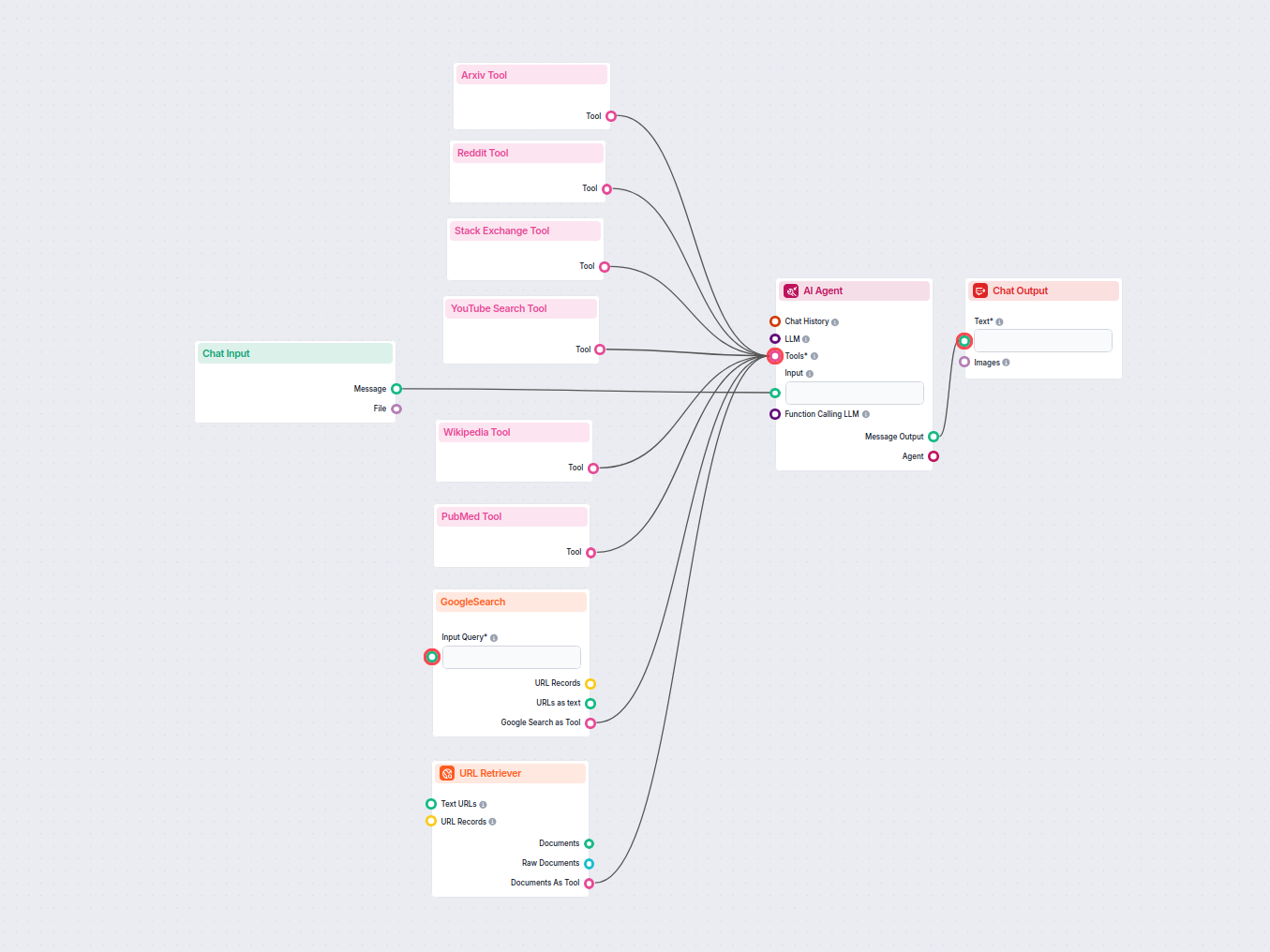
Opis przepływu
Cel i korzyści
Przegląd
Asystent Wikipedia RIG (Retrieval Interleaved Generator) to zautomatyzowany przepływ pracy zaprojektowany do odpowiadania na pytania użytkowników poprzez generowanie wstępnych odpowiedzi, identyfikację potrzebnych faktów, pobieranie informacji z Wikipedii oraz dopracowywanie odpowiedzi z precyzyjnymi cytowaniami dla każdej sekcji. Jego głównym celem jest dostarczanie odpowiedzi opartych na weryfikowalnych źródłach i dokładne wskazanie, które sekcje oraz źródła zostały wykorzystane, co czyni ten workflow szczególnie przydatnym w badaniach, fact-checkingu oraz edukacji.
