
Woordembeddings
Woordembeddings koppelen woorden aan vectoren in een continue ruimte, waarbij hun betekenis en context worden vastgelegd voor verbeterde NLP-toepassingen.
Natural Language Processing (NLP) - Embeddings
Woordembeddings zijn cruciaal in NLP en vormen de brug tussen mens-computerinteractie. Ontdek vandaag de belangrijkste aspecten, werking en toepassingen!") om verschillende redenen:
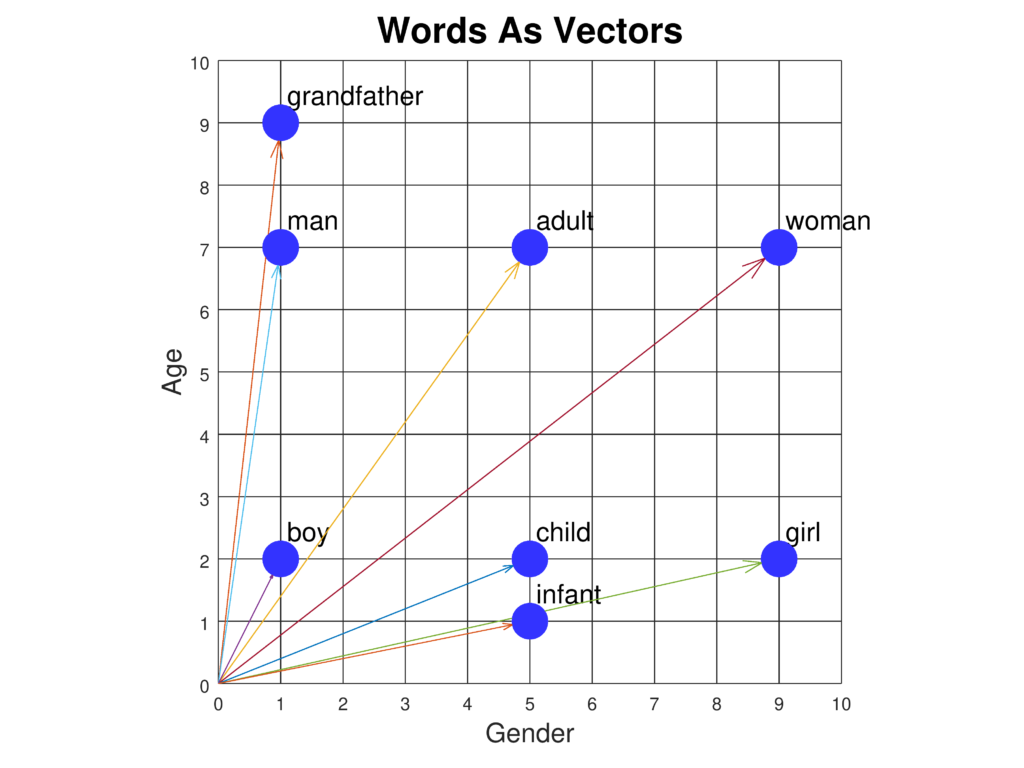
- Semantisch Begrip: Ze stellen modellen in staat de betekenis van woorden en hun onderlinge relaties vast te leggen, waardoor een genuanceerder begrip van taal mogelijk wordt. Zo kunnen embeddings analogieën weergeven zoals “koning staat tot koningin als man tot vrouw”.
- Dimensionaliteitsreductie: Het weergeven van woorden in een compacte, lagere dimensionale ruimte vermindert de rekenlast en verhoogt de efficiëntie bij het verwerken van grote woordenschatten.
- Transfer Learning: Voorgetrainde embeddings kunnen bij verschillende NLP-taken worden ingezet, waardoor minder taakgerichte data en rekenkracht nodig zijn.
- Omgaan met Grote Woordenschatten: Ze beheren efficiënt omvangrijke woordenschatten en behandelen zeldzame woorden effectiever, wat de modelprestaties op diverse datasets verbetert.
