Kubeflow
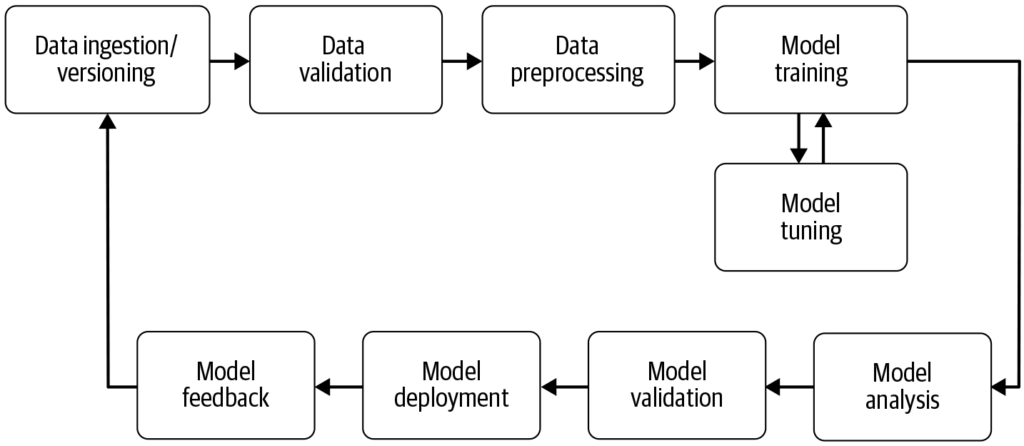
Kubeflow to otwarta platforma ML zbudowana na Kubernetes, która usprawnia wdrażanie, zarządzanie i skalowanie przepływów pracy uczenia maszynowego w różnych infrastrukturach.
Misją Kubeflow jest maksymalne uproszczenie skalowania modeli ML i ich wdrażania do produkcji poprzez wykorzystanie możliwości Kubernetes. Obejmuje to łatwe, powtarzalne i przenośne wdrożenia w różnych infrastrukturach. Platforma zaczęła jako metoda uruchamiania zadań TensorFlow na Kubernetes, a dziś jest wszechstronnym frameworkiem obsługującym szeroki zakres narzędzi i frameworków ML.
Kluczowe pojęcia i komponenty Kubeflow
1. Kubeflow Pipelines
Kubeflow Pipelines to podstawowy komponent pozwalający użytkownikom definiować i wykonywać przepływy pracy ML jako skierowane grafy acykliczne (DAG). Zapewnia platformę do budowania przenośnych i skalowalnych przepływów pracy ML na Kubernetes. Komponent Pipelines obejmuje:
- Interfejs użytkownika (UI): Webowy interfejs do zarządzania i śledzenia eksperymentów, zadań i uruchomień.
- SDK: Zestaw pakietów Pythona do definiowania i manipulowania pipeline’ami oraz komponentami.
- Silnik orkiestracji: Planuje i zarządza wieloetapowymi przepływami pracy ML.
Te funkcje umożliwiają automatyzację całego procesu — od przygotowania danych, przez trenowanie modelu i jego ewaluację, po wdrożenie — co sprzyja powtarzalności i współpracy w projektach ML. Platforma wspiera ponowne wykorzystanie komponentów i pipeline’ów, usprawniając tworzenie rozwiązań ML.
2. Centralny dashboard
Centralny dashboard Kubeflow jest głównym interfejsem do dostępu do Kubeflow i jego ekosystemu. Agreguje interfejsy użytkownika różnych narzędzi i usług w klastrze, zapewniając jednolity punkt dostępu do zarządzania aktywnościami ML. Dashboard oferuje takie funkcje jak uwierzytelnianie użytkowników, izolacja wielu użytkowników i zarządzanie zasobami.
3. Jupyter Notebooks
Kubeflow integruje się z Jupyter Notebooks, oferując interaktywne środowisko do eksploracji danych, eksperymentowania i rozwoju modeli. Notebooki obsługują różne języki programowania i pozwalają użytkownikom wspólnie tworzyć i wykonywać przepływy pracy ML.
4. Trenowanie i serwowanie modeli
- Training Operator: Obsługuje rozproszone trenowanie modeli ML przy użyciu popularnych frameworków, takich jak TensorFlow, PyTorch i XGBoost. Wykorzystuje skalowalność Kubernetes do efektywnego trenowania modeli na klastrach maszyn.
- KFServing: Zapewnia serwerlessową platformę inferencyjną do wdrażania wytrenowanych modeli ML. Upraszcza wdrażanie i skalowanie modeli, obsługując frameworki takie jak TensorFlow, PyTorch i scikit-learn.
