Pobieracz URL
Pobieracz URL pozwala pobierać i przetwarzać treści z linków internetowych, obsługując OCR, wyodrębnianie metadanych oraz elastyczny format wyjściowy do zasilania przepływów AI.
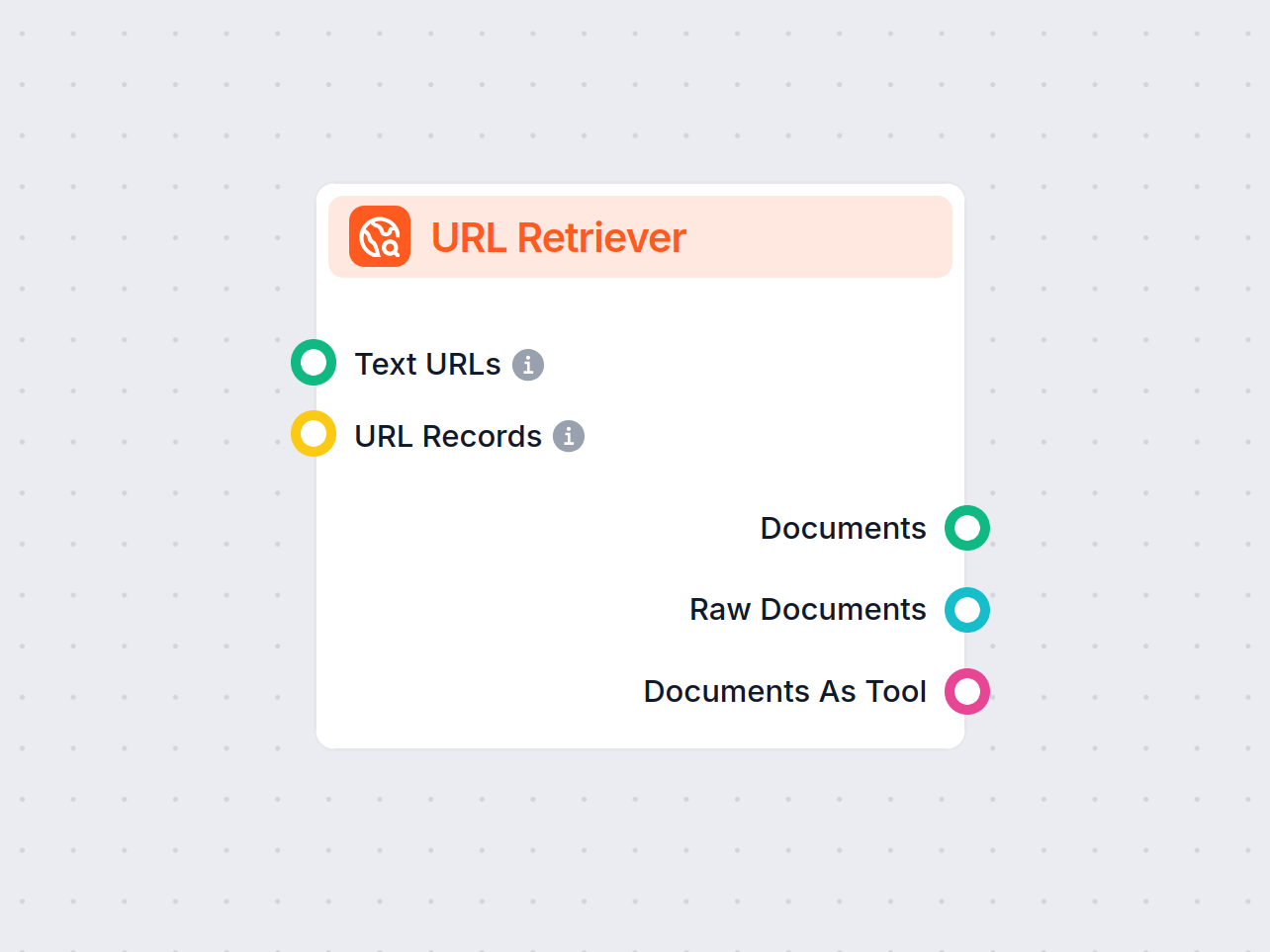
Opis komponentu
Jak działa komponent Pobieracz URL
Komponent Pobieracz URL
Pobieracz URL to wszechstronny komponent przepływu pracy zaprojektowany do pobierania i przetwarzania treści internetowych ze wskazanych adresów URL, zwracając informacje jako uporządkowane dokumenty. Stanowi most między zewnętrznymi treściami online a Twoim przepływem AI, umożliwiając integrację, analizę lub przetwarzanie informacji z internetu w wydajny sposób.
Co robi ten komponent?
Ten komponent pobiera treść jednego lub wielu adresów URL podanych jako wejście. Może wyodrębnić główny tekst, metadane, a nawet przetworzyć zawartość obrazów za pomocą optycznego rozpoznawania znaków (OCR). Pobrane dane są następnie udostępniane w różnych uporządkowanych formatach, odpowiednich do dalszych zadań AI takich jak podsumowanie, odpowiadanie na pytania czy wydobywanie wiedzy.
Opcje wejściowe
Adresy URL można przekazać do komponentu na dwa sposoby:
Adresy URL w tekście:
- Typ wejścia:
Message - Opis: Lista zwykłych linków URL, z których komponent pobierze treści.
- Typ wejścia:
Rekordy URL:
- Typ wejścia:
UrlRecord - Opis: Lista uporządkowanych rekordów URL, które mogą zawierać dodatkowe metadane.
