
Document Retriever
De Document Retriever van FlowHunt verhoogt de nauwkeurigheid van AI door generatieve modellen te koppelen aan je eigen, up-to-date documenten en URL's. Zo krij...
4 min lezen
AI
Document Retrieval
+3
Leer hoe je de parameters ‘Vanaf H1 indien aanwezig’, ‘Laden vanaf pointer’ en ‘Sla Laatste Header over’ instelt.
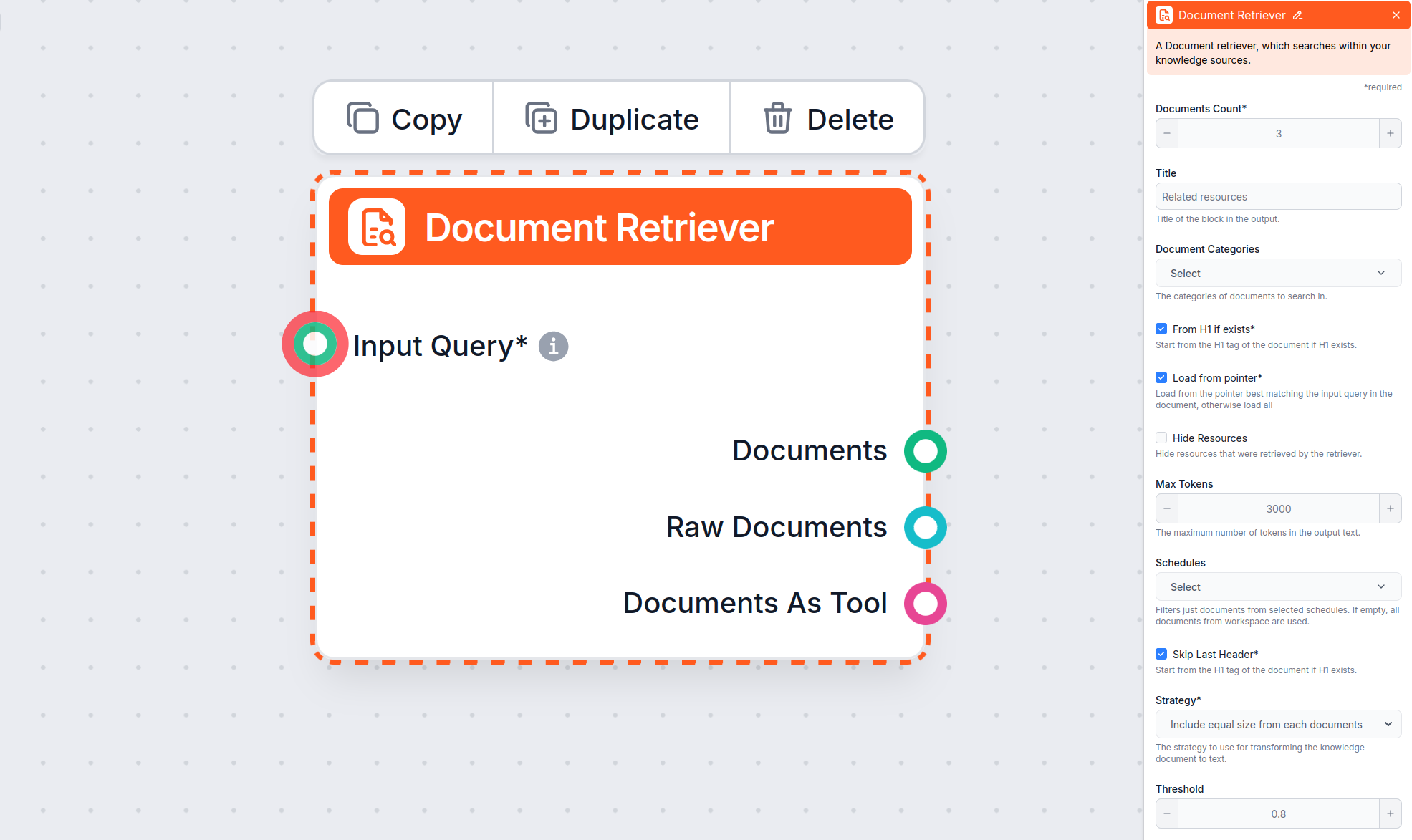
Document Retriever component stelt de chatbot in staat om kennis op te halen uit bronnen die je hebt opgegeven in de Documenten en Planningen. De rol van deze component is om de retrieval te sturen, en verschillende parameters beïnvloeden hoe de component informatie uit die documenten haalt.
