
Pipeline uczenia maszynowego
Pipeline uczenia maszynowego automatyzuje etapy od zbierania danych po wdrożenie modelu, zwiększając efektywność, powtarzalność i skalowalność projektów uczenia maszynowego.
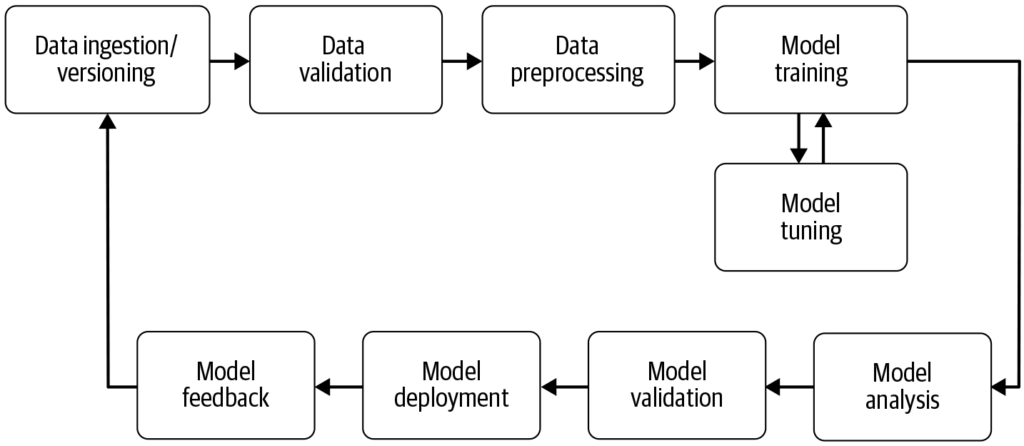
Pipeline uczenia maszynowego
Pipeline uczenia maszynowego to zautomatyzowany przepływ pracy, który usprawnia rozwój, trenowanie, ewaluację i wdrażanie modeli. Zwiększa efektywność, powtarzalność i skalowalność, ułatwiając realizację zadań od zbierania danych po wdrożenie i utrzymanie modelu.
Pipeline uczenia maszynowego to zautomatyzowany workflow obejmujący szereg kroków związanych z opracowywaniem, trenowaniem, ewaluacją i wdrażaniem modeli uczenia maszynowego. Ma na celu usprawnienie i standaryzację procesów potrzebnych do przekształcenia surowych danych w użyteczne wnioski za pomocą algorytmów uczenia maszynowego. Podejście pipeline pozwala na wydajne przetwarzanie danych, trenowanie modeli i wdrażanie, ułatwiając zarządzanie oraz skalowanie operacji uczenia maszynowego.
Źródło: Building Machine Learning
Komponenty pipeline’u uczenia maszynowego
Zbieranie danych: Początkowy etap, podczas którego dane są pozyskiwane z różnych źródeł, takich jak bazy danych, API czy pliki. Zbieranie danych to metodyczna praktyka mająca na celu zgromadzenie wartościowych informacji do budowy spójnego i kompletnego zbioru danych dla określonego celu biznesowego. Surowe dane są niezbędne do budowy modeli, ale często wymagają wstępnego przetworzenia, by były użyteczne. Jak podkreśla AltexSoft, zbieranie danych polega na systematycznym gromadzeniu informacji wspierających analitykę i podejmowanie decyzji. Ten proces stanowi podstawę dla kolejnych etapów pipeline’u i zwykle jest ciągły, by modele były trenowane na aktualnych danych.
Przetwarzanie danych: Surowe dane są czyszczone i przekształcane do odpowiedniego formatu dla trenowania modelu. Typowe etapy to usuwanie braków danych, kodowanie zmiennych kategorycznych, skalowanie cech numerycznych oraz podział danych na zbiory treningowe i testowe. Ten etap zapewnia poprawny format danych i eliminuje niespójności mogące wpłynąć na działanie modelu.
Inżynieria cech: Tworzenie nowych cech lub wybór istotnych cech z danych w celu zwiększenia przewidywalności modelu. Ten krok często wymaga wiedzy dziedzinowej i kreatywności. Inżynieria cech to twórczy proces przekształcania surowych danych w znaczące cechy lepiej odzwierciedlające problem i podnoszące efektywność modeli.
Wybór modelu: Wybór odpowiedniego algorytmu(-ów) uczenia maszynowego w zależności od typu problemu (np. klasyfikacja, regresja), charakterystyki danych i wymagań wydajnościowych. Na tym etapie często przeprowadza się także strojenie hiperparametrów. Dobór właściwego modelu ma kluczowe znaczenie dla dokładności i efektywności predykcji.
Trenowanie modelu: Wybrany(-e) model(-e) są trenowane na zbiorze treningowym, ucząc się wzorców i zależności w danych. Zamiast trenowania od zera, można też użyć modeli wstępnie wytrenowanych. Trenowanie to kluczowy etap, w którym model uczy się przewidywać na podstawie danych.
