
arXiv MCP Server
Verbind je AI-workflows met arXiv via de arXiv MCP Server. Zoek, haal op en laad wetenschappelijke artikelen rechtstreeks in je door LLM aangedreven onderzoeksassistenten.

Wat doet de “arXiv” MCP Server?
De arXiv MCP Server is een Model Context Protocol (MCP) server die ontworpen is voor naadloze interactie met de arXiv API via natuurlijke taal. Het fungeert als brug tussen AI-assistenten en de arXiv-repository van wetenschappelijke artikelen, waardoor ontwikkelaars en AI-agenten artikelmetadata kunnen ophalen, geavanceerd kunnen zoeken, PDF’s kunnen downloaden en artikelinhoud direct in de context van een groot taalmodel kunnen laden. Dit verbetert onderzoeksworkflows door informatieopslag, documentbeheer en contextuele data-verrijking voor LLM’s te automatiseren, zodat wetenschappelijk onderzoek toegankelijker en efficiënter wordt.
Lijst van Prompts
Er worden geen prompt-templates genoemd in de repository.
Lijst van Bronnen
Er zijn geen expliciete MCP-bronnen vermeld in de repository.
Lijst van Tools
get_article_url
Haalt de URL op van een artikel dat wordt gehost op arXiv.org op basis van de titel.
Parameters:title(String)download_article
Downloadt het artikel van arXiv.org als PDF-bestand naar de lokale machine.
Parameters:title(String)load_article_to_context
Laadt de artikelinhoud in de context van een groot taalmodel voor verdere verwerking.
Parameters:title(String)get_details
Haalt metadata van een artikel van arXiv.org op basis van de titel.
Parameters:title(String)search_arxiv
Voert een uitgebreide zoekopdracht uit op de arXiv API en geeft overeenkomende artikelmetadata terug.
Parameters:all_fields(String): Algemene zoektermtitle(String): Zoek in titelsauthor(String): Filter op auteursnaamabstract(String): Zoek in samenvattingenstart(int): Index van het eerste resultaat dat wordt weergegeven
Gebruiksscenario’s van deze MCP Server
- Academisch literatuuronderzoek
AI-assistenten of ontwikkelaars kunnen de server gebruiken om in de uitgebreide database van arXiv relevante artikelen te zoeken met zoekwoorden, auteursnamen of onderwerpen, waardoor het onderzoeksproces wordt gestroomlijnd. - Automatisch ophalen van documenten
Maakt het mogelijk PDF’s van specifieke artikelen direct te downloaden via tool-calls, wat snelle toegang tot originele wetenschappelijke publicaties faciliteert. - Contextueel laden van data voor LLM’s
Artikelinhoud kan in de context van een LLM geladen worden, waardoor geavanceerde vraagbeantwoording, samenvatting of analyse mogelijk wordt. - Metadata-extractie
Haal eenvoudig gedetailleerde metadata (auteurs, titels, samenvattingen) van artikelen op basis van natuurlijke taalvragen op, ter ondersteuning van bibliografische toepassingen. - Integratie in AI-gedreven onderzoeksassistenten
Vormt de ruggengraat voor AI-assistenten die onderzoekers helpen op de hoogte te blijven door het tonen van de nieuwste publicaties binnen interessegebieden.
Hoe stel je het in
Windsurf
- Zorg dat je Python 3.13+ geïnstalleerd hebt als vereiste.
- Clone de arXiv MCP server repository en installeer de afhankelijkheden.
- Bewerk je Windsurf configuratiebestand om de arXiv MCP server toe te voegen.
- Voeg het volgende JSON-fragment toe onder het object
mcpServers:
{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"]
}
}
- Sla de configuratie op en herstart Windsurf.
- Controleer of de server draait en bereikbaar is.
API-sleutels beveiligen:
Als de server of tools API-sleutels vereisen, sla deze dan op als omgevingsvariabelen en verwijs ernaar in je configuratie:
{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"],
"env": {
"ARXIV_API_KEY": "<your-api-key>"
},
"inputs": {
"api_key": "${env.ARXIV_API_KEY}"
}
}
}
Claude
- Installeer Python 3.13+ en clone de arXiv MCP server repository.
- Zoek het configuratiebestand van Claude’s MCP server op.