Jak działa przepływ pracy
Rozpoczęcie czatu i powitanie
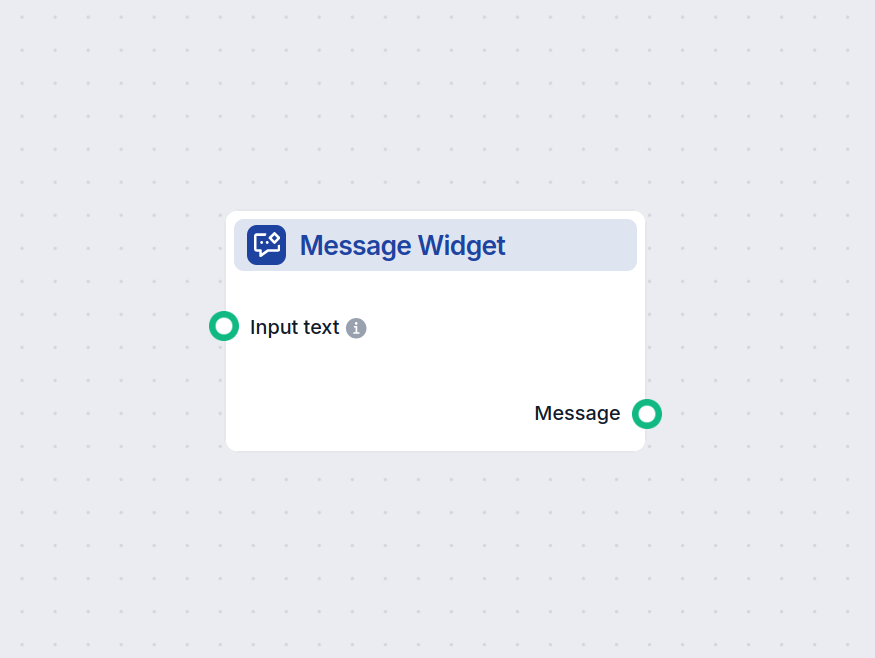
- Po otwarciu sesji czatu użytkownik otrzymuje powitanie wyjaśniające cel działania: dostarczanie wiarygodnych odpowiedzi popartych źródłami. Pomaga to ustalić oczekiwania wobec jakości i przejrzystości odpowiedzi.
