SpaCy
spaCy is een snelle, efficiënte NLP-bibliotheek in Python, ideaal voor productie met functies zoals tokenisatie, POS-tagging en entity recognition.
spaCy is een robuuste open-source bibliotheek, speciaal ontwikkeld voor geavanceerde Natural Language Processing (NLP) in Python. Uitgebracht in 2015 door Matthew Honnibal en Ines Montani en onderhouden door Explosion AI, staat spaCy bekend om zijn efficiëntie, gebruiksvriendelijkheid en uitgebreide NLP-ondersteuning, waardoor het een favoriete keuze is voor productie boven onderzoeksgerichte bibliotheken zoals NLTK. Geïmplementeerd in Python en Cython zorgt het voor snelle en effectieve tekstverwerking.
Geschiedenis en vergelijking met andere NLP-bibliotheken
spaCy ontstond als een krachtig alternatief voor andere NLP-bibliotheken door te focussen op industrieel sterke snelheid en nauwkeurigheid. Waar NLTK een flexibele algoritmische aanpak biedt die geschikt is voor onderzoek en onderwijs, is spaCy ontworpen voor snelle inzet in productieomgevingen met vooraf getrainde modellen voor naadloze integratie. spaCy biedt een gebruiksvriendelijke API, ideaal voor het efficiënt verwerken van grote datasets, waardoor het geschikt is voor commerciële toepassingen. Vergelijkingen met andere bibliotheken, zoals Spark NLP en Stanford CoreNLP, benadrukken vaak spaCy’s snelheid en gebruiksgemak, waardoor het een optimale keuze is voor ontwikkelaars die robuuste, productieklare oplossingen nodig hebben.
Belangrijkste kenmerken van spaCy
Tokenisatie
Segmenteert tekst in woorden, leestekens, enzovoorts, terwijl de originele tekststructuur behouden blijft—cruciaal voor NLP-taken.Part-of-Speech Tagging
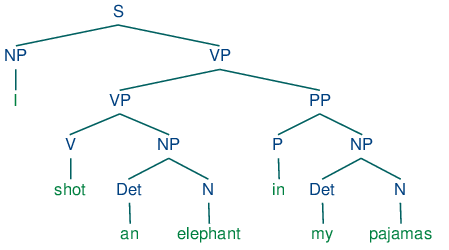
Wijs woordsoorten toe aan tokens zoals zelfstandige naamwoorden en werkwoorden, wat inzicht geeft in de grammaticale structuur van de tekst.Dependency Parsing
Analyseert de zinsstructuur om relaties tussen woorden vast te stellen, en identificeert syntactische functies zoals onderwerp of lijdend voorwerp.Named Entity Recognition (NER)
Herkent en categoriseert benoemde entiteiten in tekst, zoals personen, organisaties en locaties, essentieel voor informatie-extractie.Tekstclassificatie
Categoriseert documenten of delen daarvan, wat helpt bij informatieorganisatie en -opvraging.Vergelijking (Similarity)
Meet de gelijkenis tussen woorden, zinnen of documenten met behulp van woordvectoren.Regelgebaseerde matching
Vindt tokenreeksen op basis van hun teksten en taalkundige annotaties, vergelijkbaar met reguliere expressies.Multi-task learning met transformers
Integreert op transformers gebaseerde modellen zoals BERT, waardoor de nauwkeurigheid en prestaties bij NLP-taken toenemen.Visualisatietools
Bevat displaCy, een tool voor het visualiseren van syntaxis en benoemde entiteiten, wat de interpretatie van NLP-analyses verbetert.Aanpasbare pijplijnen
Maakt het mogelijk om NLP-workflows aan te passen door componenten toe te voegen of te wijzigen in de verwerkingspijplijn.
Toepassingen
Data Science en Machine Learning
spaCy is van onschatbare waarde in data science voor tekstvoorbewerking, feature-extractie en modeltraining. De integratie met frameworks zoals TensorFlow en PyTorch is cruciaal voor het ontwikkelen en uitrollen van NLP-modellen. Zo kan spaCy tekstgegevens voorbewerken door te tokeniseren, normaliseren en features zoals benoemde entiteiten te extraheren, die vervolgens gebruikt kunnen worden voor sentimentanalyse of tekstclassificatie.
Chatbots en AI-assistenten
Dankzij spaCy’s natuurlijke taalbegrip is het ideaal voor het ontwikkelen van chatbots en AI-assistenten. Het verwerkt taken zoals intentherkenning en entity-extractie, essentieel voor het bouwen van conversationele AI-systemen. Bijvoorbeeld, een chatbot met spaCy kan gebruikersvragen begrijpen door intenties te identificeren en relevante entiteiten te extraheren, waardoor het passende antwoorden kan genereren.
Informatie-extractie en tekstanalyse
Veel gebruikt voor het extraheren van gestructureerde informatie uit ongestructureerde tekst, kan spaCy entiteiten, relaties en gebeurtenissen categoriseren. Dit is nuttig in toepassingen zoals documentanalyse en kennisextractie. In juridische documentanalyse bijvoorbeeld, kan spaCy belangrijke informatie zoals betrokken partijen en juridische termen extraheren, waardoor documentreview wordt geautomatiseerd en werkprocessen efficiënter worden.
Onderzoek en academische toepassingen
Met zijn uitgebreide NLP-mogelijkheden is spaCy een waardevol hulpmiddel voor onderzoek en academisch gebruik. Onderzoekers kunnen taalkundige patronen onderzoeken, tekstcorpora analyseren en domeinspecifieke NLP-modellen ontwikkelen. Zo kan spaCy in een taalkundige studie worden ingezet om patronen in taalgebruik over verschillende contexten te identificeren.
