Interpretowalność modelu
Interpretowalność modelu to zdolność rozumienia i zaufania predykcjom AI, kluczowa dla przejrzystości, zgodności oraz ograniczania uprzedzeń w branżach takich jak opieka zdrowotna i finanse.
Interpretowalność modelu
Interpretowalność modelu to rozumienie i zaufanie predykcjom AI, kluczowe w obszarach takich jak ochrona zdrowia i finanse. Obejmuje interpretowalność globalną i lokalną, budując zaufanie, zgodność i ograniczanie uprzedzeń dzięki metodom wewnętrznym oraz post-hoc.
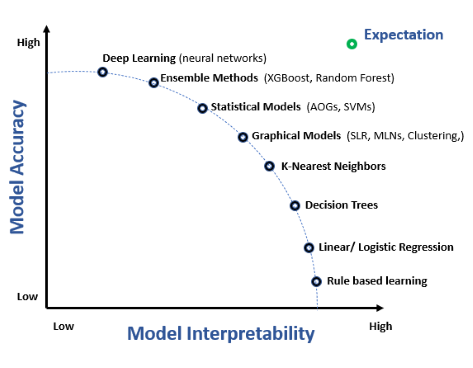
Interpretowalność modelu odnosi się do zdolności zrozumienia, wyjaśnienia i zaufania predykcjom oraz decyzjom podejmowanym przez modele uczenia maszynowego. Jest to kluczowy element w dziedzinie sztucznej inteligencji, szczególnie w zastosowaniach wymagających podejmowania decyzji, takich jak opieka zdrowotna, finanse czy systemy autonomiczne. Koncepcja ta jest centralna w data science, ponieważ łączy złożone modele obliczeniowe z ludzkim rozumieniem.
Czym jest interpretowalność modelu?
Interpretowalność modelu to stopień, w jakim człowiek może konsekwentnie przewidzieć wyniki modelu i zrozumieć przyczynę predykcji. Obejmuje zrozumienie relacji między cechami wejściowymi a wynikami generowanymi przez model, co pozwala interesariuszom pojąć powody stojące za konkretnymi prognozami. Zrozumienie to jest kluczowe dla budowania zaufania, zapewnienia zgodności z regulacjami oraz wspomagania procesów decyzyjnych.
Zgodnie z ramami opisanymi przez Liptona (2016) oraz Doshi-Velez & Kim (2017), interpretowalność obejmuje zdolność oceny i pozyskiwania informacji z modeli, których sam cel nie jest w stanie przekazać.
Interpretowalność globalna vs. lokalna
Interpretowalność modelu można podzielić na dwa główne rodzaje:
Interpretowalność globalna: Zapewnia ogólne zrozumienie funkcjonowania modelu, dając wgląd w jego ogólny proces podejmowania decyzji. Obejmuje poznanie struktury modelu, jego parametrów oraz relacji, które wydobywa z danych. Ten rodzaj interpretowalności jest kluczowy do oceny zachowania modelu w szerokim zakresie wejść.
Interpretowalność lokalna: Koncentruje się na wyjaśnianiu pojedynczych prognoz, oferując wgląd w to, dlaczego model podjął konkretną decyzję dla danego przypadku. Interpretowalność lokalna pomaga zrozumieć zachowanie modelu w określonych sytuacjach i jest niezbędna do debugowania oraz udoskonalania modeli. Do osiągnięcia lokalnej interpretowalności często stosuje się metody takie jak LIME czy SHAP, które przybliżają granicę decyzyjną modelu wokół konkretnej instancji.
Znaczenie interpretowalności modelu
Zaufanie i przejrzystość
Modele interpretowalne są bardziej godne zaufania w oczach użytkowników i interesariuszy. Przejrzystość w procesie podejmowania decyzji przez model jest kluczowa, zwłaszcza w sektorach takich jak ochrona zdrowia czy finanse, gdzie decyzje mają istotne skutki etyczne i prawne. Interpretowalność ułatwia zrozumienie i debugowanie, zapewniając, że modele można bezpiecznie wykorzystywać w krytycznych procesach decyzyjnych.
Bezpieczeństwo i zgodność z regulacjami
W branżach o wysokiej stawce, takich jak diagnostyka medyczna czy pojazdy autonomiczne, interpretowalność jest niezbędna dla zapewnienia bezpieczeństwa i spełnienia standardów regulacyjnych. Na przykład Rozporządzenie o Ochronie Danych Osobowych (RODO) w Unii Europejskiej wymaga, by osoby miały prawo do uzyskania wyjaśnienia decyzji algorytmicznych, które znacząco na nie wpływają. Interpretowalność modeli pomaga instytucjom przestrzegać tych przepisów, dostarczając jasnych wyjaśnień wyników algorytmów.
