
LLM Mistral
LLM Mistral na FlowHunt umożliwia elastyczną integrację zaawansowanych modeli Mistral AI do płynnego generowania tekstu w chatbotach i narzędziach AI.
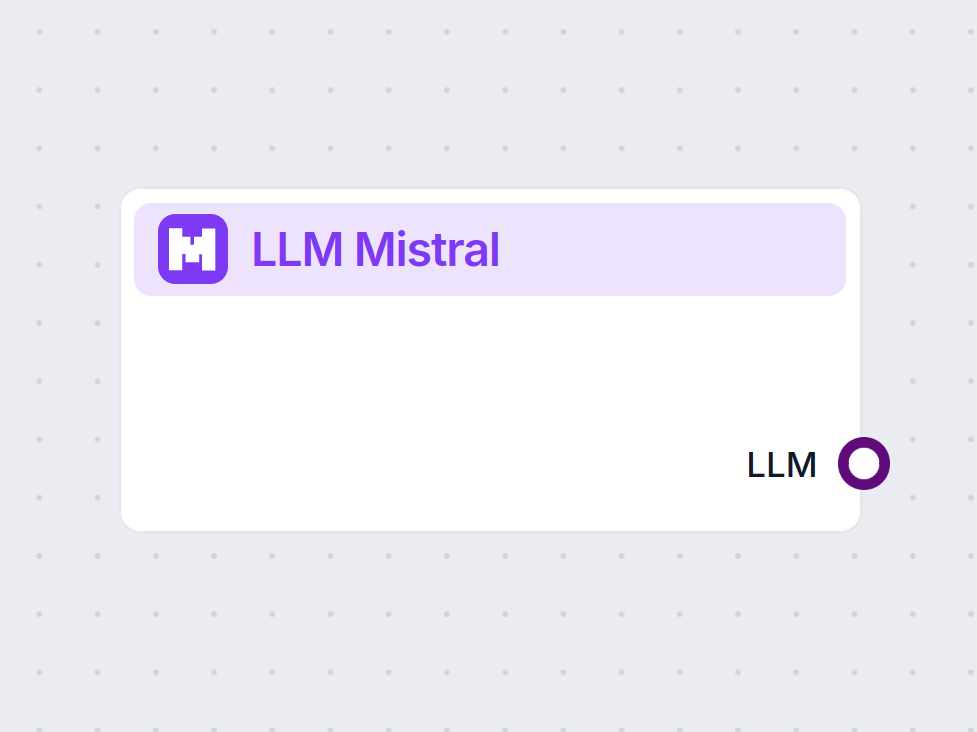
Opis komponentu
Jak działa komponent LLM Mistral
Czym jest komponent LLM Mistral?
Komponent LLM Mistral łączy modele Mistral z Twoim przepływem. Chociaż generatory i agenci to miejsca, gdzie dzieje się właściwa magia, komponenty LLM pozwalają Ci kontrolować używany model. Wszystkie komponenty domyślnie korzystają z ChatGPT-4. Możesz podłączyć ten komponent, jeśli chcesz zmienić model lub uzyskać nad nim większą kontrolę.
Pamiętaj, że podłączenie komponentu LLM jest opcjonalne. Wszystkie komponenty korzystające z LLM mają domyślnie ChatGPT-4o. Komponenty LLM pozwalają zmienić model oraz kontrolować ustawienia modelu.