Voorbeelden van spaCy in de praktijk
Named Entity Recognition
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("Apple is looking at buying U.K. startup for $1 billion") for ent in doc.ents: print(ent.text, ent.label_) # Output: Apple ORG, U.K. GPE, $1 billion MONEYDependency Parsing
for token in doc: print(token.text, token.dep_, token.head.text) # Output: Apple nsubj looking, is aux looking, looking ROOT looking, ...Tekstclassificatie
spaCy kan worden uitgebreid met aangepaste tekstclassificatiemodellen om tekst te categoriseren op basis van vooraf gedefinieerde labels.
Modelverpakking en -implementatie
spaCy biedt robuuste tools voor het verpakken en implementeren van NLP-modellen, waardoor productiegeschiktheid en eenvoudige integratie in bestaande systemen worden gegarandeerd. Dit omvat ondersteuning voor modelversiebeheer, afhankelijkheidsbeheer en workflowautomatisering.
Onderzoek naar SpaCy en gerelateerde onderwerpen
SpaCy is een veelgebruikte open-source bibliotheek in Python voor geavanceerde Natural Language Processing (NLP). Het is toegespitst op productiegebruik en ondersteunt verschillende NLP-taken zoals tokenisatie, part-of-speech tagging en named entity recognition. Recente wetenschappelijke artikelen benadrukken de toepassingen, verbeteringen en vergelijkingen met andere NLP-tools, wat ons inzicht in de mogelijkheden en implementaties ervan vergroot.
Geselecteerde wetenschappelijke artikelen
| Titel | Auteurs | Gepubliceerd | Samenvatting | Link |
|---|---|---|---|---|
| Multi hash embeddings in spaCy | Lester James Miranda, Ákos Kádár, Adriane Boyd, Sofie Van Landeghem, Anders Søgaard, Matthew Honnibal | 2022-12-19 | Bespreekt de implementatie van multi hash embeddings in spaCy om het geheugengebruik voor woordembeddings te verminderen. Deze aanpak wordt geëvalueerd op NER-datasets, waarbij ontwerpkeuzes worden bevestigd en onverwachte bevindingen aan het licht komen. | Lees meer |
| Resume Evaluation through Latent Dirichlet Allocation and Natural Language Processing for Effective Candidate Selection | Vidhita Jagwani, Smit Meghani, Krishna Pai, Sudhir Dhage | 2023-07-28 | Introduceert een methode voor cv-evaluatie met LDA en spaCy’s entity detection, behaalt 82% nauwkeurigheid en beschrijft de prestaties van spaCy’s NER. | Lees meer |
| LatinCy: Synthetic Trained Pipelines for Latin NLP | Patrick J. Burns | 2023-05-07 | Presenteert LatinCy, spaCy-compatibele NLP-pijplijnen voor Latijn, die hoge nauwkeurigheid tonen in POS-tagging en lemmatisering, en zo de aanpasbaarheid van spaCy demonstreren. | Lees meer |
| Launching into clinical space with medspaCy: a new clinical text processing toolkit in Python | Hannah Eyre, Alec B Chapman, et al. | 2021-06-14 | Introduceert medspaCy, een toolkit voor klinische tekstverwerking gebouwd op spaCy, die regelgebaseerde en ML-benaderingen voor klinische NLP integreert. | Lees meer |
Veelgestelde vragen
- Wat is spaCy?
spaCy is een open-source Python-bibliotheek voor geavanceerde Natural Language Processing (NLP), ontworpen voor snelheid, efficiëntie en productiegebruik. Het ondersteunt taken zoals tokenisatie, part-of-speech tagging, dependency parsing en named entity recognition.
- Hoe verschilt spaCy van NLTK?
spaCy is geoptimaliseerd voor productieomgevingen met vooraf getrainde modellen en een snelle, gebruiksvriendelijke API, waardoor het ideaal is voor het verwerken van grote datasets en commercieel gebruik. NLTK daarentegen is meer gericht op onderzoek en biedt flexibele algoritmische benaderingen die geschikt zijn voor onderwijs en experimentatie.
- Wat zijn enkele belangrijke kenmerken van spaCy?
Belangrijke kenmerken zijn onder andere tokenisatie, POS-tagging, dependency parsing, named entity recognition, tekstclassificatie, vergelijkingsmeting, regelgebaseerde matching, transformer-integratie, visualisatietools en aanpasbare NLP-pijplijnen.
- Wat zijn veelvoorkomende toepassingen van spaCy?
spaCy wordt veel gebruikt in data science voor tekstvoorbewerking en feature-extractie, bij het bouwen van chatbots en AI-assistenten, voor informatie-extractie uit documenten en in academisch onderzoek voor het analyseren van linguïstische patronen.
- Kan spaCy geïntegreerd worden met deep learning-frameworks?
Ja, spaCy kan geïntegreerd worden met frameworks zoals TensorFlow en PyTorch, wat een naadloze ontwikkeling en inzet van geavanceerde NLP-modellen mogelijk maakt.
- Is spaCy geschikt voor gespecialiseerde domeinen zoals de gezondheidszorg of juridisch?
Ja, spaCy's flexibele API en uitbreidbaarheid maken het mogelijk om het aan te passen voor gespecialiseerde domeinen, zoals klinische tekstverwerking (bijv. medspaCy) en juridische documentanalyse.
Ontdek AI met spaCy
Ontdek hoe spaCy jouw NLP-projecten kan versterken, van chatbots tot informatie-extractie en onderzoeksapplicaties.
Meer informatie