Wykrywanie i ograniczanie uprzedzeń
Interpretowalność ma kluczowe znaczenie dla identyfikacji i ograniczania uprzedzeń w modelach uczenia maszynowego. Modele trenowane na stronniczych danych mogą nieświadomie uczyć się i utrwalać społeczne uprzedzenia. Rozumiejąc proces decyzyjny, praktycy mogą identyfikować uprzedzone cechy i odpowiednio modyfikować modele, promując sprawiedliwość i równość w systemach AI.
Debugowanie i doskonalenie modeli
Modele interpretowalne ułatwiają proces debugowania, pozwalając specjalistom ds. danych zrozumieć i korygować błędy w predykcjach. Taka wiedza prowadzi do ulepszeń i podniesienia dokładności modeli. Interpretowalność pomaga odkryć przyczyny błędów lub nieoczekiwanych zachowań modelu, co ukierunkowuje dalszy rozwój modelu.
Metody osiągania interpretowalności
Istnieje wiele technik i podejść zwiększających interpretowalność modeli, które dzieli się na dwie główne kategorie: metody wewnętrzne i post-hoc.
Interpretowalność wewnętrzna
Polega na stosowaniu modeli z założenia prostych i przejrzystych. Przykłady to:
- Regresja liniowa: Umożliwia łatwą analizę wpływu cech wejściowych na predykcje, co czyni ją prostą do zrozumienia i analizy.
- Drzewa decyzyjne: Dostarczają wizualnej i logicznej reprezentacji decyzji, przez co są łatwe do interpretacji i komunikacji.
- Modele regułowe: Wykorzystują zestaw reguł do podejmowania decyzji, które można bezpośrednio analizować i rozumieć, oferując jasny wgląd w proces decyzyjny.
Interpretowalność post-hoc
Te metody stosuje się do złożonych modeli po ich wytrenowaniu, by je uczynić bardziej zrozumiałymi:
- LIME (Local Interpretable Model-agnostic Explanations): Dostarcza lokalnych wyjaśnień, przybliżając predykcje modelu prostymi, interpretowalnymi modelami w pobliżu rozpatrywanej instancji, pomagając zrozumieć konkretne predykcje.
- SHAP (SHapley Additive exPlanations): Oferuje zunifikowaną miarę ważności cech, rozważając wkład każdej cechy do predykcji i dostarczając wgląd w proces decyzyjny modelu.
- Partial Dependence Plots (PDPs): Wizualizują związek między cechą a przewidywanym wynikiem, uśredniając wpływ innych cech, co pozwala zrozumieć efekty poszczególnych cech.
- Mapy istotności (Saliency Maps): Wskazują obszary danych wejściowych, które najbardziej wpływają na predykcje; często wykorzystywane w przetwarzaniu obrazów, by zrozumieć na czym skupia się model.
Przykłady zastosowań interpretowalności modelu
Opieka zdrowotna
W diagnostyce medycznej interpretowalność jest kluczowa do weryfikacji prognoz AI i ich zgodności z wiedzą kliniczną. Modele stosowane do diagnozowania chorób czy rekomendowania leczenia muszą być interpretowalne, by zdobyć zaufanie lekarzy i pacjentów, co przekłada się na lepsze efekty terapeutyczne.
Finanse
Instytucje finansowe wykorzystują uczenie maszynowe do oceny kredytowej, wykrywania oszustw czy analizy ryzyka. Interpretowalność zapewnia zgodność z regulacjami oraz ułatwia zrozumienie decyzji finansowych, co pozwala łatwiej je uzasadnić interesariuszom i regulatorom. Ma to kluczowe znaczenie dla utrzymania zaufania i przejrzystości w operacjach finansowych.
Systemy autonomiczne
W pojazdach autonomicznych i robotyce interpretowalność jest ważna dla bezpieczeństwa i niezawodności. Zrozumienie procesu decyzyjnego AI pomaga przewidzieć zachowanie systemów w rzeczywistych sytuacjach oraz zapewnia ich działanie w granicach etycznych i prawnych, co jest istotne dla bezpieczeństwa publicznego i zaufania.
Automatyzacja AI i chatboty
W automatyzacji AI oraz chatbotach interpretowalność pomaga udoskonalać modele konwersacyjne i zapewniać trafność oraz rzetelność odpowiedzi. Ułatwia zrozumienie logiki interakcji chatbota i poprawę satysfakcji użytkowników, podnosząc jakość doświadczenia.
Wyzwania i ograniczenia
Kompromis między interpretowalnością a dokładnością
Często występuje kompromis między interpretowalnością modelu a jego dokładnością. Złożone modele, takie jak głębokie sieci neuronowe, mogą oferować wyższą dokładność kosztem interpretowalności. Osiągnięcie równowagi między tymi cechami stanowi wyzwanie wymagające uwzględnienia potrzeb zastosowania oraz oczekiwań interesariuszy.
