Transformers
Transformers zijn baanbrekende neurale netwerken die self-attention gebruiken voor parallelle gegevensverwerking en modellen als BERT en GPT aandrijven in NLP, beeldverwerking en meer.
Belangrijkste kenmerken van Transformers
- Transformer Architectuur: In tegenstelling tot traditionele modellen zoals recurrente neurale netwerken (RNNs) en convolutionele neurale netwerken (CNNs), maken transformers gebruik van een mechanisme dat self-attention heet. Hierdoor kunnen alle delen van een sequentie gelijktijdig worden verwerkt in plaats van achtereenvolgens, wat zorgt voor een efficiëntere verwerking van complexe data.
- Parallelle Verwerking: Deze architectuur maakt parallelle verwerking mogelijk, waardoor de rekentijd aanzienlijk wordt versneld en zeer grote modellen getraind kunnen worden. Dit is een groot verschil met RNNs, waar verwerking per definitie sequentieel en dus trager is.
- Attention Mechanisme: Centraal in het ontwerp van de transformer staat het attention-mechanisme, waarmee het model het belang van verschillende delen van de invoerdata kan wegen en zo langetermijnafhankelijkheden effectiever kan vastleggen. Dit vermogen om op verschillende delen van de datasequentie te letten, geeft transformers hun kracht en flexibiliteit in diverse taken.
Componenten van de Transformer Architectuur
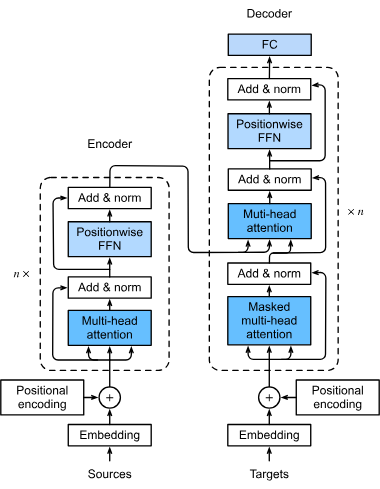
Invoer-Embeddings
De eerste stap in de verwerkingspipeline van een transformermodel is het omzetten van woorden of tokens in een invoersequentie naar numerieke vectoren, oftewel embeddings. Deze embeddings vangen semantische betekenissen op en zijn essentieel voor het model om de relaties tussen tokens te begrijpen. Deze transformatie is noodzakelijk zodat het model tekstdata in een wiskundige vorm kan verwerken.
Positionele Codering
Transformers verwerken data niet van nature sequentieel; daarom wordt positionele codering gebruikt om informatie over de positie van elk token in de sequentie toe te voegen. Dit is van vitaal belang om de volgorde van de sequentie te behouden, wat cruciaal is voor taken als taalvertaling waarbij de context afhankelijk kan zijn van de woordvolgorde.
Multi-Head Attention
Het multi-head attention-mechanisme is een geavanceerd onderdeel van transformers waarmee het model zich tegelijkertijd op verschillende delen van de invoersequentie kan richten. Door meerdere attention-scores te berekenen, kan het model diverse relaties en afhankelijkheden in de data vastleggen, wat het vermogen om complexe patronen te begrijpen en te genereren vergroot.
Encoder-Decoder Structuur
Transformers volgen doorgaans een encoder-decoder-architectuur:
- Encoder: Verwerkt de invoersequentie en genereert een representatie die de essentiële kenmerken daarvan vastlegt.
- Decoder: Gebruikt deze representatie om de uitvoersequentie te genereren, vaak in een ander domein of een andere taal. Deze structuur is bijzonder effectief bij taken zoals taalvertaling.
Feedforward Neurale Netwerken
Na het attention-mechanisme wordt de data door feedforward neurale netwerken geleid, die niet-lineaire transformaties op de data toepassen. Zo leert het model complexe patronen. Deze netwerken verwerken de data verder om de uiteindelijke output van het model te verfijnen.
Laagnormalisatie en Residuele Verbindingen
Deze technieken zijn ingebouwd om het trainingsproces te stabiliseren en te versnellen. Laagnormalisatie zorgt ervoor dat de outputs binnen een bepaald bereik blijven, wat efficiënt trainen bevordert. Residuele verbindingen maken het mogelijk dat gradiënten zonder te verdwijnen door het netwerk stromen, wat het trainen van diepe neurale netwerken verbetert.
Hoe werken Transformers?
Transformers werken op sequenties van data, zoals woorden in een zin of andere sequentiële informatie. Ze passen self-attention toe om te bepalen hoe relevant elk deel van de sequentie is ten opzichte van de andere delen, zodat het model zich kan richten op de belangrijkste elementen die het resultaat beïnvloeden.