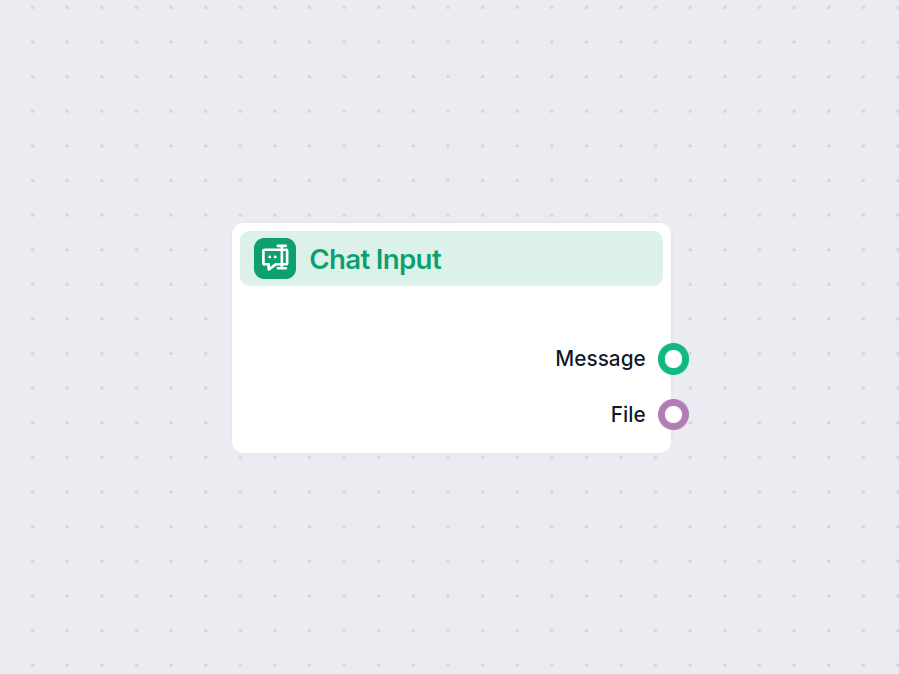
Przyjęcie pytania użytkownika
- Użytkownik przesyła pytanie przez pole czatu. To wejście jest rejestrowane i przekazywane do dalszego przetwarzania.
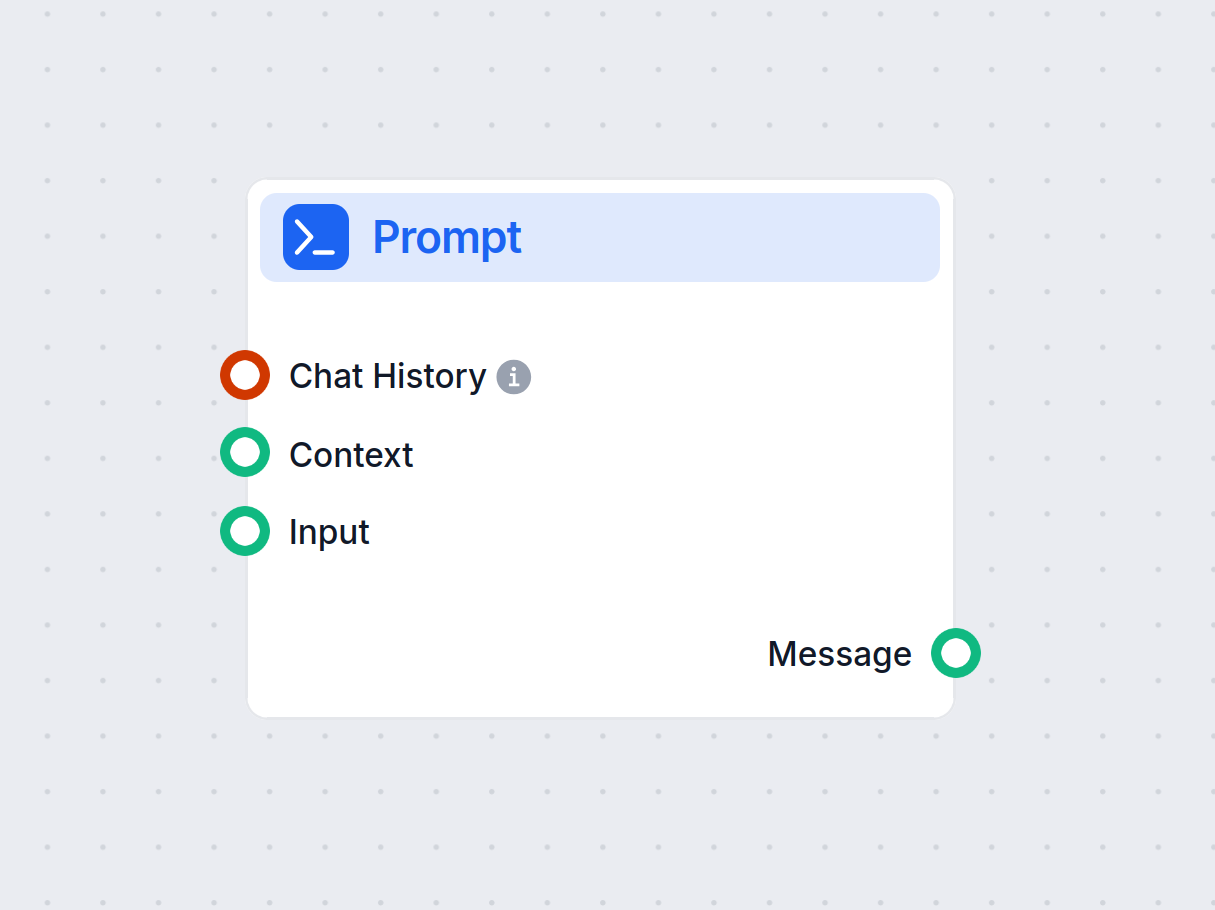
Generowanie prompta
- Przepływ pracy zawiera Szablon Promptu, który bierze pytanie użytkownika i buduje szczegółowy prompt. Ten prompt instruuje system, aby:
