Uczenie Maszynowe
Uczenie maszynowe umożliwia komputerom uczenie się na podstawie danych, rozpoznawanie wzorców i dokonywanie predykcji, napędzając innowacje w branżach takich jak opieka zdrowotna, finanse, handel detaliczny i wielu innych.
Uczenie maszynowe (ML) to podzbiór sztucznej inteligencji (AI), który koncentruje się na umożliwieniu maszynom uczenia się na podstawie danych i poprawiania swojej wydajności w czasie bez jawnego programowania. Dzięki wykorzystaniu algorytmów ML pozwala systemom identyfikować wzorce, dokonywać predykcji oraz usprawniać podejmowanie decyzji na podstawie doświadczenia. W istocie uczenie maszynowe umożliwia komputerom działanie i uczenie się podobnie jak ludzie poprzez przetwarzanie ogromnych ilości danych.
Jak działa uczenie maszynowe?
Algorytmy uczenia maszynowego działają w cyklu uczenia się i ulepszania. Proces ten można podzielić na trzy główne elementy:
- Proces decyzyjny:
- Algorytmy ML są zaprojektowane do dokonywania predykcji lub klasyfikacji na podstawie danych wejściowych, które mogą być oznaczone lub nieoznakowane.
- Funkcja błędu:
- Funkcja błędu ocenia dokładność predykcji modelu poprzez porównanie jej z znanymi przykładami. Celem jest minimalizacja błędu.
- Optymalizacja modelu:
- Algorytm iteracyjnie dostosowuje swoje parametry, aby lepiej dopasować się do danych treningowych, optymalizując swoją wydajność w czasie. Proces ten trwa aż model osiągnie pożądany poziom dokładności.
Typy uczenia maszynowego
Modele uczenia maszynowego można ogólnie podzielić na trzy typy:
- Uczenie nadzorowane:
- W uczeniu nadzorowanym model jest trenowany na oznaczonych danych, czyli każdy przykład wejściowy ma przypisaną odpowiedź. Model uczy się przewidywać odpowiedź na podstawie danych wejściowych. Popularne metody to regresja liniowa, drzewa decyzyjne i maszyny wektorów nośnych.
- Uczenie nienadzorowane:
- Uczenie nienadzorowane dotyczy nieoznakowanych danych. Model stara się zidentyfikować wzorce i relacje w danych. Popularne techniki to klasteryzacja (np. K-średnich) i asocjacja (np. algorytm Apriori).
- Uczenie przez wzmacnianie:
- Ten typ uczenia polega na tym, że agent uczy się podejmować decyzje poprzez wykonywanie działań w środowisku, aby maksymalizować pewną formę skumulowanej nagrody. Jest szeroko stosowany w robotyce, grach i nawigacji.
Zastosowania uczenia maszynowego
Uczenie maszynowe znajduje szerokie zastosowanie w różnych branżach:
- Ochrona zdrowia:
- Analityka predykcyjna wyników pacjentów, spersonalizowane plany leczenia i analiza obrazów medycznych.
- Finanse:
- Wykrywanie oszustw, handel algorytmiczny i zarządzanie ryzykiem.
- Handel:
- Spersonalizowane rekomendacje, zarządzanie zapasami i segmentacja klientów.
- Transport:
- Pojazdy autonomiczne, optymalizacja tras i predykcyjne utrzymanie ruchu.
- Rozrywka:
- Systemy rekomendacji treści dla platform takich jak Netflix i Spotify.
Uczenie maszynowe vs. programowanie tradycyjne
Uczenie maszynowe różni się od tradycyjnego programowania możliwością uczenia się i adaptacji:
- Uczenie maszynowe:
- Wykorzystuje podejścia oparte na danych i potrafi odkrywać wzorce oraz spostrzeżenia w dużych zbiorach danych. Jest zdolne do samodoskonalenia na podstawie nowych danych.
- Programowanie tradycyjne:
- Opiera się na kodzie regułowym tworzonym przez programistów. Jest deterministyczne i nie potrafi samodzielnie się uczyć ani adaptować.