Kernconcepten en Technieken
- Vectorrepresentaties: Woorden worden getransformeerd tot vectoren in een hoge-dimensionale ruimte. De nabijheid en richting tussen deze vectoren duiden op semantische overeenkomsten en relaties tussen woorden.
- Semantische Betekenis: Embeddings vatten de semantische kern van woorden samen, waardoor modellen sentimentanalyse, entiteitsherkenning en machinale vertaling nauwkeuriger kunnen uitvoeren.
- Dimensionaliteitsreductie: Door hoge-dimensionale data om te zetten naar beter beheersbare formaten, verhogen embeddings de rekenefficiëntie van NLP-modellen.
- Neurale Netwerken: Veel embeddings worden gegenereerd met behulp van neurale netwerken, zoals bij modellen als Word2Vec en GloVe, die leren uit uitgebreide tekstcorpora.
Veelgebruikte Word Embedding Technieken
- Word2Vec: Ontwikkeld door Google; deze techniek gebruikt modellen zoals Continuous Bag of Words (CBOW) en Skip-gram om een woord te voorspellen op basis van zijn context of omgekeerd.
- GloVe (Global Vectors for Word Representation): Gebruikt wereldwijde co-occurrencestatistieken van woorden om embeddings af te leiden, waarbij semantische relaties via matrixfactorisatie worden benadrukt.
- FastText: Verbetert Word2Vec door subwoordinformatie (karakter n-grammen) te verwerken, waardoor zeldzame en onbekende woorden beter worden afgehandeld.
- TF-IDF (Term Frequency-Inverse Document Frequency): Een frequentiegebaseerde methode die belangrijke woorden in een document benadrukt ten opzichte van een corpus, maar mist de semantische diepgang van neurale embeddings.
Toepassingen in NLP
- Tekstclassificatie: Embeddings verbeteren tekstclassificatie door rijke semantische representaties te bieden, wat de nauwkeurigheid vergroot bij taken als sentimentanalyse en spamdetectie.
- Machinale Vertaling: Vergemakkelijken cross-linguale vertaling door semantische relaties vast te leggen, essentieel voor systemen zoals Google Translate.
- Named Entity Recognition (NER): Helpen bij het identificeren en classificeren van entiteiten zoals namen, organisaties en locaties door context en semantiek te begrijpen.
- Informatieopvraging en Zoeken: Verbeteren zoekmachines door semantische relaties vast te leggen, wat leidt tot relevantere en contextbewustere resultaten.
- Vraag-Antwoordsystemen: Verhogen het begrip van vragen en context, wat resulteert in nauwkeurigere en relevantere antwoorden.
Uitdagingen en Beperkingen
- Polysemie: Klassieke embeddings hebben moeite met woorden met meerdere betekenissen. Contextuele embeddings zoals BERT proberen dit op te lossen door verschillende vectoren te bieden afhankelijk van de context.
- Bias in Trainingsdata: Embeddings kunnen de vooroordelen uit de trainingsdata in stand houden, wat gevolgen heeft voor eerlijkheid en nauwkeurigheid van toepassingen.
- Schaalbaarheid: Embeddings trainen op grote corpora vereist aanzienlijke rekenkracht, hoewel technieken zoals subwoordembeddings en dimensionaliteitsreductie verlichting kunnen bieden.
Geavanceerde Modellen en Ontwikkelingen
- BERT (Bidirectional Encoder Representations from Transformers): Een transformer-gebaseerd model dat contextuele woordembeddings genereert door de gehele zin in beschouwing te nemen, wat uitmuntende prestaties oplevert op tal van NLP-taken.
- GPT (Generative Pre-trained Transformer): Richt zich op het produceren van samenhangende en contextueel relevante tekst en gebruikt embeddings om menselijke taal te begrijpen en te genereren.