Ewaluacja modelu: Po trenowaniu ocenia się działanie modelu na osobnym zbiorze testowym lub za pomocą walidacji krzyżowej. Metryki ewaluacji zależą od problemu i mogą obejmować dokładność, precyzję, recall, F1-score, błąd średniokwadratowy i inne. Ten etap jest kluczowy, by upewnić się, że model dobrze sobie poradzi z nowymi danymi.
Wdrożenie modelu: Po opracowaniu i ocenie satysfakcjonującego modelu można go wdrożyć w środowisku produkcyjnym do predykcji na nowych, nieznanych danych. Wdrożenie często obejmuje tworzenie API i integrację z innymi systemami. To ostatni etap pipeline’u, w którym model staje się dostępny do rzeczywistego zastosowania.
Monitoring i utrzymanie: Po wdrożeniu niezwykle ważny jest ciągły monitoring działania modelu oraz jego ponowne trenowanie, jeśli zmieniają się wzorce w danych, aby model pozostał aktualny i wiarygodny. To ciągły proces, który sprawia, że model przez długi czas pozostaje skuteczny i relewantny.
Korzyści z pipeline’ów uczenia maszynowego
- Modularność: Pipeline’y dzielą proces uczenia maszynowego na modułowe, jasno zdefiniowane etapy, co ułatwia zarządzanie i utrzymanie workflow. Każdy komponent można rozwijać, testować i optymalizować niezależnie.
- Powtarzalność: Dzięki zdefiniowaniu sekwencji kroków i ich parametrów pipeline’y gwarantują, że cały proces można odtworzyć identycznie, co zapewnia spójność wyników. To kluczowe dla walidacji i utrzymania jakości modeli w czasie.
- Efektywność: Automatyzacja rutynowych zadań, takich jak przetwarzanie danych czy ewaluacja modeli, skraca czas i minimalizuje ryzyko błędów. Pozwala to specjalistom skupić się na bardziej złożonych zadaniach, np. inżynierii cech i strojenia modeli.
- Skalowalność: Pipeline’y obsługują duże zbiory danych i złożone workflow, umożliwiając zmiany bez konieczności konfigurowania wszystkiego od nowa. To niezbędne przy rosnących ilościach danych.
- Eksperymentowanie: Umożliwiają szybkie iteracje i optymalizacje poprzez testowanie różnych technik przetwarzania danych, wyboru cech i modeli. Ta elastyczność sprzyja innowacjom i ulepszaniu modeli.
- Wdrażanie: Pipeline’y ułatwiają płynną integrację modeli z systemami produkcyjnymi, dzięki czemu można skutecznie wykorzystywać je w praktyce.
- Współpraca: Strukturalne i udokumentowane workflow ułatwiają współpracę zespołową i dzielenie się wiedzą.
- Kontrola wersji i dokumentacja: Dzięki systemom kontroli wersji można śledzić wszelkie zmiany w kodzie i konfiguracji pipeline’u, co pozwala łatwo wrócić do wcześniejszych wersji. To kluczowe dla przejrzystości i niezawodności procesu rozwoju.
Przykłady zastosowań pipeline’ów uczenia maszynowego
Przetwarzanie języka naturalnego (NLP): Zadania NLP często obejmują wiele powtarzalnych kroków, takich jak pobieranie danych, czyszczenie tekstu, tokenizacja czy analiza sentymentu. Pipeline’y pomagają zorganizować te etapy, umożliwiając łatwe modyfikacje bez naruszania pozostałych komponentów.
Predykcyjna konserwacja: W branżach takich jak produkcja pipeline’y mogą służyć do przewidywania awarii urządzeń na podstawie analizy danych z sensorów, umożliwiając proaktywną konserwację i ograniczenie przestojów.
Finanse: Pipeline’y mogą automatyzować przetwarzanie danych finansowych w celu wykrywania oszustw, oceny ryzyka kredytowego czy prognozowania cen akcji, wspierając podejmowanie decyzji.
Zdrowie: W opiece zdrowotnej pipeline’y służą do przetwarzania obrazów medycznych lub danych pacjentów, wspierając diagnostykę czy przewidywanie wyników leczenia i poprawiając strategie terapeutyczne.
Wyzwania związane z pipeline’ami uczenia maszynowego
- Jakość danych: Zapewnienie wysokiej jakości i dostępności danych jest kluczowe, ponieważ słabe dane prowadzą do nietrafnych modeli. Wymaga to solidnego zarządzania danymi i odpowiednich narzędzi.
- Złożoność: Projektowanie i utrzymanie złożonych pipeline’ów bywa wyzwaniem i wymaga zarówno wiedzy z zakresu data science, jak i inżynierii oprogramowania. Warto stosować standardowe narzędzia i frameworki, by ograniczać tę złożoność.
- Integracja: Płynna integracja pipeline’ów z istniejącymi systemami i workflow wymaga starannego planowania i współpracy między zespołami data science a IT.