- Typ wejścia:
Zaawansowane parametry wejściowe
| Parametr | Typ | Domyślnie | Opis |
|---|---|---|---|
| Zastosuj OCR | Boolean | false | Jeśli włączone, stosuje OCR do wyodrębnienia tekstu z obrazów w dokumencie. |
| Cache TTL | Dropdown | 2 tygodnie | Jak długo treść ma być buforowana; opcje od braku buforowania do 1 roku. |
| Od H1 jeśli istnieje | Boolean | true | Rozpoczyna wydobywanie od tagu H1, jeśli jest obecny, skupiając się na głównej treści. |
| Ładuj z wskaźnika | Boolean | true | Ładuje treść zaczynając od najbardziej istotnej sekcji na podstawie zapytania. |
| Ukryj zasoby | Boolean | false | Ukrywa pobrane zasoby, aby nie były wyświetlane ani eksportowane. |
| Maks. liczba tokenów | Integer | 3000 | Ustala maksymalną liczbę tokenów dla tekstu wyjściowego. |
| Pomiń ostatni nagłówek | Boolean | true | Pomija ostatni nagłówek podczas wydobywania dla usprawnienia treści. |
| Strategia | Dropdown | Uwzględnij równą ilość z każdego dokumentu | Określa sposób łączenia treści: pełna konkatenacja lub równe części z każdego dokumentu. |
| Eksportuj treść | Multi-select | Wszystko | Wybierz, które elementy HTML eksportować (H1-H6, Akapit). |
| Uwzględnij metadane | Multi-select | Produkt | Określ, które pola metadanych uwzględnić (np. Produkt, Autor, Strona internetowa itd.). |
| Tryb szczegółowy | Boolean | false | Włącza szczegółowe dane wyjściowe do celów debugowania lub informacyjnych. |
| Nazwa narzędzia | String | (puste) | Opcjonalnie przypisz niestandardową nazwę narzędzia do wykorzystania przez agentów. |
| Opis narzędzia | Multiline | (puste) | Podaj opis, który pomoże agentom zrozumieć cel narzędzia. |
Wyjścia
Pobieracz URL udostępnia swoje wyniki w kilku formatach, umożliwiając elastyczną integrację z różnymi procesami AI:
| Nazwa wyjścia | Typ | Opis |
|---|---|---|
| Dokumenty | Message | Przetworzone treści z adresów URL, gotowe do użycia w przepływach opartych o wiadomości. |
| Surowe dokumenty | Document | Surowe, nieprzetworzone obiekty dokumentów do zaawansowanego dalszego przetwarzania. |
| Dokumenty jako narzędzie | Tool | Treść zapakowana jako narzędzie, umożliwiająca agentom wykorzystywanie dokumentów. |
Dlaczego warto używać Pobieracza URL?
- Integracja zewnętrznej wiedzy: Bezproblemowo przenoś informacje z internetu do swoich aplikacji AI, takich jak chatboty, wyszukiwarki czy bazy wiedzy.
- Dostosowywanie wydobycia: Precyzyjnie wybierz, jakie treści i metadane chcesz pobrać, kontroluj ilość danych i używaj OCR dla obrazów.
- Wydajność i efektywność: Używaj buforowania, by uniknąć zbędnych pobrań, oraz ogranicz wyjście do określonej liczby tokenów dla lepszej wydajności.
- Elastyczne formaty wyjściowe: Wybierz format wyjściowy, który najlepiej pasuje do kolejnego kroku — uporządkowany dokument, wiadomość lub narzędzie.
Przykładowe zastosowania
- Tworzenie konwersacyjnych agentów wiedzy odpowiadających na pytania na podstawie aktualnych treści z internetu.
- Agregowanie danych o produktach ze sklepów internetowych do porównań lub analiz.
- Monitorowanie i analiza blogów lub artykułów prasowych według określonych tematów lub słów kluczowych.
- Wyodrębnianie informacji ze stron internetowych zawierających mieszane media (tekst i obrazy).
Tabela podsumowująca
| Funkcja | Opis |
|---|---|
| Pobiera adresy URL | Pobiera i przetwarza treści internetowe z podanych adresów URL. |
| Obsługa OCR | Wyodrębnia tekst z obrazów w dokumentach, jeśli opcja jest włączona. |
| Wydobywanie metadanych | Opcjonalnie uwzględnia metadane, takie jak autor, produkt czy typy schema.org. |
| Dostosowywanie wyjścia | Wybierz, które elementy HTML lub metadane eksportować. |
| Buforowanie | Konfigurowalny czas buforowania dla większej efektywności. |
| Wiele typów wyjścia | Obsługuje wiadomości, surowe dokumenty oraz narzędzia dla elastyczności przepływu. |
Pobieracz URL to potężny i elastyczny most między treściami internetowymi a Twoimi przepływami AI, oferujący szczegółową kontrolę nad wydobywaniem i integracją informacji.