- Wygenerować roboczą odpowiedź, nawet jeśli zawiera ona dane zastępcze.
- W każdej sekcji odpowiedzi wskazać, które zewnętrzne źródło (np. Wikipedia) lub wewnętrzna baza wiedzy powinny zostać użyte do weryfikacji i dopracowania tej sekcji.
- Dołączyć zapytania wyszukiwania do Wikipedii, by pobrać poprawne informacje dla każdej sekcji.
Przykład:
Wpis użytkownika: Które kraje są liderami w odnawialnych źródłach energii?
Odpowiedź robocza: Najlepsze kraje to Norwegia, Szwecja, Portugalia [Wyszukaj w Wikipedii: "Top Countries in renewable Energy"]...
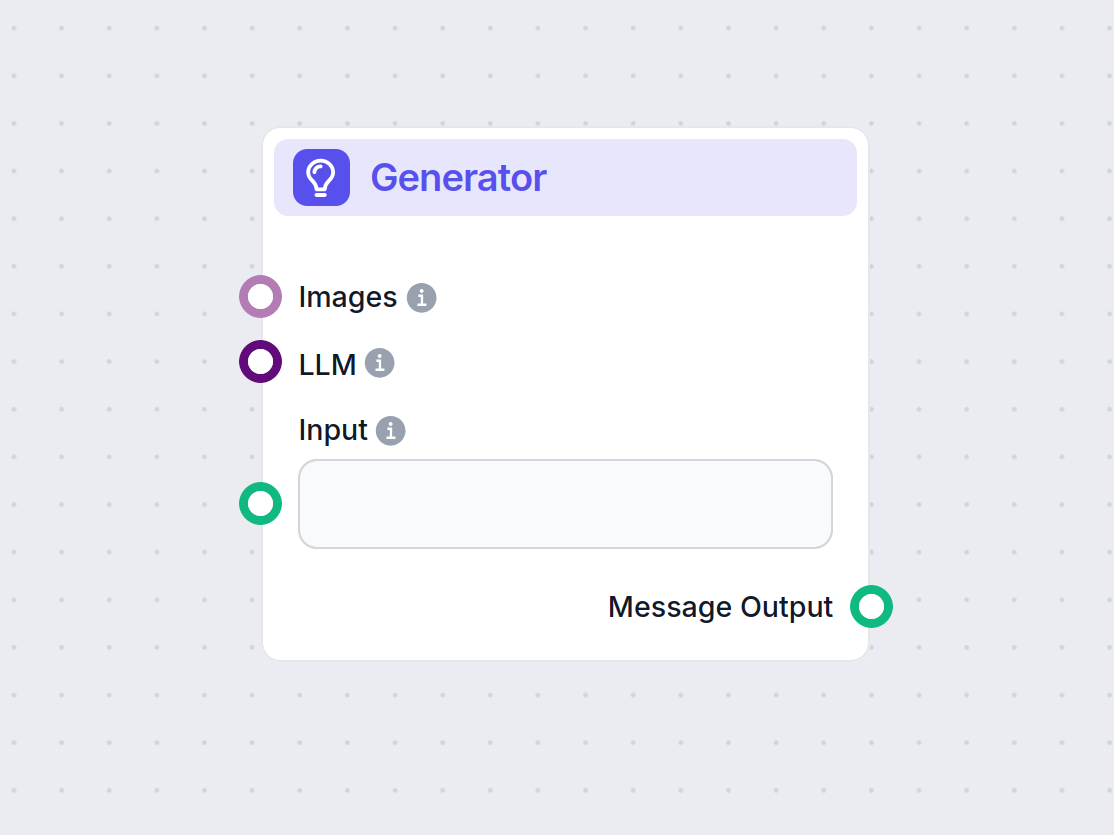
Generowanie wstępnej odpowiedzi
- Za pomocą generatora modelu językowego system tworzy roboczą odpowiedź na