5. Zarządzanie metadanymi
Kubeflow Metadata to centralne repozytorium do śledzenia i zarządzania metadanymi powiązanymi z eksperymentami ML, uruchomieniami i artefaktami. Zapewnia powtarzalność, współpracę i nadzór w projektach ML, oferując spójny widok metadanych ML.
6. Katib do strojenia hiperparametrów
Katib to komponent do automatycznego uczenia maszynowego (AutoML) w Kubeflow. Wspiera strojenie hiperparametrów, wczesne zatrzymywanie i poszukiwanie architektur sieciowych, optymalizując wydajność modeli ML poprzez automatyzację poszukiwania optymalnych hiperparametrów.
Zastosowania i przykłady
Kubeflow jest wykorzystywany przez organizacje z różnych branż do usprawniania operacji ML. Typowe przypadki użycia to:
- Przygotowanie i eksploracja danych: Wykorzystanie Jupyter Notebooks i Kubeflow Pipelines do efektywnego przetwarzania i analizy dużych zbiorów danych.
- Skalowalne trenowanie modeli: Wykorzystanie skalowalności Kubernetes do trenowania złożonych modeli na dużych zbiorach danych, co zwiększa dokładność i skraca czas trenowania.
- Zautomatyzowane przepływy pracy ML: Automatyzacja powtarzalnych zadań ML za pomocą Kubeflow Pipelines, zwiększająca produktywność i umożliwiająca naukowcom danych koncentrację na rozwoju i optymalizacji modeli.
- Serwowanie modeli w czasie rzeczywistym: Wdrażanie modeli jako skalowalnych, gotowych do produkcji usług za pomocą KFServing, gwarantując niskie opóźnienia predykcji dla aplikacji czasu rzeczywistego.
Studium przypadku: Spotify
Spotify wykorzystuje Kubeflow, aby umożliwić swoim naukowcom danych i inżynierom rozwijanie i wdrażanie modeli uczenia maszynowego na dużą skalę. Integrując Kubeflow z istniejącą infrastrukturą, Spotify usprawniło swoje przepływy pracy ML, skracając czas wprowadzania nowych funkcji na rynek i poprawiając efektywność systemów rekomendacyjnych.
Korzyści z używania Kubeflow
Skalowalność i przenośność
Kubeflow pozwala organizacjom skalować przepływy pracy ML w górę lub w dół według potrzeb i wdrażać je w różnych infrastrukturach — lokalnie, w chmurze lub w środowiskach hybrydowych. Ta elastyczność pomaga uniknąć uzależnienia od dostawcy i umożliwia płynne przejścia między różnymi środowiskami obliczeniowymi.
Powtarzalność i śledzenie eksperymentów
Architektura oparta na komponentach Kubeflow ułatwia powtarzanie eksperymentów i modeli. Zapewnia narzędzia do wersjonowania i śledzenia zbiorów danych, kodu i parametrów modeli, gwarantując spójność i współpracę wśród naukowców danych.
Rozszerzalność i integracja
Kubeflow zaprojektowano z myślą o rozszerzalności, umożliwiając integrację z innymi narzędziami i usługami, w tym chmurowymi platformami ML. Organizacje mogą dostosować Kubeflow, dodając kolejne komponenty i wykorzystując istniejące narzędzia i przepływy pracy, aby wzbogacić swój ekosystem ML.
Zmniejszenie złożoności operacyjnej
Automatyzując wiele zadań związanych z wdrażaniem i zarządzaniem przepływami pracy ML, Kubeflow pozwala naukowcom danych i inżynierom skupić się na zadaniach o wyższej wartości, takich jak rozwój i optymalizacja modeli, co przekłada się na wzrost produktywności i efektywności.
Lepsze wykorzystanie zasobów
Integracja Kubeflow z Kubernetes umożliwia efektywniejsze wykorzystanie zasobów, optymalizując alokację sprzętową i zmniejszając koszty związane z uruchamianiem zadań ML.
Jak zacząć z Kubeflow
Aby rozpocząć pracę z Kubeflow, użytkownicy mogą wdrożyć go na klastrze Kubernetes — lokalnie lub w chmurze. Dostępnych jest wiele przewodników instalacyjnych, dostosowanych do różnych poziomów zaawansowania i wymagań infrastrukturalnych. Osoby nowe w Kubernetes mogą skorzystać z zarządzanych usług, takich jak Vertex AI Pipelines, które upraszczają zarządzanie infrastrukturą i pozwalają skupić się na budowie oraz uruchamianiu przepływów pracy ML.