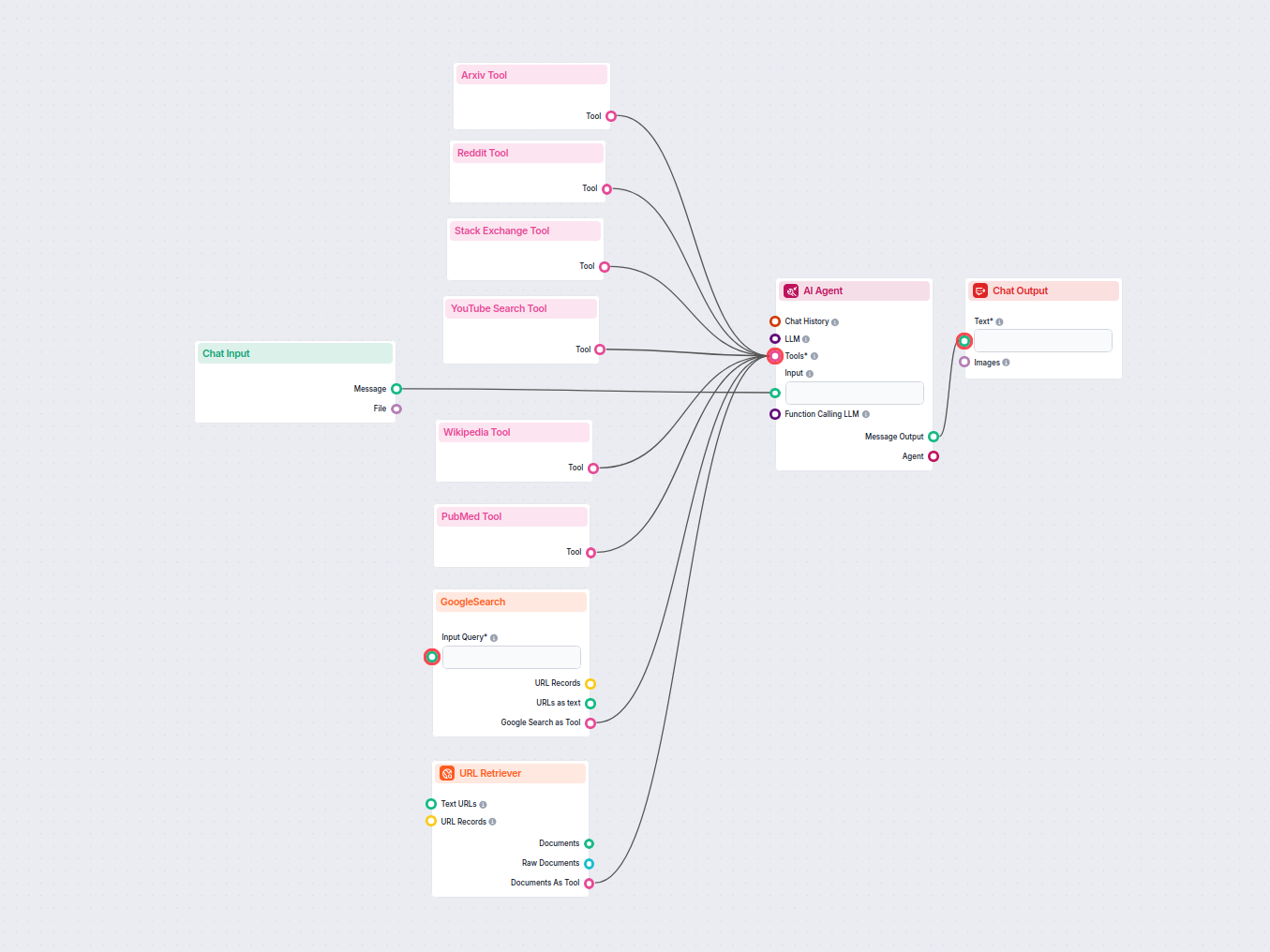
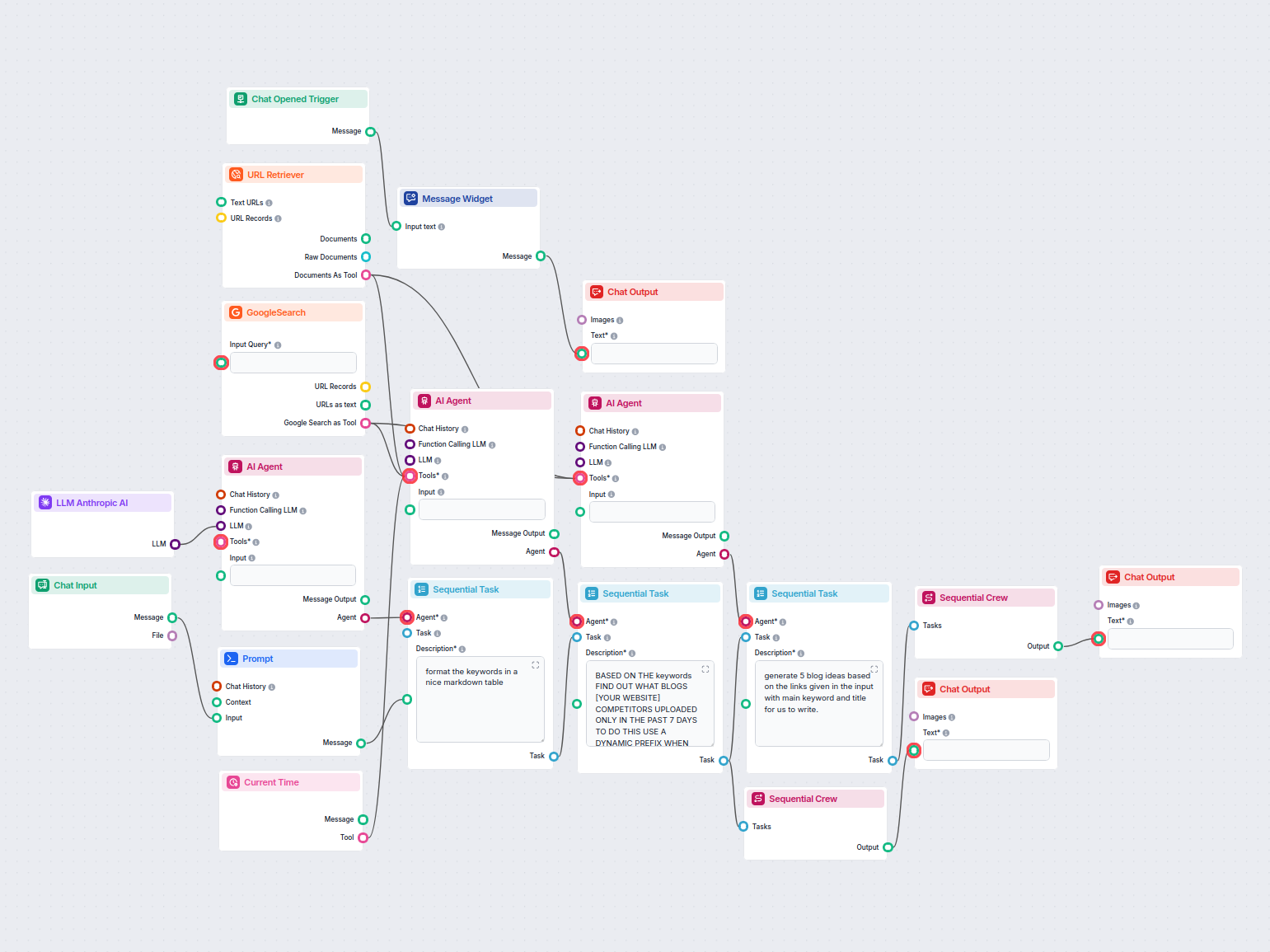
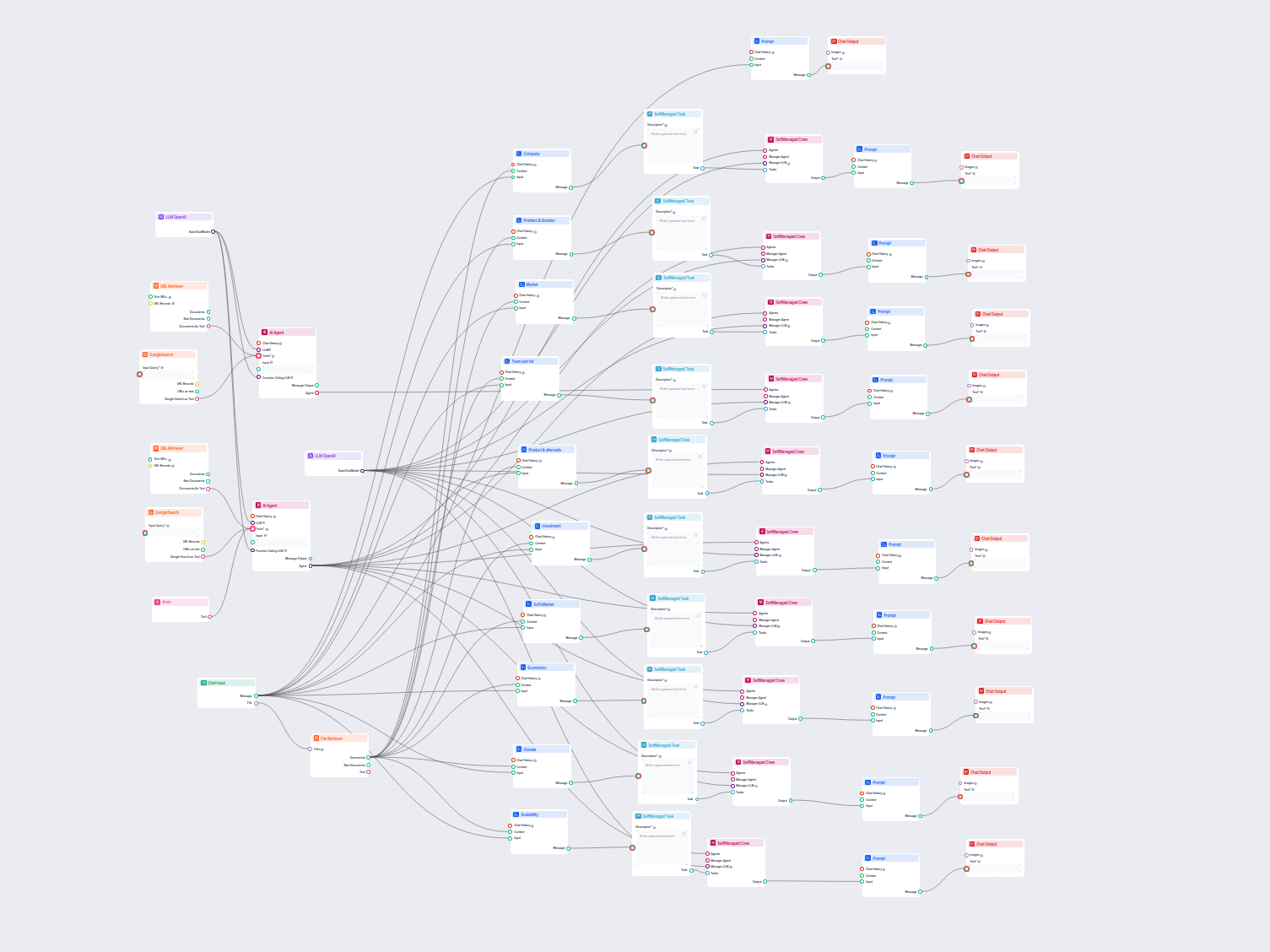
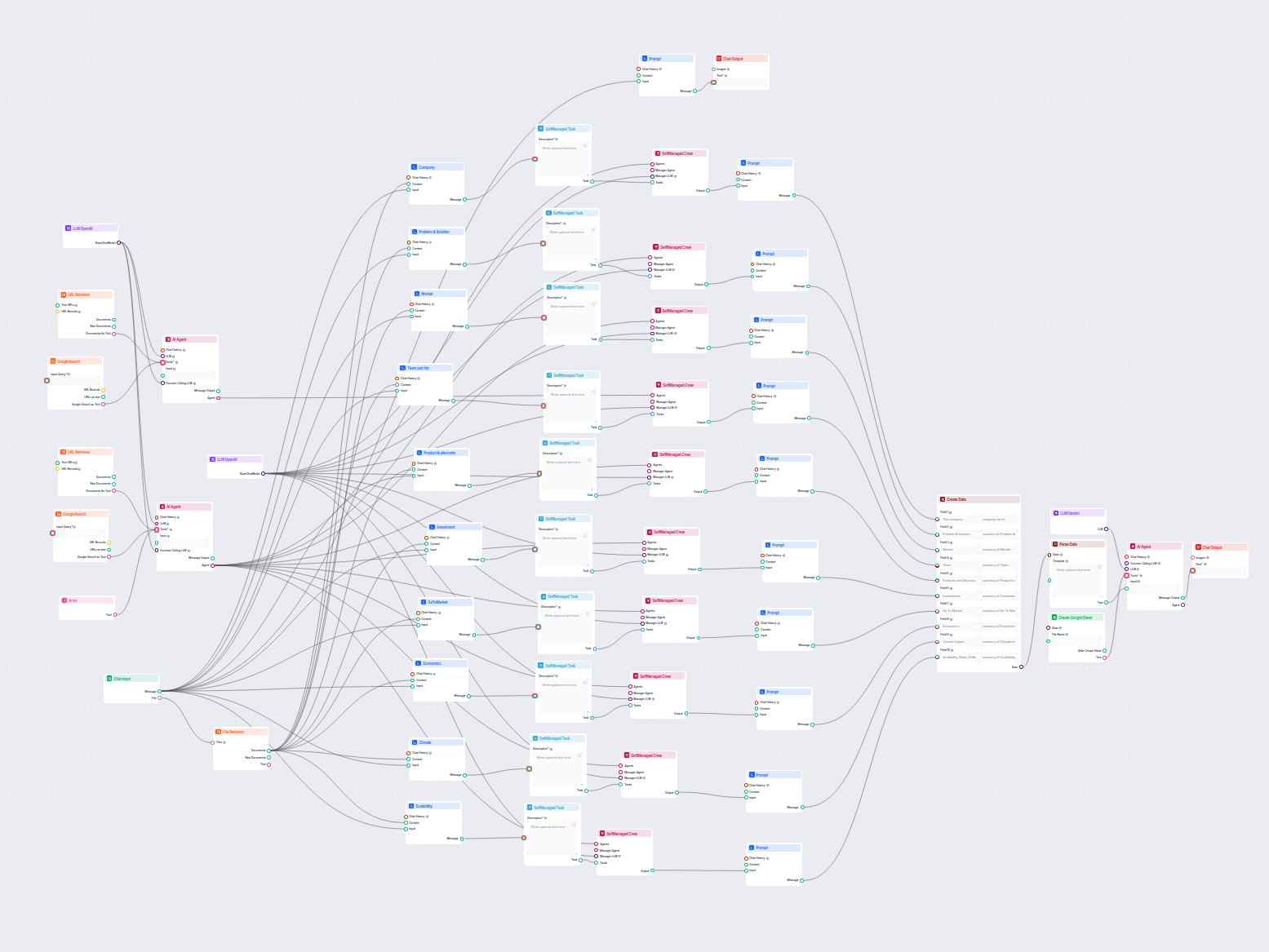
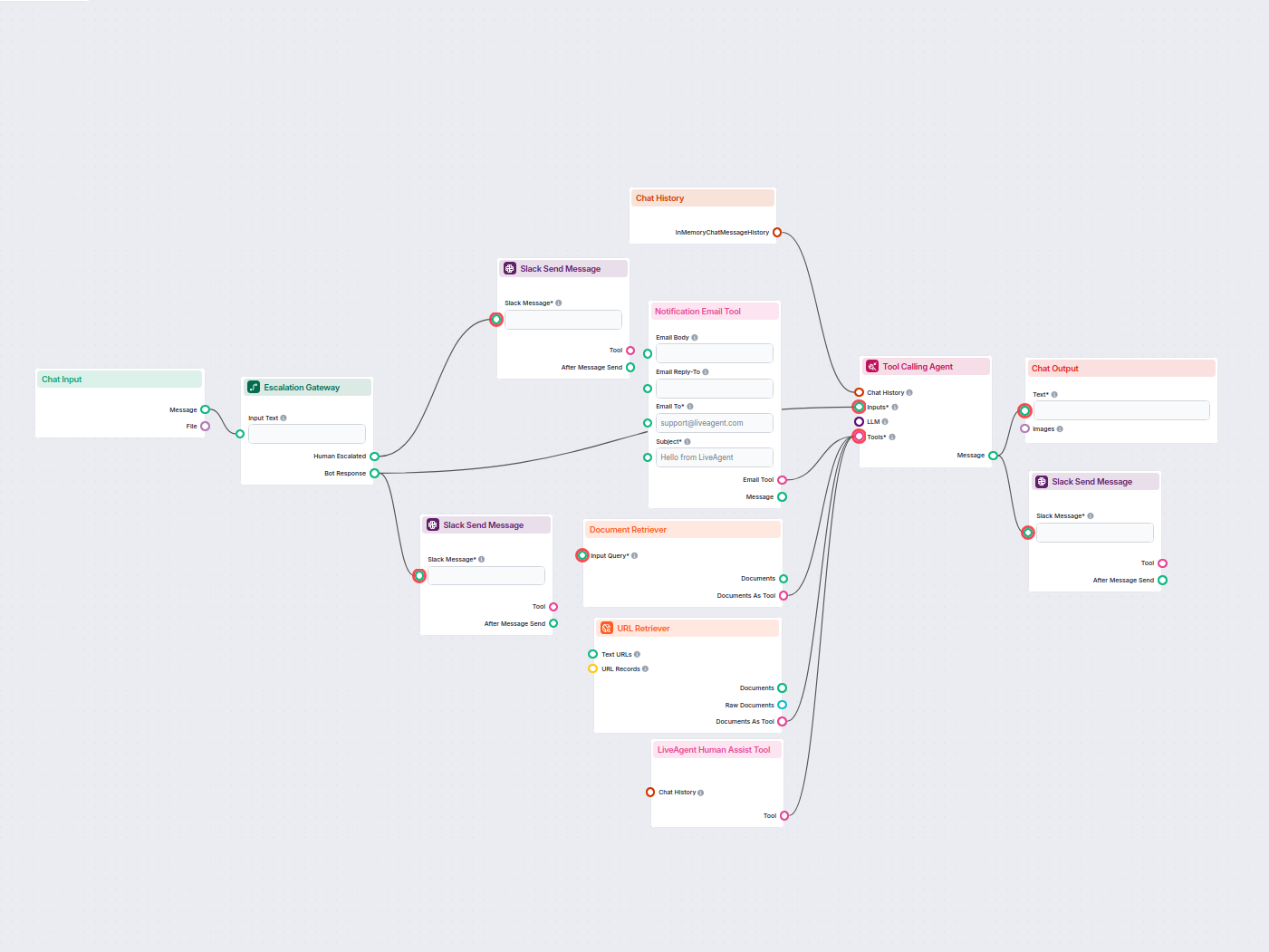
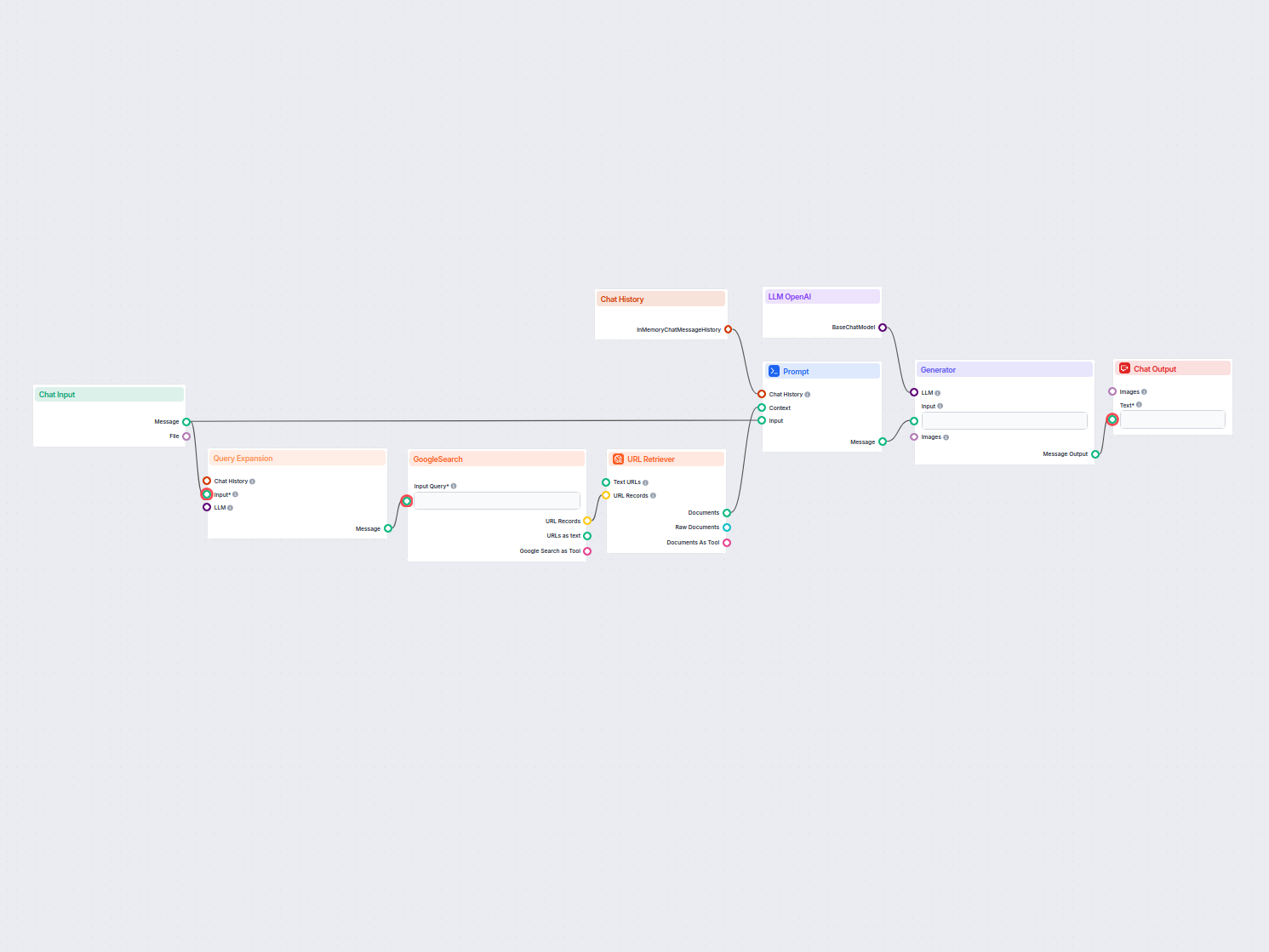
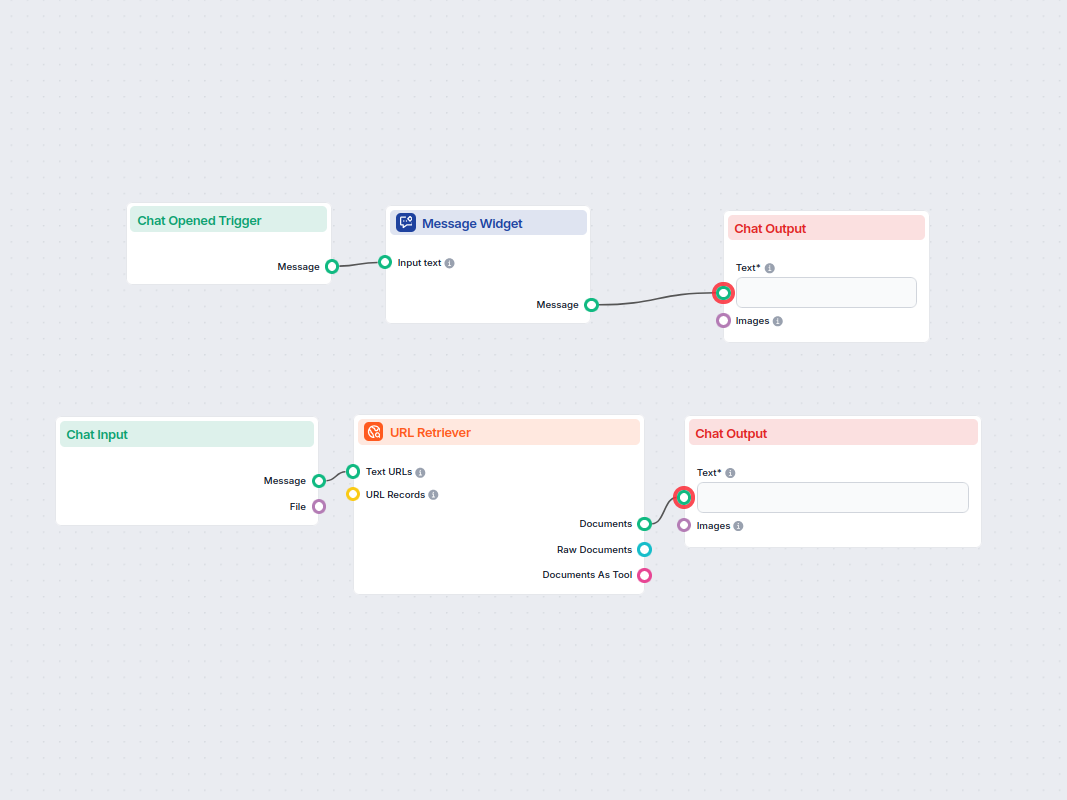
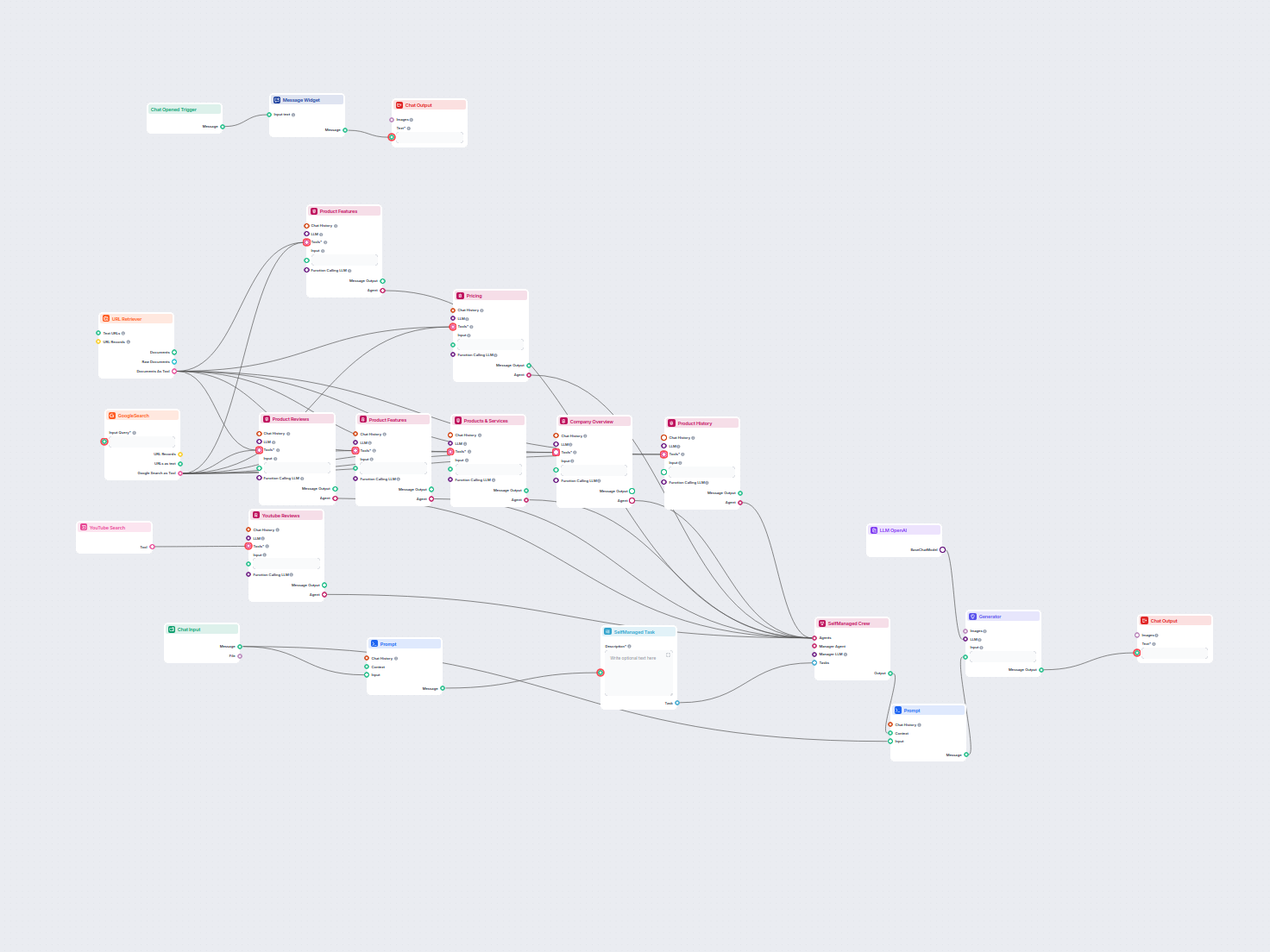
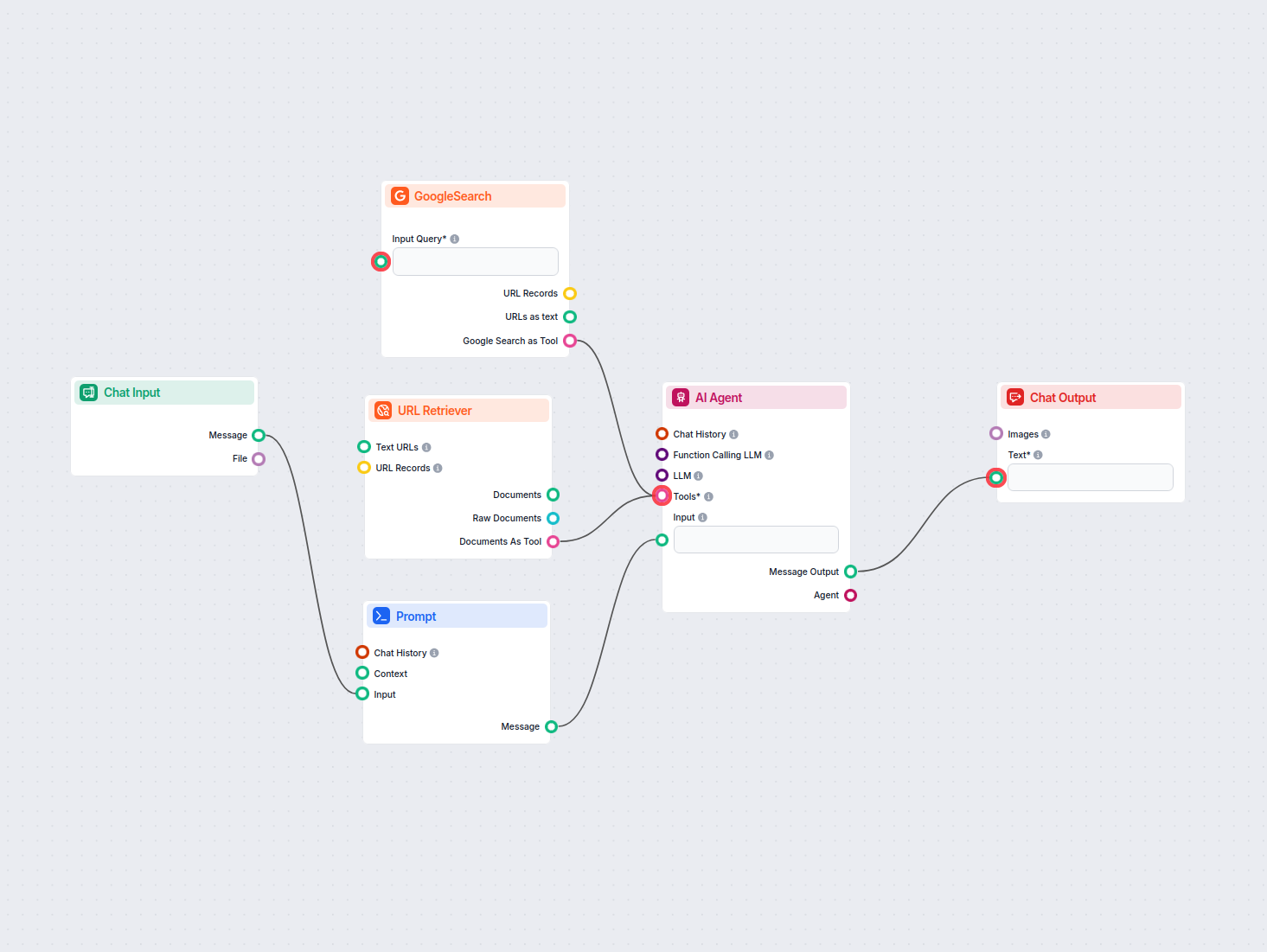