- Voeg het volgende toe onder
mcpServers:
{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"]
}
}
- Sla de wijzigingen op en herstart Claude.
- Controleer of de server wordt herkend door Claude.
Cursor
- Controleer of Python 3.13+ geïnstalleerd is en clone de repository.
- Open het configuratiebestand van Cursor.
- Voeg de arXiv MCP server als volgt toe:
{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"]
}
}
- Sla op en herstart Cursor.
- Test de integratie.
Cline
- Installeer Python 3.13+ en clone de server-repo.
- Bewerk het configuratiebestand van Cline om de server te registreren.
- Voeg dit blok toe:
{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"]
}
}
- Sla op en herstart Cline.
- Controleer de connectiviteit.
Let op:
Beveilig altijd gevoelige informatie zoals API-sleutels met omgevingsvariabelen, zoals weergegeven in het bovenstaande voorbeeld.
Hoe gebruik je deze MCP in flows
MCP gebruiken in FlowHunt
Om MCP-servers te integreren in je FlowHunt-workflow, begin je met het toevoegen van het MCP-component aan je flow en verbind je deze met je AI-agent:
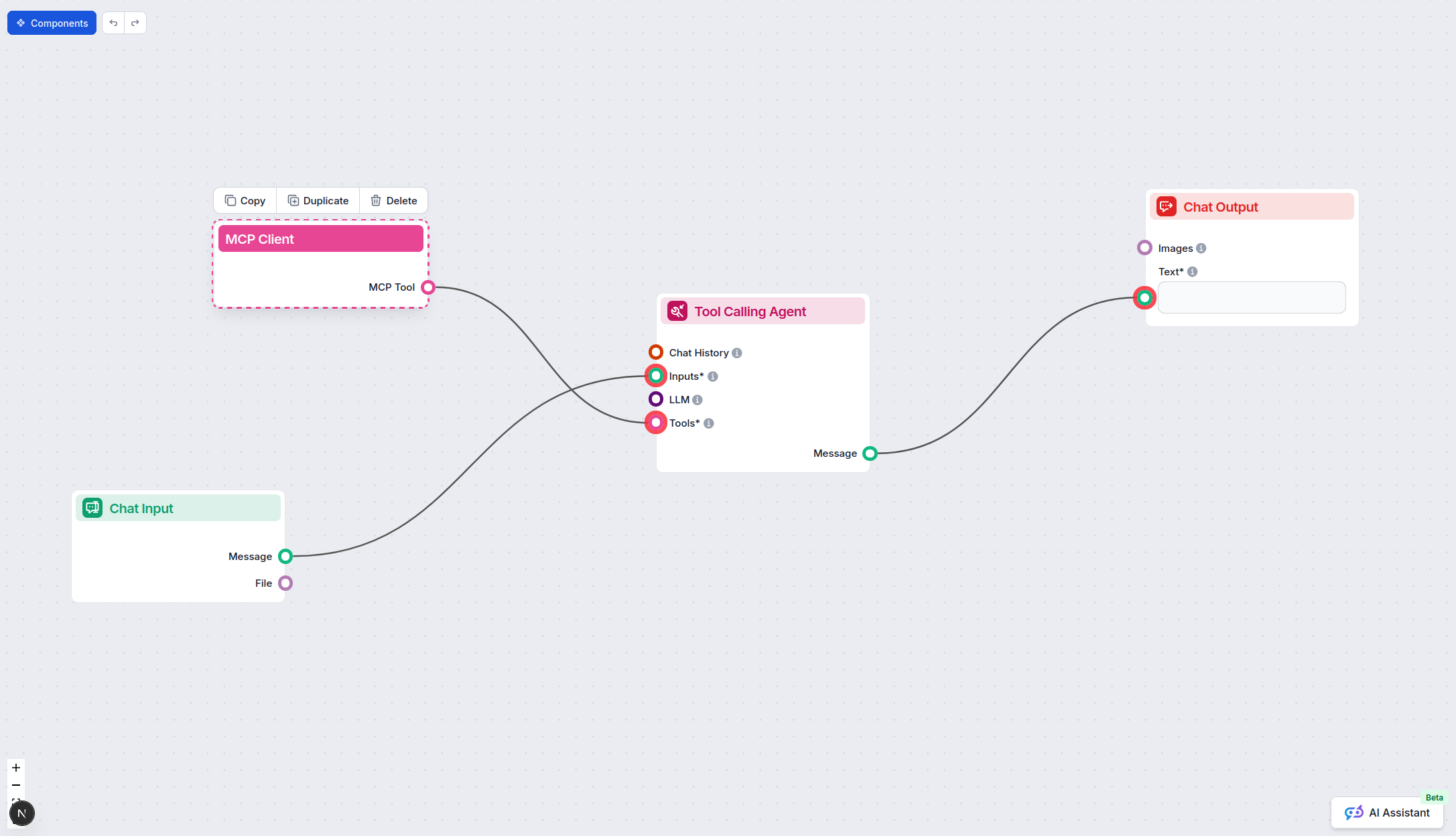
Klik op het MCP-component om het configuratiepaneel te openen. Voeg in het systeem-MCP-configuratiegedeelte je MCP-servergegevens toe met het volgende JSON-formaat:
{
"arxiv-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Eenmaal geconfigureerd kan de AI-agent deze MCP nu als tool gebruiken en toegang krijgen tot alle functies en mogelijkheden. Vergeet niet “arxiv-mcp” te vervangen door de naam van je eigen server en de URL door de URL van jouw MCP-server.