Interpretowalność specyficzna dla domeny
Poziom wymaganej interpretowalności może się znacznie różnić w zależności od branży i zastosowania. Modele muszą być dostosowane do specyficznych potrzeb i wymagań danej dziedziny, by dostarczać wartościowych i użytecznych wniosków. Oznacza to konieczność rozpoznania wyzwań branżowych i projektowania modeli, które je skutecznie adresują.
Ocena interpretowalności
Pomiar interpretowalności jest trudny, ponieważ jest subiektywny i zależny od kontekstu. Model może być zrozumiały dla eksperta, lecz niezrozumiały dla laika. Opracowanie standardowych metryk oceny interpretowalności pozostaje przedmiotem badań, kluczowych dla rozwoju dziedziny i wdrażania interpretowalnych modeli.
Badania nad interpretowalnością modeli
Interpretowalność modeli to jeden z głównych kierunków badań w uczeniu maszynowym, pozwalający zrozumieć i zaufać predykcjom, szczególnie w takich dziedzinach jak medycyna precyzyjna czy automatyczne systemy decyzyjne. Oto kilka istotnych publikacji w tym obszarze:
Hybrid Predictive Model: When an Interpretable Model Collaborates with a Black-box Model
Autorzy: Tong Wang, Qihang Lin (Opublikowano: 2019-05-10)
W artykule przedstawiono ramy do budowy Hybrydowego Modelu Predykcyjnego (HPM), łączącego zalety modeli interpretowalnych i czarnej skrzynki. Model hybrydowy zastępuje model czarnej skrzynki na tych danych, gdzie wysoka wydajność nie jest wymagana, zwiększając przejrzystość przy minimalnej utracie dokładności. Autorzy proponują funkcję celu uwzględniającą dokładność, interpretowalność i przejrzystość. Badanie pokazuje skuteczność modelu hybrydowego w równoważeniu przejrzystości i wydajności predykcyjnej, zwłaszcza w danych strukturalnych i tekstowych. Czytaj więcejMachine Learning Model Interpretability for Precision Medicine
Autorzy: Gajendra Jung Katuwal, Robert Chen (Opublikowano: 2016-10-28)
Badanie podkreśla znaczenie interpretowalności modeli uczenia maszynowego dla medycyny precyzyjnej. Wykorzystuje algorytm Model-Agnostic Explanations do uczynienia złożonych modeli, takich jak lasy losowe, interpretowalnymi. Metoda została zastosowana do zbioru danych MIMIC-II w celu przewidywania śmiertelności na OIOM z 80% zrównoważoną dokładnością i wyjaśnienia wpływu poszczególnych cech, co ma kluczowe znaczenie dla decyzji medycznych. Czytaj więcejThe Definitions of Interpretability and Learning of Interpretable Models
Autorzy: Weishen Pan, Changshui Zhang (Opublikowano: 2021-05-29)
Artykuł proponuje nową matematyczną definicję interpretowalności w modelach uczenia maszynowego. Autorzy definiują interpretowalność w odniesieniu do ludzkich systemów rozpoznawania i przedstawiają ramy trenowania modeli w pełni interpretowalnych dla człowieka. Badanie pokazuje, że takie modele nie tylko zapewniają przejrzyste procesy decyzyjne, ale są także bardziej odporne na ataki przeciwnika. Czytaj więcej
Najczęściej zadawane pytania
- Czym jest interpretowalność modelu w uczeniu maszynowym?
Interpretowalność modelu to stopień, w jakim człowiek może konsekwentnie przewidywać i rozumieć wyniki modelu, wyjaśniając, jak cechy wejściowe wpływają na rezultaty oraz dlaczego model podejmuje określone decyzje.
- Dlaczego interpretowalność modelu jest ważna?
Interpretowalność buduje zaufanie, zapewnia zgodność z regulacjami, pomaga wykrywać uprzedzenia oraz ułatwia debugowanie i ulepszanie modeli AI, szczególnie w wrażliwych obszarach takich jak ochrona zdrowia i finanse.
- Czym są metody wewnętrznej i post-hoc interpretowalności?
Metody wewnętrzne wykorzystują proste, przejrzyste modele, takie jak regresja liniowa czy drzewa decyzyjne, które są interpretowalne z założenia. Metody post-hoc, takie jak LIME i SHAP, pomagają wyjaśnić złożone modele już po ich wytrenowaniu, przybliżając lub podkreślając istotne cechy.
- Jakie są wyzwania w osiąganiu interpretowalności modelu?
Wyzwania obejmują balansowanie między dokładnością a przejrzystością, specyficzne wymagania branżowe oraz subiektywny charakter pomiaru interpretowalności, jak również rozwój standardowych metryk oceny.
Gotowy, by stworzyć własną AI?
Inteligentne chatboty i narzędzia AI w jednym miejscu. Połącz intuicyjne bloki, by zamienić pomysły w zautomatyzowane Flows.