
Databricks MCP Server
Verbind je AI-agenten met Databricks voor geautomatiseerde SQL, taakmonitoring en workflowbeheer met behulp van de Databricks MCP Server in FlowHunt.

Wat doet de “Databricks” MCP Server?
De Databricks MCP (Model Context Protocol) Server is een gespecialiseerd hulpmiddel dat AI-assistenten verbindt met het Databricks-platform, waardoor naadloze interactie met Databricks-resources via natuurlijke taalinterfaces mogelijk wordt. Deze server fungeert als brug tussen grote taalmodellen (LLM’s) en Databricks-API’s, waardoor LLM’s SQL-query’s kunnen uitvoeren, taken kunnen weergeven, taakstatussen kunnen ophalen en gedetailleerde taakgegevens kunnen verkrijgen. Door deze mogelijkheden via het MCP-protocol beschikbaar te maken, stelt de Databricks MCP Server ontwikkelaars en AI-agenten in staat om dataworkflows te automatiseren, Databricks-taken te beheren en database-operaties te stroomlijnen, waardoor de productiviteit in datagedreven ontwikkelomgevingen wordt verhoogd.
Lijst van prompts
Er zijn geen prompt-templates beschreven in de repository.
Lijst van bronnen
Er worden geen expliciete bronnen vermeld in de repository.
Lijst van tools
- run_sql_query(sql: str)
Voer SQL-query’s uit op het Databricks SQL-warehouse. - list_jobs()
Toon alle Databricks-taken in de workspace. - get_job_status(job_id: int)
Haal de status op van een specifieke Databricks-taak aan de hand van het ID. - get_job_details(job_id: int)
Verkrijg gedetailleerde informatie over een specifieke Databricks-taak.
Gebruikstoepassingen van deze MCP Server
- Automatisering van databasequery’s
Sta LLM’s en gebruikers toe SQL-query’s uit te voeren op Databricks-warehouses rechtstreeks vanuit conversatie-interfaces, waardoor data-analyseworkflows worden gestroomlijnd. - Taakbeheer
Toon en monitor Databricks-taken, zodat gebruikers overzicht houden over lopende of geplande taken binnen hun workspace. - Taakstatus bijhouden
Haal snel de status op van specifieke Databricks-taken, voor efficiënte monitoring en troubleshooting. - Gedetailleerde taakanalyse
Krijg diepgaande informatie over Databricks-taken, wat helpt bij debugging en optimalisatie van ETL-pijplijnen of batch-taken.
Hoe stel je het in
Windsurf
- Zorg dat Python 3.7+ geïnstalleerd is en Databricks-inloggegevens beschikbaar zijn.
- Clone de repository en installeer de benodigde pakketten met
pip install -r requirements.txt. - Maak een
.env-bestand aan met je Databricks-inloggegevens. - Voeg de Databricks MCP Server toe aan je Windsurf-configuratie:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Sla de configuratie op en herstart Windsurf. Controleer de installatie door een testquery uit te voeren.
API-sleutels beveiligen, voorbeeld:
{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"],
"env": {
"DATABRICKS_HOST": "${DATABRICKS_HOST}",
"DATABRICKS_TOKEN": "${DATABRICKS_TOKEN}",
"DATABRICKS_HTTP_PATH": "${DATABRICKS_HTTP_PATH}"
}
}
}
}
Claude
- Installeer Python 3.7+ en clone de repo.
- Zet het
.env-bestand op met Databricks-inloggegevens. - Configureer de MCP-interface van Claude:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Herstart Claude en valideer de verbinding.
Cursor
- Clone de repository en stel de Python-omgeving in.
- Installeer afhankelijkheden en maak een
.env-bestand aan met je inloggegevens. - Voeg de server toe aan de configuratie van Cursor:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Sla de configuratie op en test de verbinding.
Cline
- Bereid Python en inloggegevens voor zoals hierboven.
- Clone de repository, installeer de vereisten en configureer
.env. - Voeg een MCP-serververmelding toe aan de configuratie van Cline:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Sla op, herstart Cline en controleer of de MCP Server werkt.