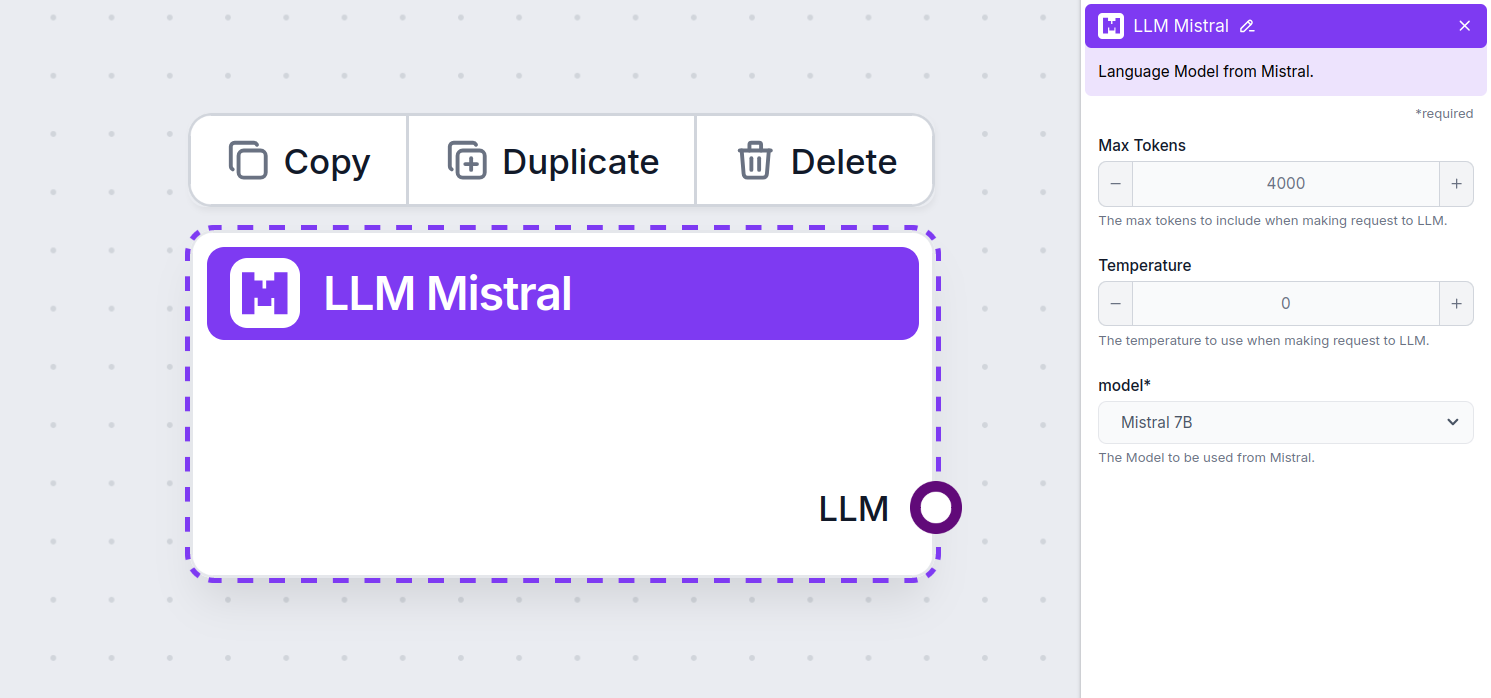
Ustawienia komponentu LLM Mistral
Maksymalna liczba tokenów
Tokeny to pojedyncze jednostki tekstu, które model przetwarza i generuje. Zużycie tokenów różni się w zależności od modelu, a pojedynczy token może być słowem, pod-słowem lub pojedynczym znakiem. Modele są zwykle rozliczane w milionach tokenów.
Ustawienie maksymalnej liczby tokenów ogranicza całkowitą liczbę tokenów, które mogą być przetworzone podczas jednej interakcji lub żądania, zapewniając, że odpowiedzi mieszczą się w rozsądnych granicach. Domyślny limit to 4000 tokenów, co jest optymalnym rozmiarem do podsumowywania dokumentów i wielu źródeł w celu wygenerowania odpowiedzi.
Temperatura
Temperatura kontroluje zmienność odpowiedzi, mieszcząc się w zakresie od 0 do 1.
Temperatura 0,1 sprawia, że odpowiedzi będą bardzo konkretne, ale mogą być powtarzalne i ubogie.
Wysoka temperatura równa 1 pozwala na maksymalną kreatywność odpowiedzi, ale wiąże się z ryzykiem nieistotnych lub nawet halucynacyjnych treści.
Na przykład zalecana temperatura dla chatbota obsługi klienta to od 0,2 do 0,5. Ten poziom pozwala utrzymać odpowiedzi na temat i zgodne ze skryptem, a jednocześnie umożliwia pewną naturalną zmienność.