Overzicht
| Sectie | Beschikbaarheid | Details/Opmerkingen |
|---|---|---|
| Overzicht | ✅ | |
| Lijst van Prompts | ⛔ | Geen gevonden |
| Lijst van Bronnen | ⛔ | Geen gevonden |
| Lijst van Tools | ✅ | |
| API-sleutels beveiligen | ✅ | Instructie aanwezig |
| Sampling Support (minder belangrijk) | ⛔ | Niet genoemd |
Onze mening
De arXiv MCP Server biedt een gericht pakket tools voor het ophalen van wetenschappelijke artikelen en integratie met LLM-workflows. De documentatie is duidelijk over de functies en de installatie, en het is open source onder MIT. Er worden echter geen prompt-templates of expliciete bronnen aangeboden en sampling of roots support wordt niet genoemd. Voor gebruikers die arXiv-integratie nodig hebben is het een degelijke en betrouwbare optie, maar het mist enkele geavanceerde MCP-functies.
MCP Score
| Heeft een LICENSE | ✅ (MIT) |
|---|---|
| Heeft minstens één tool | ✅ |
| Aantal forks | 1 |
| Aantal sterren | 4 |
Veelgestelde vragen
- Wat is de arXiv MCP Server?
De arXiv MCP Server is een Model Context Protocol-server waarmee AI-assistenten en ontwikkelaars kunnen communiceren met de arXiv-database van wetenschappelijke artikelen via natuurlijke taal. Het ondersteunt zoeken, ophalen van metadata, downloaden van PDF's en het laden van artikelinhoud in grote taalmodellen.
- Welke tools biedt de arXiv MCP Server?
Het biedt tools voor het ophalen van artikel-URL's, PDF-downloads, laden van artikelinhoud in LLM's, metadata-extractie en geavanceerde zoekopdrachten met filters zoals titel, auteur en samenvatting.
- Hoe beveilig ik mijn API-sleutels met de arXiv MCP Server?
API-sleutels (indien vereist) moeten als omgevingsvariabelen worden opgeslagen en in je MCP-serverconfiguratie worden gebruikt. Voorbeeld: { \"arxiv-mcp\": { \"command\": \"python\", \"args\": [\"-m\", \"arxiv_server\"], \"env\": { \"ARXIV_API_KEY\": \"
\" }, \"inputs\": { \"api_key\": \"${env.ARXIV_API_KEY}\" } } } - Kan ik volledige artikelinhoud laden in mijn LLM-agent?
Ja, de tool 'load_article_to_context' maakt het mogelijk om de volledige inhoud van een arXiv-artikel direct in de context van je LLM te laden voor samenvatting, beantwoording van vragen of verdere analyse.
- Is de arXiv MCP Server open source?
Ja, het is open source onder de MIT-licentie.
Integreer arXiv met FlowHunt
Geef je onderzoeksflows een boost door arXiv te koppelen aan je AI-agenten met de arXiv MCP Server. Automatiseer literatuuronderzoek, metadata-extractie en meer.
Meer informatie

