Dokument na tekst
Przekształć ustrukturyzowane dane w czytelny tekst markdown dzięki komponentowi Dokument na tekst FlowHunt, oferującemu konfigurowalne opcje dla wydajnych i trafnych wyników zasilanych przez AI.
Opis komponentu
Jak działa komponent Dokument na tekst
AI może analizować ogromne ilości danych w kilka sekund, ale tylko część tych danych będzie istotna lub odpowiednia do wyjścia. Komponent Dokument na tekst daje Ci kontrolę nad tym, jak dane z retrieverów są przetwarzane i przekształcane w tekst.
Komponent Dokument na tekst
Komponent Dokument na tekst został stworzony, aby przekształcać wejściowe dokumenty wiedzy w format zwykłego tekstu. Jest to szczególnie przydatne w przepływach pracy związanych z AI i przetwarzaniem danych, gdzie wymagane są dane tekstowe do dalszego przetwarzania, analizy lub jako wejście dla modeli językowych.
Co robi komponent
Ten komponent przyjmuje jeden lub więcej ustrukturyzowanych dokumentów (takich jak HTML, Markdown, PDF lub inne obsługiwane formaty) i wyodrębnia z nich treść tekstową. Pozwala precyzyjnie określić, które części dokumentów mają zostać wyeksportowane, czy uwzględnić metadane oraz jak traktować sekcje dokumentów lub nagłówki. Wynik to ujednolicony obiekt wiadomości zawierający wyodrębniony tekst, gotowy do dalszych zadań, takich jak streszczanie, klasyfikacja czy odpowiadanie na pytania.
Wejścia
Komponent akceptuje kilka konfigurowalnych parametrów wejściowych:
| Nazwa wejścia | Typ | Wymagane | Opis | Wartość domyślna |
|---|---|---|---|---|
| Dokumenty | List[Document] | Tak | Dokumenty wiedzy do przekształcenia na tekst. | N/D (podaje użytkownik) |
| Od H1 jeśli istnieje | Boolean | Tak | Rozpocznij ekstrakcję od pierwszego nagłówka H1, jeśli jest obecny. | true |
| Ładuj od wskaźnika | Boolean | Tak | Rozpocznij ekstrakcję od wskaźnika najlepiej dopasowanego do zapytania, lub ładuj wszystko, jeśli brak dopasowania. | true |
| Maksymalna liczba tokenów | Integer | Nie | Maksymalna liczba tokenów w wyjściowym tekście. | 3000 |
| Pomiń ostatni nagłówek | Boolean | Tak | Pomiń ostatni nagłówek (często stopka), by zoptymalizować wynik. | false |
| Strategia | String | Tak | Strategia ekstrakcji: łącz dokumenty lub uwzględnij równą ilość z każdego. | “Uwzględnij równą ilość z każdego dokumentu” |
| Eksportuj treść | Multi-select | Nie | Jakie typy treści uwzględnić (np. H1, H2, Akapit). | Wszystkie typy zaznaczone |
| Uwzględnij metadane | Multi-select | Nie | Pola metadanych do uwzględnienia w wyniku, jeśli dostępne. | Produkt |
Dostępne typy treści: H1, H2, H3, H4, H5, H6, Akapit
Opcje metadanych: Autor, Produkt, BreadcrumbList, VideoObject, BlogPosting, FAQPage, WebSite, opengraph
Wyjścia
Komponent generuje następujący wynik:
- Wiadomość: Obiekt wiadomości zawierający przekształcony tekst oraz ewentualne metadane.
Kluczowe cechy i zastosowania
- Elastyczna ekstrakcja treści: Precyzyjnie kontroluj, które części dokumentów chcesz wyodrębnić (np. tylko główne nagłówki i akapity lub całą zawartość).
- Uwzględnianie metadanych: Opcjonalnie dołączaj bogate metadane (np. autor, produkt lub dane strukturalne) do wyniku, co jest przydatne w dalszej kontekstualizacji.
- Zarządzanie limitem tokenów: Ogranicz rozmiar wyjściowy, by dostosować go do wymagań modeli downstream, ustawiając maksymalną liczbę tokenów.
- Własna strategia ekstrakcji:
- Łącz dokumenty, uzupełniaj od pierwszego aż do limitu tokenów: Priorytetowo dopełnia wynikowo od pierwszego dokumentu.
- Uwzględnij równą ilość z każdego dokumentu: Równoważy zawartość z wielu dokumentów w ramach limitu tokenów.
- Inteligentne zarządzanie sekcjami: Opcje pominięcia stopek dokumentu lub rozpoczęcia od najtrafniejszej sekcji względem zapytania, zwiększając trafność wyodrębnionego tekstu.
Typowe zastosowania
- Wstępne przetwarzanie baz wiedzy dla modeli AI (np. przed embeddingiem lub indeksowaniem).
- Streszczanie lub kondensacja dużych dokumentów poprzez wyodrębnienie tylko istotnych fragmentów.
- Dostarczanie ustrukturyzowanych treści do chatbotów, wyszukiwarek lub innych potoków przetwarzania języka naturalnego.
