embeddings coderen numeriek de semantische betekenis van de data. Voorbeeld embeddingmodel: OpenAI’stext-embedding-ada-002of Hugging Face’se5-large-v2.Vectoropslag
Embeddings worden opgeslagen in vectordatabases die geoptimaliseerd zijn voor gelijkenis-zoekopdrachten. Tools zoals Milvus, Chroma of PGVector worden veel gebruikt. Voorbeeld: Productomschrijvingen en hun embeddings opslaan voor efficiënte ophaling.Queryverwerking
Wanneer een gebruikersvraag wordt ontvangen, wordt deze omgezet in een queryvector met hetzelfde embeddingmodel. Dit maakt semantische gelijkenis-matching met de opgeslagen embeddings mogelijk.Voorbeeld codefragment:
query_vector = embedding_model.encode("Wat zijn de specificaties van Product X?") retrieved_docs = vector_db.similarity_search(query_vector, k=5)Dataophaling
Het systeem haalt de meest relevante datastukken op op basis van gelijkenisscores (bijv. cosinusgelijkenis). Multi-modale ophalingssystemen kunnen SQL-databases, kennisgrafen en vectorzoekopdrachten combineren voor robuustere resultaten.Antwoordgeneratie
De opgehaalde data wordt gecombineerd met de gebruikersvraag en aangeboden aan een groot taalmodel (LLM) om een definitief, natuurlijk taalantwoord te genereren. Deze stap wordt vaak aangeduid als augmented generation.Voorbeeld prompttemplate:
prompt_template = """ Context: {context} Question: {question} Please provide a detailed response using the context above. """Naverwerking en validatie
Geavanceerde ophaal-pijplijnen bevatten detectie van hallucinaties, relevantiecontroles of antwoordbeoordeling om te waarborgen dat de output feitelijk en relevant is.
Toepassingen van ophaal-pijplijnen in chatbots
Klantenservice
Chatbots kunnen producthandleidingen, probleemoplossingsgidsen of FAQ’s ophalen om direct antwoord te geven op klantvragen.
Voorbeeld: Een chatbot helpt een klant met het resetten van een router door het relevante deel van de gebruikershandleiding op te halen.Kennismanagement binnen ondernemingen
Interne enterprise-chatbots kunnen toegang geven tot bedrijfsspecifieke data zoals HR-beleid, IT-supportdocumentatie of compliance-richtlijnen.
Voorbeeld: Medewerkers die het interne chatbot vragen naar het ziekteverzuimbeleid.E-commerce
Chatbots helpen gebruikers door productdetails, reviews of voorraadbeschikbaarheid op te halen.
Voorbeeld: “Wat zijn de belangrijkste functies van Product Y?”Zorg
Chatbots halen medische literatuur, richtlijnen of patiëntgegevens op om zorgprofessionals of patiënten te ondersteunen.
Voorbeeld: Een chatbot die waarschuwingen voor geneesmiddelinteracties ophaalt uit een farmaceutische database.Onderwijs en onderzoek
Academische chatbots gebruiken RAG-pijplijnen om wetenschappelijke artikelen op te halen, vragen te beantwoorden of onderzoeksbevindingen samen te vatten.
Voorbeeld: “Kun je de bevindingen samenvatten van deze studie uit 2023 over klimaatverandering?”Juridisch en compliance
Chatbots halen juridische documenten, jurisprudentie of compliance-eisen op om juridische professionals te ondersteunen.
Voorbeeld: “Wat is de laatste update over GDPR-regelgeving?”
Voorbeelden van implementaties van ophaal-pijplijnen
Voorbeeld 1: PDF-gebaseerde Q&A
Een chatbot die vragen beantwoordt uit het jaarlijkse financiële verslag van een bedrijf in PDF-formaat.
Voorbeeld 2: Hybride ophaling
Een chatbot die SQL, vectorzoekopdrachten en kennisgrafen combineert om een vraag van een medewerker te beantwoorden.
Voordelen van het gebruik van een ophaal-pijplijn
- Nauwkeurigheid
Vermindert hallucinaties door antwoorden te baseren op feitelijke, opgehaalde data. - Contextuele relevantie
Maakt antwoorden op maat op basis van domeinspecifieke data. - Real-time updates
Houdt de kennisbasis van de chatbot actueel met dynamische databronnen. - Kostenefficiëntie
Vermindert de noodzaak voor kostbare fine-tuning van LLMs door aanvulling met externe data. - Transparantie
Biedt traceerbare, verifieerbare bronnen bij chatbotantwoorden.