Model
To selektor modelu. Znajdziesz tu wszystkie obsługiwane modele Mistral. Obecnie obsługujemy następujące modele:
- Mistral 7B – Model językowy o 7,3 miliardach parametrów, wykorzystujący architekturę transformerów, wydany na licencji Apache 2.0. Mimo mniejszego rozmiaru często przewyższa model Llama 2 od Meta. Sprawdź, jak poradził sobie w naszych testach.
- Mistral 8x7B (Mixtral) – Model oparty na architekturze rzadkiej mieszanki ekspertów, obejmujący osiem grup „ekspertów”, łącznie 46,7 miliarda parametrów. Każdy token korzysta z maksymalnie 12,9 miliarda parametrów, oferując wydajność na poziomie lub przewyższającym LLaMA 2 70B i GPT-3.5 w większości benchmarków. Zobacz przykłady wyników.
- Mistral Large – Wysokowydajny model językowy mający 123 miliardy parametrów i długość kontekstu 128 000 tokenów. Biegle obsługuje wiele języków, w tym języki programowania, i pokazuje konkurencyjną wydajność względem modeli takich jak LLaMA 3.1 405B, szczególnie w zadaniach związanych z programowaniem. Dowiedz się więcej tutaj.
Jak dodać LLM Mistral do swojego przepływu