Self-Attention Mechanisme
Bij self-attention wordt elk token in de sequentie vergeleken met elk ander token om attention-scores te berekenen. Deze scores geven aan hoe belangrijk elk token is in de context van de andere tokens, waardoor het model zich kan richten op de meest relevante delen van de sequentie. Dit is essentieel om context en betekenis in taalopdrachten te begrijpen.
Transformer Blokken
Dit zijn de bouwstenen van een transformermodel, bestaande uit self-attention- en feedforward-lagen. Meerdere blokken worden gestapeld om deep learning-modellen te vormen die complexe patronen in data kunnen vastleggen. Dankzij dit modulaire ontwerp kunnen transformers efficiënt opschalen met de complexiteit van de taak.
Voordelen ten opzichte van andere modellen
Efficiëntie en Schaalbaarheid
Transformers zijn efficiënter dan RNNs en CNNs doordat ze volledige sequenties in één keer kunnen verwerken. Deze efficiëntie maakt het mogelijk om zeer grote modellen te trainen, zoals GPT-3 met 175 miljard parameters. De schaalbaarheid van transformers stelt ze in staat om grote hoeveelheden data effectief te verwerken.
Omgaan met Langetermijnafhankelijkheden
Traditionele modellen hebben moeite met langetermijnafhankelijkheden vanwege hun sequentiële karakter. Transformers overwinnen deze beperking met self-attention, waarmee alle delen van de sequentie gelijktijdig kunnen worden verwerkt. Dit maakt ze bijzonder effectief voor taken waarbij begrip van context over lange tekstsequenties vereist is.
Veelzijdigheid in Toepassingen
Hoewel oorspronkelijk ontworpen voor NLP (natuurlijke taalverwerking), zijn transformers aangepast voor uiteenlopende toepassingen, zoals beeldherkenning, eiwitvouwing en zelfs tijdreeksvoorspellingen. Deze veelzijdigheid laat de brede toepasbaarheid van transformers in verschillende domeinen zien.
Toepassingen van Transformers
Natuurlijke Taalverwerking
Transformers hebben de prestaties van NLP-taken zoals vertaling, samenvatting en sentimentanalyse aanzienlijk verbeterd. Modellen als BERT en GPT zijn prominente voorbeelden die transformerarchitectuur gebruiken om menselijke tekst te begrijpen en te genereren, en zo nieuwe standaarden in NLP te zetten.
Machinetaalvertaling
Bij machinetaalvertaling blinken transformers uit door de context van woorden binnen een zin te begrijpen, waardoor ze nauwkeurigere vertalingen leveren dan eerdere methoden. Door volledige zinnen in één keer te verwerken, zijn vertalingen coherenter en contextueel correcter.
Eiwitstructuuranalyse
Transformers kunnen de sequenties van aminozuren in eiwitten modelleren, wat helpt bij het voorspellen van eiwitstructuren. Dit is van groot belang voor medicijnontwikkeling en het begrijpen van biologische processen. Deze toepassing benadrukt het potentieel van transformers in wetenschappelijk onderzoek.
Tijdreeksvoorspelling
Door de transformerarchitectuur aan te passen, is het mogelijk toekomstige waarden in tijdreeksdata te voorspellen, zoals voorspellingen van elektriciteitsvraag, door eerdere sequenties te analyseren. Dit opent nieuwe mogelijkheden voor transformers in sectoren als financiën en resource management.
Soorten Transformer Modellen
Bidirectional Encoder Representations from Transformers (BERT)
BERT-modellen zijn ontworpen om de context van een woord te begrijpen door naar omliggende woorden te kijken, wat ze zeer effectief maakt voor taken waarbij het begrijpen van woordrelaties binnen een zin cruciaal is. Deze bidirectionele benadering zorgt ervoor dat BERT context beter vastlegt dan unidirectionele modellen.
Generative Pre-trained Transformers (GPT)
GPT-modellen zijn autoregressief en genereren tekst door het volgende woord in een sequentie te voorspellen op basis van de voorgaande woorden. Ze worden veel gebruikt voor toepassingen zoals tekstaanvulling en dialooggeneratie, en laten zien dat ze in staat zijn om mensachtige tekst te genereren.
Vision Transformers
Oorspronkelijk ontwikkeld voor NLP zijn transformers aangepast voor beeldherkenningstaken. Vision transformers verwerken beelddata als sequenties, zodat ze transformer-technieken kunnen toepassen op visuele input. Deze aanpassing heeft geleid tot vooruitgang op het gebied van beeldherkenning en -verwerking.
Uitdagingen en Toekomstige Richtingen
Rekeneisen
Het trainen van grote transformermodellen vereist aanzienlijke rekenkracht, vaak met enorme datasets en krachtige hardware zoals GPU’s. Dit vormt een uitdaging in termen van kosten en toegankelijkheid voor veel organisaties.