Uitdagingen en aandachtspunten
- Latentie
Real-time ophaling kan vertraging veroorzaken, vooral bij meerstaps-pijplijnen. - Kosten
Meer API-calls naar LLMs of vectordatabases kunnen leiden tot hogere operationele kosten. - Gegevensprivacy
Gevoelige data moet veilig worden verwerkt, vooral in zelf-gehoste RAG-systemen. - Schaalbaarheid
Grootschalige pijplijnen vereisen efficiënte ontwerpen om knelpunten in dataophaling of opslag te voorkomen.
Toekomstige trends
- Agentische RAG-pijplijnen
Autonome agents die meerstaps-redeneringen en -ophaling uitvoeren. - Fijn-afgestelde embeddingmodellen
Domeinspecifieke embeddings voor verbeterd semantisch zoeken. - Integratie met multimodale data
Ophaling uitbreiden naar afbeeldingen, audio en video naast tekst.
Dankzij ophaal-pijplijnen zijn chatbots niet langer beperkt door de grenzen van statische trainingsdata, waardoor zij dynamische, precieze en contextrijke interacties kunnen leveren.
Onderzoek naar ophaal-pijplijnen voor chatbots
Ophaal-pijplijnen spelen een cruciale rol in moderne chatbotsystemen en maken intelligente en contextbewuste interacties mogelijk.
“Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” door Pengfei Zhu et al. (2018)
Introduceert Lingke, een chatbot die informatieophaling integreert om meerstapsgesprekken te ondersteunen. Het maakt gebruik van een fijnmazige pijplijnverwerking om antwoorden uit ongestructureerde documenten te destilleren en gebruikt aandachtige context-antwoordmatching voor sequentiële interacties, wat het vermogen van de chatbot om complexe gebruikersvragen te beantwoorden aanzienlijk verbetert.
Lees het artikel hier.“FACTS About Building Retrieval Augmented Generation-based Chatbots” door Rama Akkiraju et al. (2024)
Bespreekt de uitdagingen en methodologieën bij het ontwikkelen van enterprise-grade chatbots met Retrieval Augmented Generation (RAG)-pijplijnen en Large Language Models (LLMs). De auteurs stellen het FACTS-raamwerk voor, met nadruk op Freshness, Architectures, Cost, Testing en Security in RAG-pijplijn-engineering. Hun empirische bevindingen tonen de afwegingen tussen nauwkeurigheid en latentie bij het schalen van LLMs en bieden waardevolle inzichten voor het bouwen van veilige en hoogwaardige chatbots. Lees het artikel hier.“From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” door Subash Neupane et al. (2024)
Presenteert BARKPLUG V.2, een chatbotsysteem ontwikkeld voor universiteitsomgevingen. Door gebruik te maken van RAG-pijplijnen biedt het systeem nauwkeurige en domeinspecifieke antwoorden over campusvoorzieningen en verbetert zo de toegang tot informatie. De studie evalueert de effectiviteit van de chatbot met kaders zoals RAG Assessment (RAGAS) en toont de bruikbaarheid aan in academische omgevingen. Lees het artikel hier.
Veelgestelde vragen
- Wat is een ophaal-pijplijn in chatbots?
Een ophaal-pijplijn is een technische architectuur waarmee chatbots relevante informatie van externe bronnen kunnen ophalen, verwerken en terugvinden als reactie op gebruikersvragen. Het combineert data-inname, embedding, vectoropslag en LLM-antwoordgeneratie voor dynamische, contextbewuste antwoorden.
- Hoe verbetert Retrieval-Augmented Generation (RAG) chatbotantwoorden?
RAG combineert de sterke punten van dataophalingssystemen en grote taalmodellen (LLMs), waardoor chatbots hun antwoorden kunnen baseren op feitelijke, actuele externe data en zo hallucinaties verminderen en de nauwkeurigheid verhogen.
- Wat zijn typische componenten van een ophaal-pijplijn?
Belangrijke componenten zijn documentinname, voorbewerking, embeddinggeneratie, vectoropslag, queryverwerking, dataophaling, antwoordgeneratie en validatie na verwerking.
- Wat zijn gangbare toepassingen van ophaal-pijplijnen in chatbots?
Toepassingen zijn onder andere klantenservice, kennismanagement binnen ondernemingen, productinformatie in e-commerce, medische begeleiding, onderwijs en onderzoek, en ondersteuning bij naleving van wet- en regelgeving.
- Met welke uitdagingen moet ik rekening houden bij het bouwen van een ophaal-pijplijn?
Uitdagingen zijn onder meer latentie door real-time ophaling, operationele kosten, zorgen rond gegevensprivacy en schaalbaarheidseisen voor het verwerken van grote hoeveelheden data.
Begin met het bouwen van AI-gedreven chatbots met ophaal-pijplijnen
Ontgrendel de kracht van Retrieval-Augmented Generation (RAG) en externe data-integratie om intelligente, nauwkeurige chatbotantwoorden te leveren. Probeer vandaag nog FlowHunt’s no-code platform.
Meer informatie