podstawie promptu, podkreślając miejsca, gdzie należy wstawić dane faktograficzne i wskazując źródła do weryfikacji.
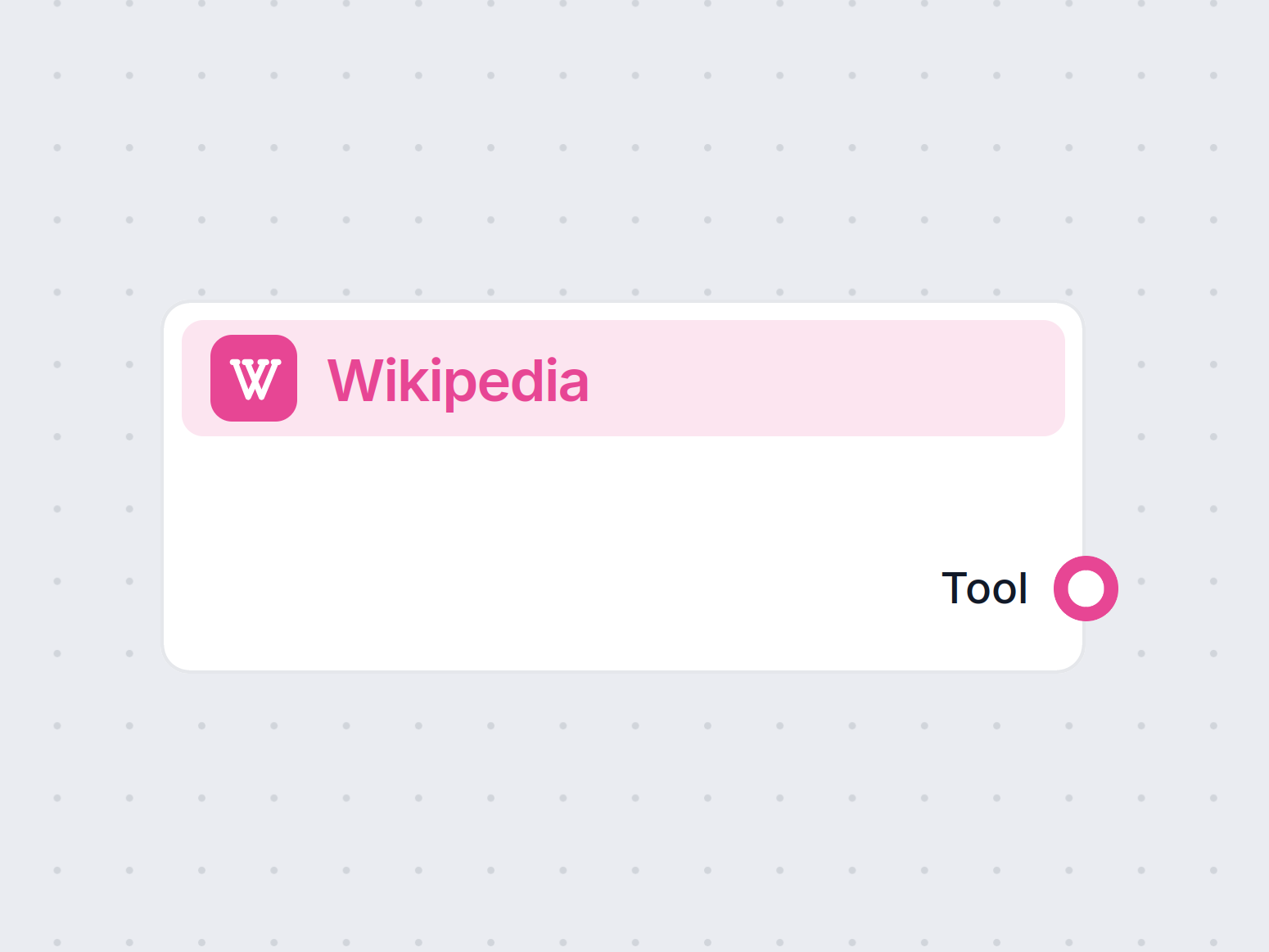
Pobieranie danych i dopracowanie odpowiedzi
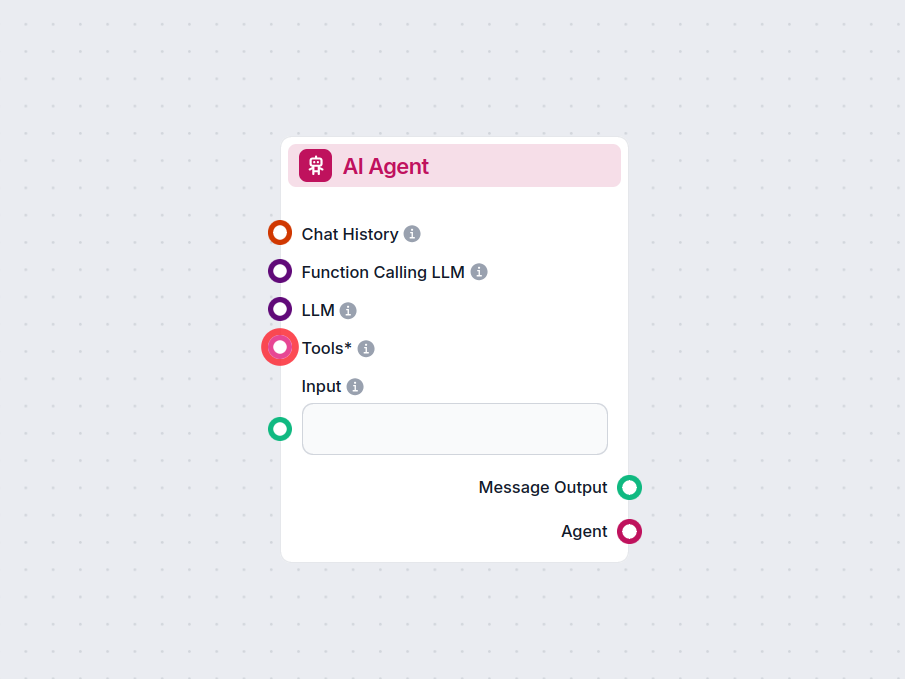
- Agent AI otrzymuje roboczą odpowiedź i korzysta z Narzędzia Wikipedia, by przeszukać Wikipedię według podanych zapytań.