De optie Vanaf H1 indien aanwezig geeft de retriever de instructie om content te gaan extraheren vanaf de H1-header die hij vindt (meestal de hoofdtitel van het artikel).
Wat gebeurt er?
Voorbeeldgebruik:
Je wilt alleen de daadwerkelijke handleiding ophalen, zonder enige site-navigatie of header-ruis die op je website aanwezig is.
Let op:
Vanaf H1 indien aanwezig staat standaard aan in de Document Retriever component.
Met de optie Laden vanaf pointer kun je preciezer werken door Document Retriever alleen data te laten laden vanaf een pointer in het mogelijk langere artikel.
Wat gebeurt er?
Wat is een “pointer”?
Een pointer is meestal een unieke string of kop in het document (bijvoorbeeld een H2 of een specifieke zin of sectietitel).
Voorbeeldgebruik:
Je wilt inleidende secties overslaan en informatie ophalen uit een specifiek relevante sectie van een mogelijk lang artikel of document (bijvoorbeeld vanaf “Stap 4: Voeg een livechatknop toe” in een installatiehandleiding).
De optie Sla Laatste Header over is handig om de laatste kop in het document te negeren, die vaak herhaald wordt of wordt gebruikt voor navigatie of als footer.
Wat gebeurt er?
Voorbeeldgebruik:
Je wilt voorkomen dat Document Retriever een navigatie-header uit de footer laadt (zoals “Andere artikelen” onderaan een help-pagina), zodat alleen de hoofdinhoud wordt verwerkt.
Let op:
Sla Laatste Header over kan helpen bij documenten die automatisch footers of herhalende navigatie-elementen genereren. Heb je dergelijke secties niet, dan kan het gebruik van deze parameter ervoor zorgen dat een deel van het artikel met geldige informatie niet wordt opgehaald. Het is daarom aanbevolen om deze optie pas aan te zetten als daar een geldige reden voor is.
Met de parameter Max tokens kun je bepalen wat het maximale aantal tokens (woorden en leestekens, zoals geteld door het onderliggende AI-model) is dat de Document Retriever zal teruggeven uit de geëxtraheerde tekst.
Wat gebeurt er?
Standaardwaarde:
De standaardwaarde is meestal 3000 tokens, maar je kunt dit aanpassen indien nodig.
Voorbeeldgebruik:
Als je lange documenten verwerkt, helpt een lagere Max tokens waarde om antwoorden beknopt te houden. Voor het beste resultaat kun je het beste ook de parameter “Laden vanaf pointer” inschakelen. Zo start de extractie bij het meest relevante deel van het document in plaats van bij het begin, zodat je een gefocust en beheersbaar stuk informatie krijgt binnen je opgegeven tokenlimiet. Deze combinatie is vooral handig als je beknopte, contextueel relevante output uit grote bronnen wilt halen.
Let op:
Merk je dat informatie wordt afgekapt, probeer dan de waarde van Max tokens te verhogen. Wil je juist kortere, meer gefocuste output, verlaag dan de Max tokens parameter.
Wanneer de Document Retriever meerdere relevante documenten vindt, bepaalt de parameter Strategie hoe ze worden samengevoegd tot één tekstoutput voor je chatbot, rekening houdend met de “Max tokens” limiet.