Let op: Beveilig je API-sleutels en geheimen altijd door gebruik te maken van omgevingsvariabelen zoals getoond in de bovenstaande configuratievoorbeelden.
Hoe gebruik je deze MCP binnen flows
MCP gebruiken in FlowHunt
Om MCP-servers te integreren in je FlowHunt-workflow, voeg je het MCP-component toe aan je flow en verbind je deze met je AI-agent:
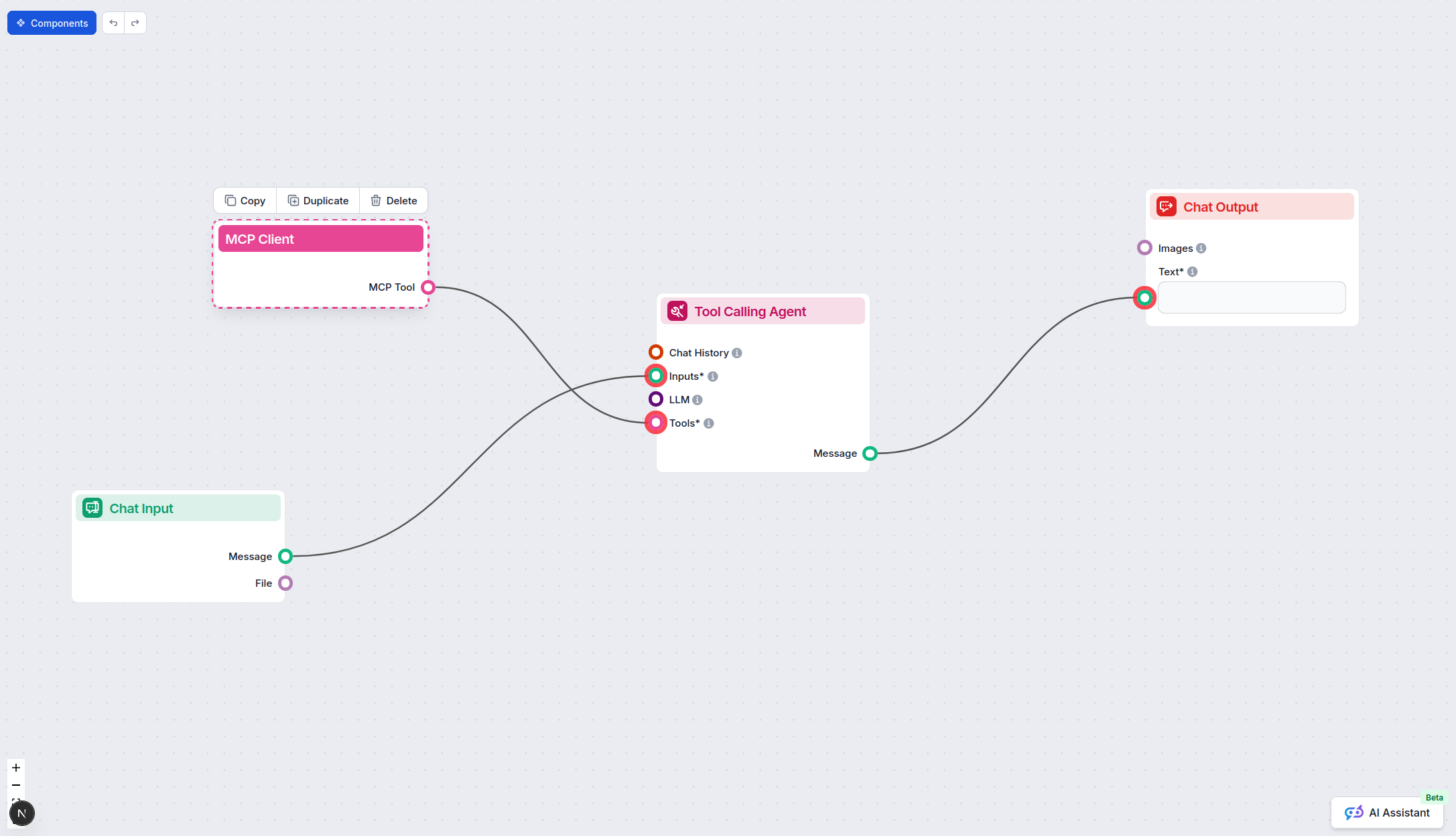
Klik op het MCP-component om het configuratiescherm te openen. Voeg in het systeem-MCP-configuratiegedeelte je MCP-servergegevens toe in het volgende JSON-formaat:
{
"databricks": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Zodra geconfigureerd, kan de AI-agent deze MCP nu als tool gebruiken met toegang tot alle functies en mogelijkheden. Vergeet niet “databricks” te vervangen door de daadwerkelijke naam van jouw MCP-server en de URL aan te passen naar jouw eigen MCP-server-URL.