- W każdej sekcji odpowiedzi agent pobiera odpowiednie dane z Wikipedii i zastępuje nimi treści robocze lub zastępcze.
- Każda sekcja jest dopracowywana poprzez dodanie bezpośredniego linku do konkretnego artykułu lub sekcji w Wikipedii, zapewniając przejrzystość i łatwą weryfikację.
Agent jest instruowany, by unikać ogólnikowych lub wypełniających fraz, skupiając się wyłącznie na zwięzłych, faktograficznych treściach.
Wynik końcowy
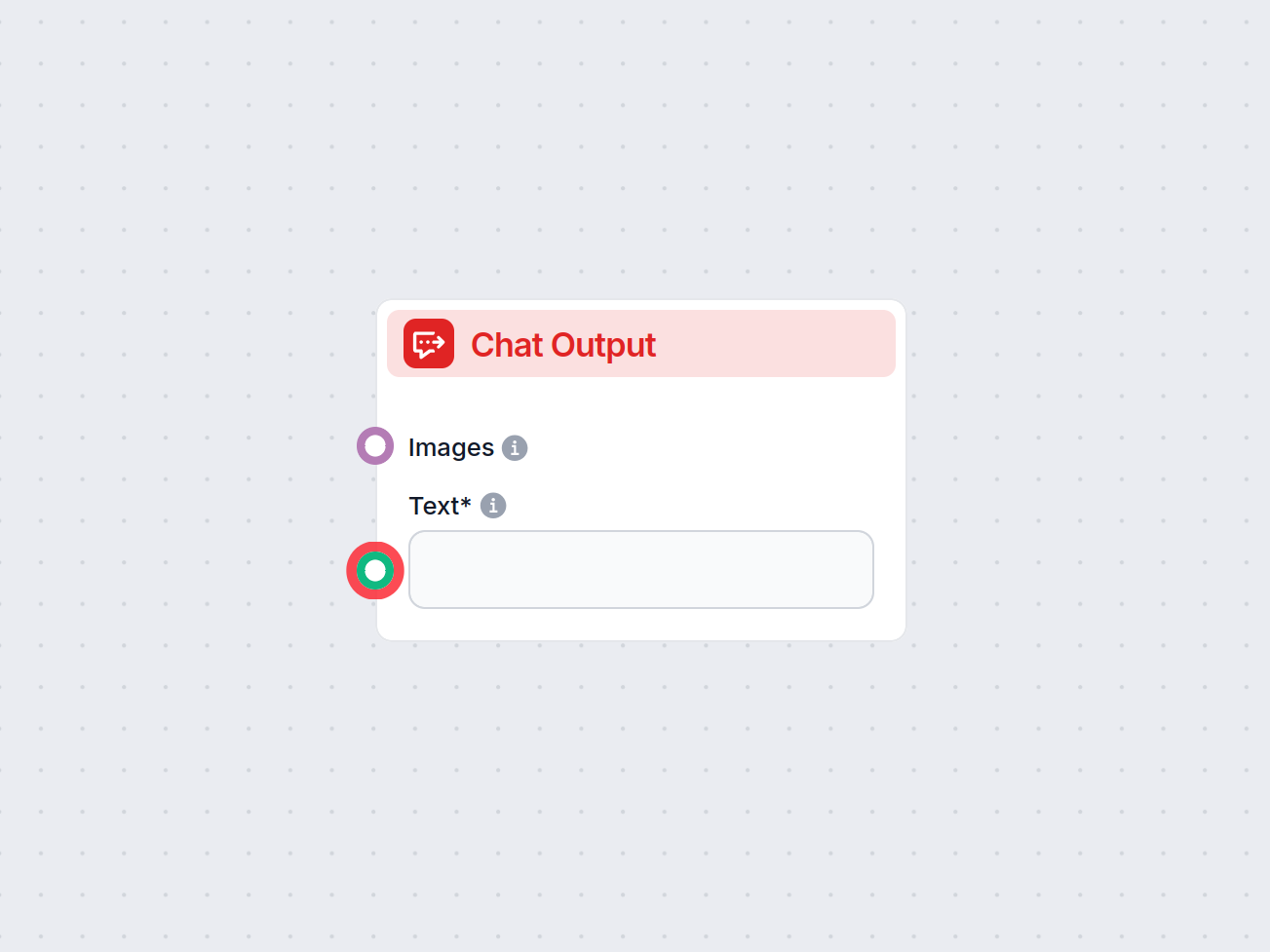
- W pełni dopracowana odpowiedź, z każdą sekcją opartą na konkretnym źródle z Wikipedii (i linkami w treści), wyświetlana jest użytkownikowi w interfejsie czatu.