Twee strategieopties:
Inclusief gelijke grootte uit elk document:
De tokenlimiet wordt gelijk verdeeld. Bijvoorbeeld: bij drie documenten en een limiet van 3.000 tokens krijgt elk maximaal 1.000 tokens. Zo leveren alle bronnen evenveel bij, wat handig is als je een evenwichtig antwoord wilt dat uit meerdere documenten is opgebouwd.
Concateneer documenten, vul vanaf het eerste tot aan de tokenslimiet:
Documenten worden toegevoegd op volgorde van relevantie tot de tokenslimiet is bereikt. Het meest relevante document vult eerst de ruimte; als er nog plaats is, worden minder relevante documenten toegevoegd. Is het eerste document lang, dan kan het alleen al de hele limiet vullen.
Hoe kies je?
Let op:
Deze strategieën bepalen alleen hoe de tekst uit de opgehaalde documenten wordt opgebouwd voordat deze naar de volgende stap gaat (zoals AI-generatie). Ze veranderen niet welke documenten opgehaald worden—alleen hoe hun inhoud wordt samengevoegd en ingekort binnen de Max tokens-instelling.
Hoewel dit artikel zich richt op het instellen van de parameters ‘Vanaf H1 indien aanwezig’, ‘Laden vanaf pointer’, ‘Sla Laatste Header over’ en ‘Max tokens’, biedt de Document Retriever ook aanvullende parameters die bepalen hoe documenten geselecteerd en opgehaald worden:
Deze instelling beperkt het aantal documenten dat de flow moet ophalen, zodat de resultaten relevant blijven en antwoorden snel gegenereerd kunnen worden.
Met deze optionele instelling kun je ophalen beperken tot één of meer categorieën die je hebt aangemaakt in het onderdeel Documenten van Kennisbronnen.
Hiermee kun je een apart gedeelte, vóór het eigenlijke chatbot-antwoord, met een lijst van opgehaalde bronnen door de retriever laten opnemen of juist verbergen. Voor integratie met LiveAgent moet dit aangevinkt zijn, omdat deze sectie niet wordt ondersteund en niet goed wordt weergegeven in de LiveAgent chatbot-widget.
Hiermee kun je ophalen beperken tot één of meer Planningen die je hebt opgegeven voor het crawlen of updaten van content in Kennisbronnen.
Bepaalt hoe goed de opgehaalde documenten moeten aansluiten op de inputvraag, op basis van een relevantiescore (van 0 tot 1). Voor zeer relevante antwoorden wordt een drempel van 0,7–0,8 aanbevolen. Hoe hoger de drempel, hoe preciezer de matches; lagere drempels nemen mogelijk minder relevante documenten mee.
Voorbeeld:
Als je een drempel van 0,6 instelt en vier artikelen hebt met relevantiescores van 0,8, 0,65, 0,5 en 0,9, dan worden alleen die boven 0,6 (dus 0,8, 0,65 en 0,9) gebruikt voor extractie.
Als het antwoord van de chatbot geen informatie bevat waarvan je zeker weet dat deze aanwezig is in jouw documenten of planningen, controleer dan de gespreksgeschiedenis met de optie “Verbose” om gedetailleerde logs te zien of de Document Retriever is gebruikt en welke documenten zijn opgehaald. Pas indien nodig je instellingen en prompt aan op basis van deze logs.
De Document Retriever van FlowHunt verhoogt de nauwkeurigheid van AI door generatieve modellen te koppelen aan je eigen, up-to-date documenten en URL's. Zo krij...
Je chatbot kan direct documenten, HTML-pagina's en zelfs YouTube-video's benaderen en gebruiken om jouw unieke context vorm te geven. Perfect om informatie toe ...
Integreer uw workflows met Google Docs via de Google Docs Retriever-component—haal naadloos documentinhoud op voor gebruik in automatiseringen, chatbots of kenn...