- Koszty: Zarządzanie zasobami obliczeniowymi i infrastrukturą potrzebną do dużych pipeline’ów może być kosztowne, dlatego konieczne jest odpowiednie planowanie i budżetowanie.
Związek z AI i automatyzacją
Pipeline’y uczenia maszynowego są integralną częścią AI i automatyzacji, zapewniając uporządkowaną strukturę do automatyzowania zadań uczenia maszynowego. W obszarze automatyzacji AI, pipeline’y zapewniają efektywne trenowanie i wdrażanie modeli, pozwalając systemom AI (np. chatbotom) uczyć się i adaptować do nowych danych bez ręcznej ingerencji. Taka automatyzacja jest kluczowa dla skalowania aplikacji AI i gwarantuje ich niezawodność oraz spójną wydajność w różnych dziedzinach. Dzięki pipeline’om organizacje mogą zwiększyć swoje możliwości AI, a ich modele uczenia maszynowego pozostają skuteczne i aktualne mimo zmieniającego się otoczenia.
Badania dotyczące pipeline’ów uczenia maszynowego
„Deep Pipeline Embeddings for AutoML” autorstwa Sebastiana Pinedy Arango i Josifa Grabocki (2023) opisuje wyzwania związane z optymalizacją pipeline’ów w zautomatyzowanym uczeniu maszynowym (AutoML). Autorzy proponują nową architekturę neuronową, która wychwytuje głębokie interakcje między komponentami pipeline’u. Pipeline’y są osadzane w postaciach latentnych za pomocą unikalnego kodera dla każdego komponentu, a te embeddingi wykorzystywane są w ramach optymalizacji bayesowskiej do wyszukiwania optymalnych pipeline’ów. Praca podkreśla wykorzystanie meta-uczenia do strojenia parametrów sieci embeddingu, prezentując najnowsze wyniki w optymalizacji pipeline’ów na wielu zbiorach danych. Czytaj więcej.
„AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” autorstwa Tien-Dung Nguyen i in. (2020) porusza problem czasochłonnej ewaluacji pipeline’ów w procesach AutoML. Autorzy krytykują tradycyjne metody optymalizacji bayesowskiej i genetycznej za ich nieefektywność. Proponują AVATAR — model zastępczy, który efektywnie ocenia poprawność pipeline’u bez jego uruchamiania. Takie podejście znacząco przyspiesza tworzenie i optymalizację skomplikowanych pipeline’ów poprzez szybkie eliminowanie niepoprawnych rozwiązań. Czytaj więcej.
„Data Pricing in Machine Learning Pipelines” autorstwa Zicun Cong i in. (2021) omawia kluczową rolę danych w pipeline’ach oraz potrzebę ich wyceny dla ułatwienia współpracy różnych interesariuszy. Praca przegląda najnowsze osiągnięcia w wycenie danych w kontekście uczenia maszynowego, koncentrując się na jej znaczeniu na różnych etapach pipeline’u. Przedstawia strategie wyceny danych do trenowania, współpracy przy trenowaniu modeli i dostarczania usług ML, podkreślając powstawanie dynamicznego ekosystemu. Czytaj więcej.
Najczęściej zadawane pytania
- Czym jest pipeline uczenia maszynowego?
Pipeline uczenia maszynowego to zautomatyzowana sekwencja kroków — od zbierania i przetwarzania danych, przez trenowanie, ewaluację aż po wdrażanie modelu — która usprawnia i standaryzuje proces budowy i utrzymania modeli uczenia maszynowego.
- Jakie są główne komponenty pipeline'u uczenia maszynowego?
Kluczowe komponenty obejmują zbieranie danych, przetwarzanie danych, inżynierię cech, wybór modelu, trenowanie modelu, ewaluację modelu, wdrożenie modelu oraz bieżący monitoring i utrzymanie.
- Jakie są korzyści z wykorzystania pipeline'ów uczenia maszynowego?
Pipeline'y uczenia maszynowego zapewniają modularność, efektywność, powtarzalność, skalowalność, lepszą współpracę i łatwiejsze wdrażanie modeli w środowiskach produkcyjnych.
- Jakie są typowe zastosowania pipeline'ów uczenia maszynowego?
Zastosowania obejmują przetwarzanie języka naturalnego (NLP), predykcyjną konserwację w przemyśle, ocenę ryzyka finansowego i wykrywanie oszustw oraz diagnostykę w opiece zdrowotnej.
- Jakie wyzwania są związane z pipeline'ami uczenia maszynowego?
Wyzwania to zapewnienie jakości danych, zarządzanie złożonością pipeline'u, integracja z istniejącymi systemami oraz kontrolowanie kosztów związanych z zasobami obliczeniowymi i infrastrukturą.
Zacznij budować swoje rozwiązania AI
Umów się na demo i dowiedz się, jak FlowHunt może pomóc zautomatyzować i skalować Twoje workflow uczenia maszynowego z łatwością.
Dowiedz się więcej