Overzicht
| Sectie | Beschikbaar | Details/Opmerkingen |
|---|---|---|
| Overzicht | ✅ | |
| Lijst van prompts | ⛔ | Geen prompt-templates gespecificeerd in repo |
| Lijst van bronnen | ⛔ | Geen expliciete bronnen gedefinieerd |
| Lijst van tools | ✅ | 4 tools: run_sql_query, list_jobs, get_job_status, get_job_details |
| API-sleutels beveiligen | ✅ | Via omgevingsvariabelen in .env en config JSON |
| Sampling Support (minder belangrijk bij evaluatie) | ⛔ | Niet vermeld |
| Roots Support | ⛔ | Niet vermeld |
Op basis van de beschikbaarheid van kernfuncties (tools, installatie- en beveiligingsinstructies, maar geen bronnen of prompt-templates) is de Databricks MCP Server effectief voor Databricks API-integratie, maar ontbreken er enkele geavanceerde MCP-primitieven. Ik zou deze MCP Server een 6 uit 10 geven voor algehele volledigheid en nut binnen het MCP-ecosysteem.
MCP Score
| Heeft een LICENTIE | ⛔ (niet gevonden) |
|---|---|
| Heeft minstens één tool | ✅ |
| Aantal forks | 13 |
| Aantal sterren | 33 |
Veelgestelde vragen
- Wat is de Databricks MCP Server?
De Databricks MCP Server is een brug tussen AI-assistenten en Databricks, en stelt Databricks-functies zoals SQL-uitvoering en taakbeheer beschikbaar via het MCP-protocol voor geautomatiseerde workflows.
- Welke operaties ondersteunt deze MCP Server?
Het ondersteunt het uitvoeren van SQL-query's, het weergeven van alle taken, het opvragen van taakstatussen en het verkrijgen van gedetailleerde informatie over specifieke Databricks-taken.
- Hoe bewaar ik mijn Databricks-inloggegevens veilig?
Gebruik altijd omgevingsvariabelen, bijvoorbeeld door ze in een `.env`-bestand te plaatsen of ze te configureren in je MCP-serverinstellingen, in plaats van gevoelige informatie hardcoded op te slaan.
- Kan ik deze server gebruiken in FlowHunt-flows?
Ja, voeg simpelweg het MCP-component toe aan je flow, configureer het met je Databricks MCP-servergegevens en je AI-agenten hebben toegang tot alle ondersteunde Databricks-functies.
- Wat is de algemene nutsscore van deze MCP Server?
Op basis van beschikbare tools, installatie-instructies en beveiligingsondersteuning, maar met een gebrek aan bronnen en prompttemplates, scoort deze MCP Server een 6 uit 10 op volledigheid in het MCP-ecosysteem.
Geef je Databricks-workflows een boost
Automatiseer SQL-query's, monitor taken en beheer Databricks-resources direct vanuit conversatie-AI-interfaces. Integreer de Databricks MCP Server in je FlowHunt-flows voor productiviteit op het hoogste niveau.
Meer informatie