Onderzoek naar Woordembeddings in NLP
Learning Word Sense Embeddings from Word Sense Definitions
Qi Li, Tianshi Li, Baobao Chang (2016) stellen een methode voor om het probleem van polysemische en homonieme woorden in woordembeddings aan te pakken door per woordbetekenis één embedding te creëren met behulp van definities. Hun aanpak maakt gebruik van corpus-gebaseerde training om hoogwaardige word sense embeddings te verkrijgen. De experimentele resultaten tonen verbeteringen in woordgelijkheids- en woordbetekenisdisambiguatietaken. De studie toont het potentieel aan van word sense embeddings voor het verbeteren van NLP-toepassingen. Lees meerNeural-based Noise Filtering from Word Embeddings
Kim Anh Nguyen, Sabine Schulte im Walde, Ngoc Thang Vu (2016) introduceren twee modellen voor het verbeteren van woordembeddings door ruis te filteren. Ze identificeren overbodige informatie in traditionele embeddings en stellen unsupervised leertechnieken voor om denoising embeddings te creëren. Deze modellen gebruiken een deep feedforward neural network om essentiële informatie te versterken en ruis te minimaliseren. De resultaten laten een betere prestatie van de denoising embeddings zien op benchmarktaken. Lees meerA Survey On Neural Word Embeddings
Erhan Sezerer, Selma Tekir (2021) geven een uitgebreid overzicht van neurale woordembeddings, hun ontwikkeling en impact op NLP. Het overzicht behandelt fundamentele theorieën en verschillende typen embeddings, zoals sense, morfeem en contextuele embeddings. Het artikel bespreekt ook benchmarkdatasets en prestatie-evaluaties en benadrukt het transformerende effect van neurale embeddings op NLP-taken. Lees meerImproving Interpretability via Explicit Word Interaction Graph Layer
Arshdeep Sekhon, Hanjie Chen, Aman Shrivastava, Zhe Wang, Yangfeng Ji, Yanjun Qi (2023) richten zich op het verbeteren van de modelinterpreteerbaarheid in NLP met WIGRAPH, een neurale netwerklaag die een globaal interactiegrafiek tussen woorden opbouwt. Deze laag kan in elke NLP-tekstclassificator worden geïntegreerd en verhoogt zowel de interpreteerbaarheid als de voorspellingsprestaties. De studie onderstreept het belang van woordinteracties bij het begrijpen van modelbeslissingen. Lees meerWord Embeddings for Banking Industry
Avnish Patel (2023) onderzoekt de toepassing van woordembeddings in de bankensector en benadrukt hun rol bij taken als sentimentanalyse en tekstclassificatie. De studie bekijkt het gebruik van zowel statische woordembeddings (zoals Word2Vec, GloVe) als contextuele modellen en legt de nadruk op hun impact op industrie-specifieke NLP-taken. Lees meer
Veelgestelde vragen
- Wat zijn woordembeddings?
Woordembeddings zijn compacte vectorrepresentaties van woorden, waarbij semantisch vergelijkbare woorden worden afgebeeld op nabijgelegen punten in een continue ruimte, zodat modellen context en relaties in taal kunnen begrijpen.
- Hoe verbeteren woordembeddings NLP-taken?
Ze verbeteren NLP-taken door semantische en syntactische relaties vast te leggen, de dimensionaliteit te verminderen, transfer learning mogelijk te maken en het omgaan met zeldzame woorden te verbeteren.
- Wat zijn gangbare technieken voor het creëren van woordembeddings?
Populaire technieken zijn onder andere Word2Vec, GloVe, FastText en TF-IDF. Neurale modellen zoals Word2Vec en GloVe leren embeddings uit grote tekstcorpora, terwijl FastText subwoordinformatie verwerkt.
- Met welke uitdagingen worden woordembeddings geconfronteerd?
Klassieke embeddings hebben moeite met polysemie (woorden met meerdere betekenissen), kunnen data-biases in stand houden en vereisen vaak aanzienlijke rekenkracht om op grote corpora te trainen.
- Hoe worden woordembeddings gebruikt in praktische toepassingen?
Ze worden gebruikt in tekstclassificatie, machinale vertaling, named entity recognition, informatieopvraging en vraag-antwoordsystemen om nauwkeurigheid en contextueel begrip te verbeteren.
Probeer FlowHunt voor NLP-oplossingen
Begin met het bouwen van geavanceerde AI-oplossingen met intuïtieve tools voor NLP, waaronder woordembeddings en meer.
Meer informatie