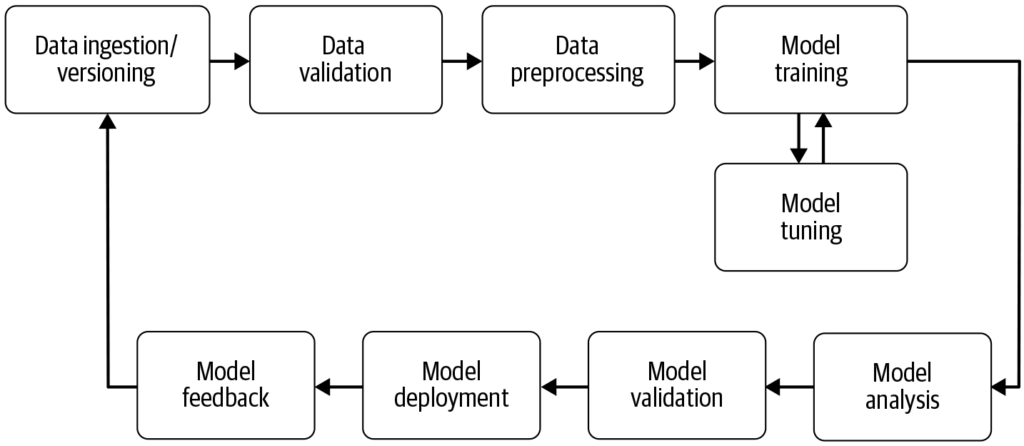
Cykl życia uczenia maszynowego
Cykl życia modelu uczenia maszynowego zwykle obejmuje następujące etapy:
- Zbieranie danych:
- Gromadzenie odpowiednich danych istotnych dla rozwiązywanego problemu.
- Przetwarzanie danych:
- Czyszczenie i transformacja danych, aby były odpowiednie do modelowania.
- Wybór modelu:
- Wybór odpowiedniego algorytmu w zależności od zadania (np. klasyfikacja, regresja).
- Trenowanie:
- Wprowadzenie danych do modelu w celu nauczenia się ukrytych wzorców.
- Ewaluacja:
- Ocena wydajności modelu przy użyciu danych testowych i różnych metryk.
- Wdrożenie:
- Integracja modelu z rzeczywistą aplikacją do podejmowania decyzji.
- Monitorowanie i utrzymanie:
- Ciągłe monitorowanie wydajności modelu i jego aktualizacja w razie potrzeby.
Ograniczenia uczenia maszynowego
Pomimo swoich możliwości, uczenie maszynowe ma pewne ograniczenia:
- Zależność od danych:
- Wymaga dużych ilości wysokiej jakości danych do treningu.
- Złożoność:
- Tworzenie i dostrajanie modeli może być skomplikowane i czasochłonne.
- Interpretowalność:
- Niektóre modele, zwłaszcza uczenie głębokie, są trudne do interpretacji.
Najczęściej zadawane pytania
- Czym jest uczenie maszynowe?
Uczenie maszynowe (ML) to gałąź AI, która umożliwia komputerom uczenie się na podstawie danych, identyfikowanie wzorców oraz dokonywanie predykcji lub podejmowanie decyzji bez jawnego programowania.
- Jakie są główne typy uczenia maszynowego?
Główne typy to uczenie nadzorowane, gdzie modele uczą się na oznaczonych danych; uczenie nienadzorowane, które odkrywa wzorce w nieoznakowanych danych; oraz uczenie przez wzmacnianie, gdzie agenci uczą się poprzez interakcję ze środowiskiem, aby maksymalizować nagrody.
- Czym różni się uczenie maszynowe od tradycyjnego programowania?
W przeciwieństwie do tradycyjnego programowania, które opiera się na jawnych regułach kodowanych przez programistów, uczenie maszynowe wykorzystuje podejścia oparte na danych do odkrywania wzorców i ciągłego ulepszania, co umożliwia systemom adaptację i samodoskonalenie.
- Jakie są typowe zastosowania uczenia maszynowego?
Uczenie maszynowe jest wykorzystywane w ochronie zdrowia do analityki predykcyjnej, w finansach do wykrywania oszustw, w handlu do personalizowanych rekomendacji, w transporcie do pojazdów autonomicznych oraz w rozrywce do rekomendacji treści.
- Jakie są ograniczenia uczenia maszynowego?
Uczenie maszynowe wymaga dużych ilości wysokiej jakości danych, może być złożone i czasochłonne w opracowaniu, a niektóre modele—takie jak uczenie głębokie—są trudne do interpretacji.
Gotowy, aby stworzyć własną AI?
Odkryj, jak FlowHunt umożliwia łatwe tworzenie inteligentnych chatbotów i narzędzi AI. Łącz intuicyjne bloki, aby zamienić swoje pomysły w zautomatyzowane Flows.
Dowiedz się więcej