Zauważysz, że wszystkie komponenty LLM mają tylko uchwyt wyjściowy. Wejście nie przechodzi przez komponent, ponieważ reprezentuje on wyłącznie model, a właściwe generowanie odbywa się w AI Agentach i Generatorach.
Uchwyt LLM jest zawsze fioletowy. Uchwyt wejściowy LLM znajduje się w każdym komponencie, który wykorzystuje AI do generowania tekstu lub przetwarzania danych. Opcje zobaczysz po kliknięciu uchwytu:
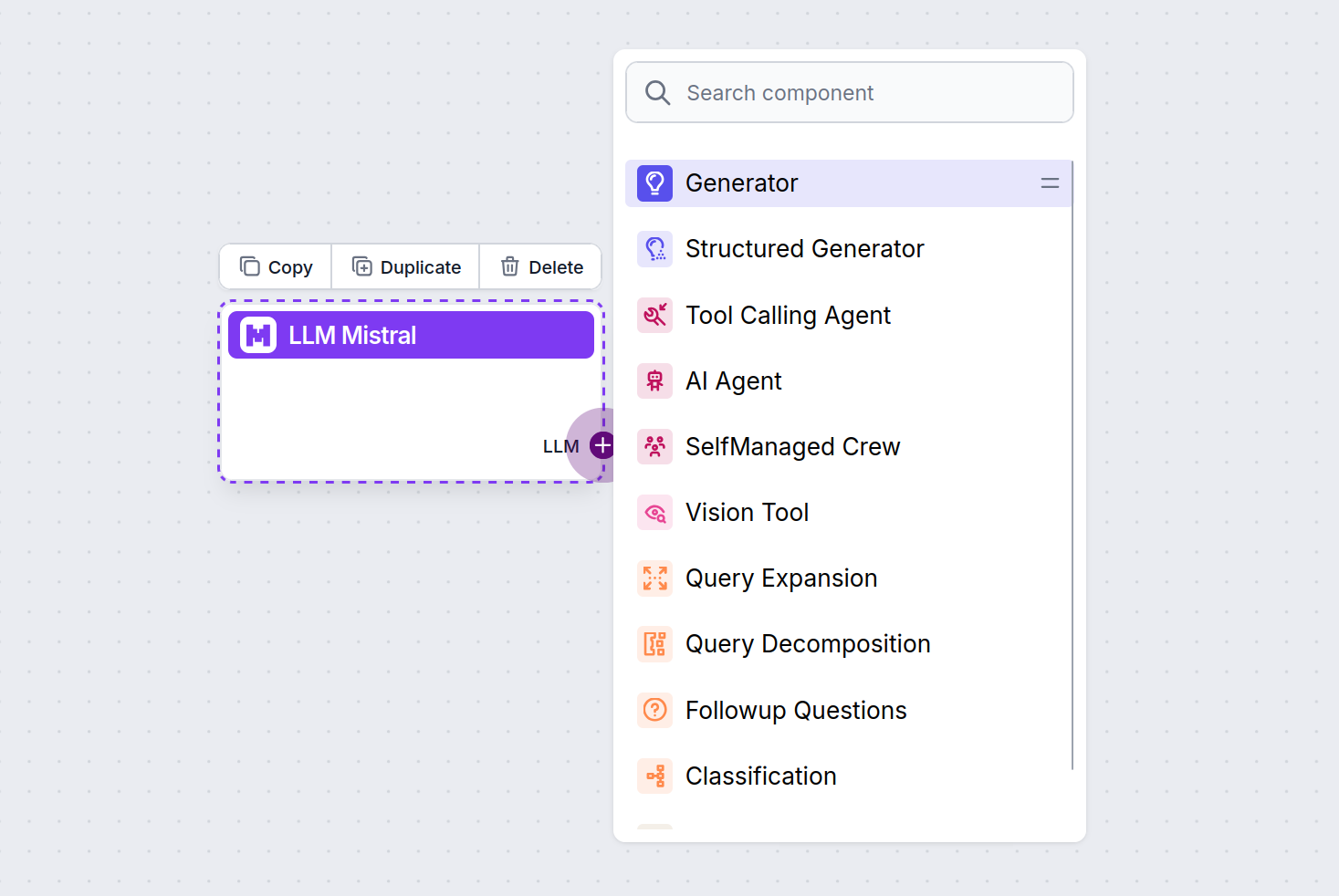
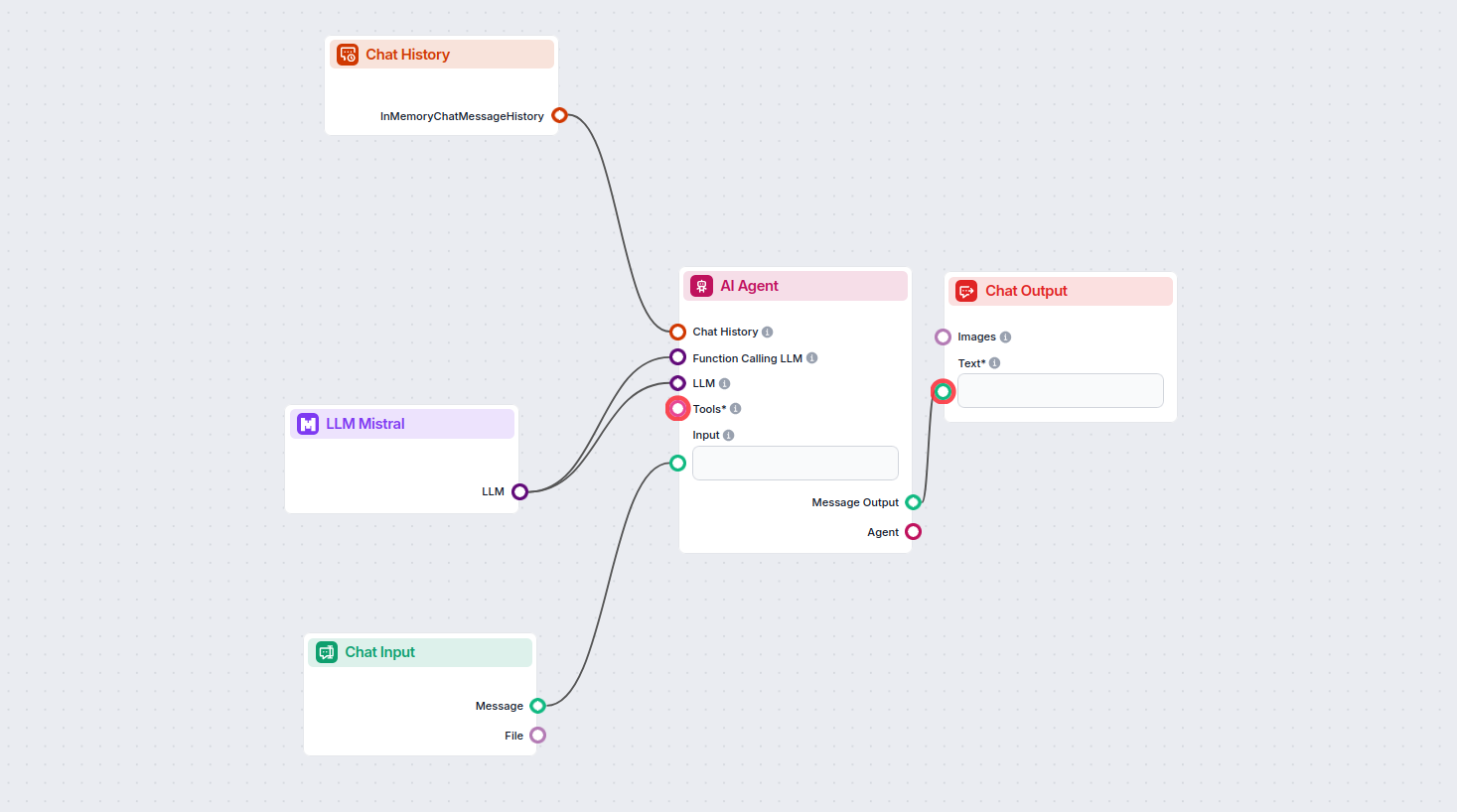
Pozwala to tworzyć dowolne narzędzia. Zobaczmy komponent w praktyce. Oto przykładowy przepływ chatbota AI Agenta, który korzysta z modelu Mistral 7B do generowania odpowiedzi. Możesz potraktować to jako podstawowego chatbota Mistral.
Ten prosty przepływ Chatbota obejmuje:
- Wejście czatu: Reprezentuje wiadomość wysyłaną przez użytkownika na czacie.
- Historia czatu: Pozwala chatbotowi zapamiętać i uwzględnić poprzednie odpowiedzi.
- Wyjście czatu: Reprezentuje ostateczną odpowiedź chatbota.
- AI Agent: Autonomiczny agent AI generujący odpowiedzi.
- LLM Mistral: Połączenie z modelami generowania tekstu Mistral.
Najczęściej zadawane pytania
- Czym jest komponent LLM Mistral w FlowHunt?