Ethische Overwegingen
Naarmate transformers meer worden toegepast, worden kwesties als bias in AI-modellen en het ethisch gebruik van AI-gegenereerde inhoud steeds belangrijker. Onderzoekers werken aan methoden om deze problemen te beperken en verantwoordelijke AI-ontwikkeling te waarborgen, waarmee het belang van ethische kaders in AI-onderzoek wordt onderstreept.
Uitbreiding van Toepassingen
De veelzijdigheid van transformers opent voortdurend nieuwe wegen voor onderzoek en toepassing, van het verbeteren van AI-gedreven chatbots tot betere data-analyse in sectoren zoals gezondheidszorg en financiën. De toekomst van transformers biedt spannende mogelijkheden voor innovatie in verschillende industrieën.
Samengevat vertegenwoordigen transformers een belangrijke vooruitgang in AI-technologie, met ongeëvenaarde mogelijkheden voor het verwerken van sequentiële data. Hun innovatieve architectuur en efficiëntie hebben een nieuwe standaard gezet in het veld en AI-toepassingen naar een hoger niveau getild. Of het nu gaat om taalbegrip, wetenschappelijk onderzoek of beeldverwerking, transformers blijven de mogelijkheden van kunstmatige intelligentie herdefiniëren.
Onderzoek naar Transformers in AI
Transformers hebben het veld van kunstmatige intelligentie, met name op het gebied van natuurlijke taalverwerking en begrip, volledig getransformeerd. Het artikel “AI Thinking: A framework for rethinking artificial intelligence in practice” van Denis Newman-Griffis (gepubliceerd in 2024) verkent een nieuw conceptueel kader genaamd AI Thinking. Dit raamwerk modelleert de belangrijkste beslissingen en overwegingen bij het inzetten van AI vanuit verschillende disciplinaire perspectieven, en behandelt competenties als het motiveren van AI-gebruik, het formuleren van AI-methoden en het situeren van AI in sociotechnische contexten. Het doel is om bruggen te slaan tussen academische disciplines en de toekomst van AI in de praktijk te hervormen. Lees meer.
Een andere belangrijke bijdrage is te vinden in “Artificial intelligence and the transformation of higher education institutions” van Evangelos Katsamakas et al. (gepubliceerd in 2024), waarin een complex-systeem-benadering wordt gebruikt om de causale feedbackmechanismen van AI-transformatie in hogeronderwijsinstellingen (HEI’s) in kaart te brengen. De studie bespreekt de krachten die AI-transformatie aandrijven en de impact daarvan op waardecreatie, en benadrukt de noodzaak voor HEI’s om zich aan te passen aan AI-technologische vooruitgang, en tegelijkertijd academische integriteit en werkgelegenheid te beheren. Lees meer.
Op het gebied van softwareontwikkeling onderzoekt het artikel “Can Artificial Intelligence Transform DevOps?” van Mamdouh Alenezi en collega’s (gepubliceerd in 2022) de kruising van AI en DevOps. De studie belicht hoe AI de functionaliteit van DevOps-processen kan verbeteren en zo efficiënte softwarelevering kan bevorderen. Het benadrukt de praktische gevolgen voor softwareontwikkelaars en bedrijven die AI willen inzetten om DevOps-praktijken te transformeren. Lees meer
Veelgestelde vragen
- Wat zijn transformers in AI?
Transformers zijn een neurale netwerkarchitectuur die in 2017 werd geïntroduceerd en gebruikmaakt van self-attention-mechanismen voor parallelle verwerking van sequentiële data. Ze hebben kunstmatige intelligentie, met name op het gebied van natuurlijke taalverwerking en beeldherkenning, getransformeerd.
- Hoe verschillen transformers van RNNs en CNNs?
In tegenstelling tot RNNs en CNNs verwerken transformers alle elementen van een sequentie gelijktijdig met behulp van self-attention, wat zorgt voor meer efficiëntie, schaalbaarheid en het vermogen om langetermijnafhankelijkheden vast te leggen.
- Wat zijn gangbare toepassingen van transformers?
Transformers worden veel gebruikt voor NLP-taken zoals vertalingen, samenvattingen en sentimentanalyse, maar ook in beeldherkenning, eiwitstructuurvoorspellingen en tijdreeksvoorspellingen.
- Wat zijn enkele populaire transformermodellen?
Bekende transformermodellen zijn onder andere BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) en Vision Transformers voor beeldverwerking.
- Met welke uitdagingen worden transformers geconfronteerd?
Transformers vereisen aanzienlijke rekenkracht om te trainen en in te zetten. Ze brengen ook ethische vraagstukken met zich mee, zoals mogelijke bias in AI-modellen en verantwoord gebruik van generatieve AI-inhoud.
Klaar om je eigen AI te bouwen?
Slimme chatbots en AI-tools onder één dak. Verbind intuïtieve blokken en maak van je ideeën geautomatiseerde Flows.