Struktura przepływu pracy
| Krok | Komponent | Cel |
|---|
| 1 | Wyzwalacz otwarcia czatu | Wykrywa nową sesję czatu i wyświetla wiadomość powitalną |
| 2 | Widget wiadomości | Prezentuje wstępne powitanie i instrukcje |
| 3 | Wejście czatu | Przyjmuje pytanie użytkownika |
| 4 | Szablon Promptu | Formatuje prompt z instrukcjami dla odpowiedzi roboczej + wskazówki źródeł |
| 5 | Generator | Tworzy wstępną odpowiedź (z miejscami na dane) |
| 6 | Narzędzie Wikipedia | Umożliwia pobieranie danych z Wikipedii |
| 7 | Agent AI | Dopracowuje odpowiedź, pobiera fakty, wstawia cytaty/linki |
| 8 | Wyjście czatu | Prezentuje końcową, ugruntowaną odpowiedź użytkownikowi |
Kluczowe cechy i korzyści
- Przejrzystość źródeł: Każda sekcja odpowiedzi jasno wskazuje, z której strony lub sekcji Wikipedii pochodzi informacja, zawierając bezpośredni link do weryfikacji przez użytkownika.
- Automatyzacja i skalowalność: Przepływ pracy automatyzuje proces tworzenia, sprawdzania i dopracowywania odpowiedzi, dzięki czemu sprawdza się przy obsłudze wielu zapytań jednocześnie.
- Jakość badań: Dzięki uzasadnieniu każdej informacji zewnętrznym, weryfikowalnym źródłem, system generuje odpowiedzi odpowiednie do zastosowań naukowych, biznesowych i profesjonalnych.
- Możliwość dostosowania: W razie potrzeby można podłączyć wewnętrzne źródła wiedzy obok Wikipedii, czyniąc system elastycznym w zakresie pozyskiwania danych firmowych.
Przykładowe zastosowania
- Asystenci edukacyjni: Dostarczanie uczniom odpowiedzi zawsze opatrzonych źródłami.
- Boty do weryfikacji faktów: Natychmiastowa weryfikacja informacji i prezentacja źródeł bez ręcznego wyszukiwania.
- Obsługa klienta: Przekazywanie informacji o firmie lub produkcie z jasnym pochodzeniem danych.
- Tworzenie treści: Piszący i dziennikarze mogą otrzymać robocze treści z wbudowanymi referencjami do dalszego rozwoju.
Podsumowanie
Ten workflow umożliwia użytkownikom uzyskiwanie wiarygodnych, dobrze udokumentowanych odpowiedzi, łącząc etapy generowania i pobierania danych. Jest szczególnie przydatny wszędzie tam, gdzie kluczowe są dokładność faktograficzna, przejrzystość i wskazanie źródła. Jego modułowa, zautomatyzowana konstrukcja sprawia, że jest wysoce skalowalny dla organizacji chcących zautomatyzować zadania badawcze oraz Q&A na dużą skalę.