- Budowa hybrydowych systemów wyszukiwania, które łączą tekst z metadanymi dla bogatszego kontekstu.
Tabela podsumowująca
| Możliwość | Opis |
|---|---|
| Typy wejścia | Lista dokumentów |
| Typ wyjścia | Wiadomość (tekst + metadane) |
| Szczegółowość treści | Wybierz nagłówki/akapity do uwzględnienia |
| Opcje metadanych | Wybierz wiele pól metadanych do eksportu |
| Kontrola rozmiaru wyjścia | Ustaw maksymalną liczbę tokenów |
| Strategie ekstrakcji | Łączenie lub równoważenie między dokumentami |
| Wybór sekcji | Start od H1, od wskaźnika lub pominięcie ostatniego nagłówka |
Strategia
Bot może przeszukać wiele dokumentów, by stworzyć wynikowy tekst. Ustawienie Strategia pozwala kontrolować, jak inteligentnie wykorzystuje te dokumenty, mieszcząc się w limicie tokenów.
Obecnie dostępne są dwie strategie:
- Uwzględnij równą ilość z każdego dokumentu: Wykorzystuje wszystkie znalezione dokumenty równomiernie.
- Łącz dokumenty, uzupełniaj od pierwszego aż do limitu tokenów: Łączy dokumenty, priorytetyzując je według trafności względem zapytania.
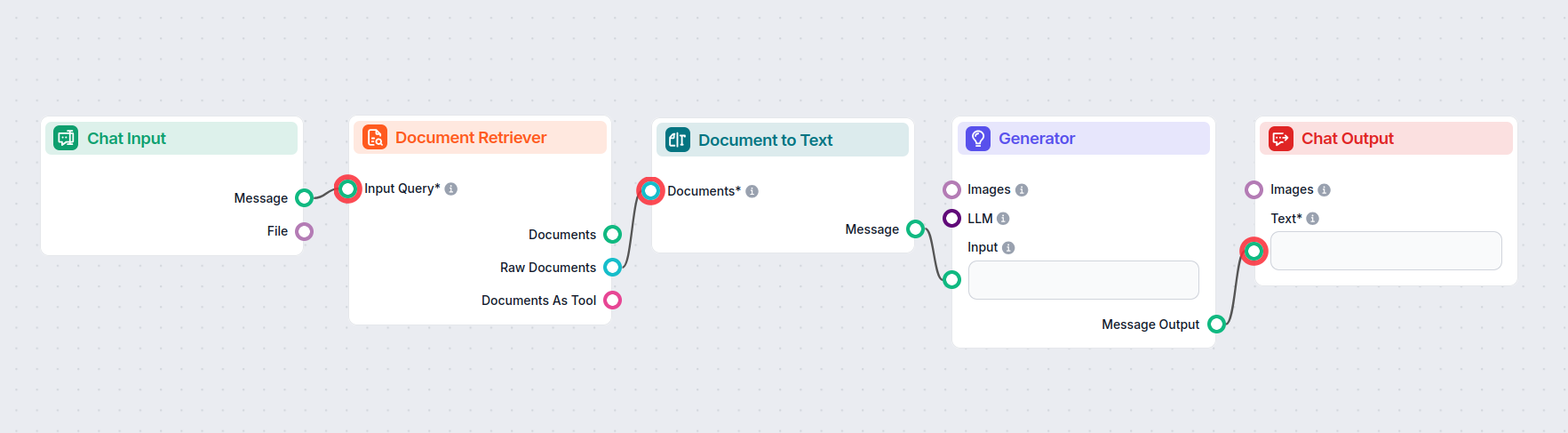
Jak podłączyć komponent Dokument na tekst do swojego flow
Jest to komponent transformujący, czyli łączy dwa wyjścia. Dokument na tekst przyjmuje dokumenty wygenerowane przez komponenty typu Retriever:
- Document Retriever – pobiera wiedzę z połączonych źródeł wiedzy (strony, dokumenty itp.).
- URL Retriever – pozwala określić URL, z którego bot powinien pobrać wiedzę.
- GoogleSearch – daje botowi możliwość wyszukiwania wiedzy w internecie.
Wiedza jest konwertowana na czytelny tekst Markdown w trakcie przechodzenia przez ten transformator. Następnie tekst ten można połączyć z komponentami wymagającymi wejścia tekstowego, takimi jak splittery, widgety czy wyjścia.
Oto przykładowy przepływ wykorzystujący komponent Dokument na tekst do połączenia Document Retrieverów z AI Generatorem:
Najczęściej zadawane pytania
- Czym jest komponent Dokument na tekst?
Komponent pobiera wiedzę z komponentów typu retriever i przekształca ją w czytelny tekst markdown, który można następnie połączyć z dowolnym komponentem przyjmującym tekst jako wejście.
Wypróbuj Dokument na tekst w FlowHunt
Zacznij budować inteligentniejsze rozwiązania AI z komponentem Dokument na tekst FlowHunt. Bezproblemowo przekształcaj dane w użyteczny tekst i usprawniaj swoje zautomatyzowane procesy.
Dowiedz się więcej