Komponent LLM Mistral pozwala połączyć modele Mistral AI z Twoimi projektami FlowHunt, umożliwiając zaawansowane generowanie tekstu dla Twoich chatbotów i agentów AI. Pozwala na zmianę modeli, kontrolę ustawień oraz integrację modeli takich jak Mistral 7B, Mixtral (8x7B) i Mistral Large.
- Jakie modele Mistral są obsługiwane przez FlowHunt?
FlowHunt obsługuje Mistral 7B, Mixtral (8x7B) oraz Mistral Large, z których każdy oferuje różne poziomy wydajności i parametryzacji do różnych potrzeb generowania tekstu.
- Jakie ustawienia mogę dostosować w komponencie LLM Mistral?
Możesz dostosować ustawienia takie jak maksymalna liczba tokenów i temperatura oraz wybrać spośród obsługiwanych modeli Mistral, aby kontrolować długość odpowiedzi, kreatywność i zachowanie modelu w swoich przepływach.
- Czy połączenie komponentu LLM Mistral jest wymagane w każdym projekcie?
Nie, podłączenie komponentu LLM jest opcjonalne. Domyślnie komponenty FlowHunt korzystają z ChatGPT-4o. Użyj komponentu LLM Mistral, jeśli chcesz mieć większą kontrolę lub użyć konkretnego modelu Mistral.
Wypróbuj LLM Mistral w FlowHunt już dziś
Zacznij budować inteligentniejsze chatboty i narzędzia AI, integrując potężne modele językowe Mistral z platformą FlowHunt bez kodowania.
Dowiedz się więcej