To szczegółowe omówienie Kubeflow przybliża jego funkcjonalności, korzyści i zastosowania, oferując kompleksowe zrozumienie dla organizacji chcących rozwijać swoje możliwości uczenia maszynowego.
Zrozumieć Kubeflow: zestaw narzędzi ML na Kubernetes
Kubeflow to projekt open source zaprojektowany, aby ułatwić wdrażanie, orkiestrację i zarządzanie modelami uczenia maszynowego na Kubernetes. Zapewnia kompleksowy, end-to-end stack do przepływów pracy ML, ułatwiając naukowcom danych i inżynierom budowę, wdrażanie i zarządzanie skalowalnymi modelami ML.
Wybrane publikacje i zasoby
Deployment of ML Models using Kubeflow on Different Cloud Providers
Autorzy: Aditya Pandey i in. (2022)
Artykuł analizuje wdrażanie modeli uczenia maszynowego przy użyciu Kubeflow na różnych platformach chmurowych. Studium dostarcza informacji o procesie instalacji, modelach wdrożeniowych i metrykach wydajności Kubeflow, będąc przydatnym przewodnikiem dla początkujących. Autorzy podkreślają możliwości i ograniczenia tego narzędzia oraz prezentują jego zastosowanie do budowy end-to-end pipeline’ów ML. Praca ma na celu wsparcie użytkowników z minimalnym doświadczeniem w Kubernetes w wykorzystaniu Kubeflow do wdrażania modeli.
Czytaj więcejCLAIMED, a visual and scalable component library for Trusted AI
Autorzy: Romeo Kienzler i Ivan Nesic (2021)
Praca koncentruje się na integracji zaufanych komponentów AI z Kubeflow. Podejmuje tematy takie jak wyjaśnialność, odporność i sprawiedliwość modeli AI. Autorzy przedstawiają CLAIMED — framework wielokrotnego użytku, który integruje narzędzia takie jak AI Explainability360 i AI Fairness360 z pipeline’ami Kubeflow. Integracja ta ułatwia tworzenie produkcyjnych aplikacji ML przy użyciu wizualnych edytorów, takich jak ElyraAI.
Czytaj więcejJet energy calibration with deep learning as a Kubeflow pipeline
Autorzy: Daniel Holmberg i in. (2023)
Kubeflow jest wykorzystywany do stworzenia pipeline’u ML do kalibracji pomiarów energii dżetów w eksperymencie CMS. Autorzy stosują modele deep learning do poprawy kalibracji energii dżetów, pokazując, jak możliwości Kubeflow można rozszerzyć na zastosowania w fizyce wysokich energii. Artykuł opisuje skuteczność pipeline’u w skalowaniu strojenia hiperparametrów i serwowaniu modeli na zasobach chmurowych.
Czytaj więcej
Najczęściej zadawane pytania
- Czym jest Kubeflow?
Kubeflow to otwarta platforma oparta na Kubernetes, zaprojektowana do usprawniania wdrażania, zarządzania i skalowania przepływów pracy uczenia maszynowego. Zapewnia kompleksowy zestaw narzędzi na cały cykl życia ML.
- Jakie są główne komponenty Kubeflow?
Kluczowe komponenty to Kubeflow Pipelines do orkiestracji przepływów pracy, centralny dashboard, integracja z Jupyter Notebooks, rozproszone trenowanie i serwowanie modeli, zarządzanie metadanymi oraz Katib do strojenia hiperparametrów.
- Jak Kubeflow poprawia skalowalność i powtarzalność?
Dzięki wykorzystaniu Kubernetes, Kubeflow umożliwia skalowalne zadania ML w różnych środowiskach i dostarcza narzędzi do śledzenia eksperymentów oraz ponownego użycia komponentów, zapewniając powtarzalność i efektywną współpracę.
- Kto korzysta z Kubeflow?
Organizacje z różnych branż używają Kubeflow do zarządzania i skalowania operacji ML. Znani użytkownicy, tacy jak Spotify, zintegrowali Kubeflow, aby usprawnić tworzenie i wdrażanie modeli.
- Jak zacząć pracę z Kubeflow?
Aby rozpocząć, wdroż Kubeflow na klastrze Kubernetes — na miejscu lub w chmurze. Dostępne są przewodniki instalacyjne i usługi zarządzane dla użytkowników o każdym poziomie zaawansowania.
Zacznij budować z Kubeflow
Odkryj, jak Kubeflow może uprościć Twoje przepływy pracy uczenia maszynowego na Kubernetes, od skalowalnego treningu po automatyczne wdrażanie.
Dowiedz się więcej