Przykłady szablonów przepływu wykorzystujących komponent Pobieracz URL
Aby pomóc Ci szybko zacząć, przygotowaliśmy kilka przykładowych szablonów przepływu, które pokazują, jak efektywnie używać komponentu Pobieracz URL. Te szablony prezentują różne przypadki użycia i najlepsze praktyki, ułatwiając zrozumienie i implementację komponentu w Twoich własnych projektach.


















































Najczęściej zadawane pytania
- Do czego służy komponent Pobieracz URL?
Pobieracz URL pobiera i przetwarza treści ze wskazanych linków internetowych, udostępniając tekst i metadane z dokumentów online w Twoim przepływie pracy lub agentowi AI.
- Czy może wyodrębniać treści z obrazów lub plików PDF?
Tak, po włączeniu opcji OCR komponent może wyodrębniać tekst z dokumentów obrazowych lub zeskanowanych plików PDF.
- Jakie rodzaje danych wyjściowych oferuje?
Zwraca przetworzone dokumenty jako wiadomości tekstowe, surowe obiekty dokumentów lub jako narzędzie do przepływów agentów — w zależności od konfiguracji.
- Jak działa buforowanie w Pobieraczu URL?
Możesz ustawić, jak długo pobrane treści mają być buforowane, co ogranicza powtarzające się pobieranie i przyspiesza działanie przepływów pracy.
- Czy mogę kontrolować, które części strony internetowej są wyodrębniane?
Tak, możesz określić, które nagłówki, akapity lub pola metadanych mają być zawarte w wyjściu, co pozwala na selektywne wydobywanie.
- Czy nadaje się do budowy botów wiedzy lub automatyzacji danych z internetu?
Zdecydowanie. Pobieracz URL jest niezbędny do każdej automatyzacji lub chatbota, który musi czytać, przetwarzać lub podsumowywać aktualne treści z internetu.
Wypróbuj FlowHunt Pobieracz URL
Zwiększ możliwości swoich przepływów pracy, integrując aktualne treści z internetu. Wyodrębniaj, przetwarzaj i wykorzystuj dane z adresów URL z łatwością.
Dowiedz się więcej