NLTK
NLTK to potężny, otwartoźródłowy zestaw narzędzi Pythona do analizy tekstu i przetwarzania języka naturalnego, oferujący rozbudowane funkcje dla zastosowań naukowych i przemysłowych.
NLTK
NLTK to kompleksowy zestaw narzędzi Pythona do symbolicznego i statystycznego NLP, oferujący funkcje takie jak tokenizacja, stemming, lematyzacja, tagowanie części mowy i wiele innych. Jest szeroko stosowany w środowisku akademickim i przemyśle do analizy tekstu oraz zadań związanych z przetwarzaniem języka.
Natural Language Toolkit (NLTK) to kompleksowy zestaw bibliotek i programów zaprojektowanych do symbolicznego i statystycznego przetwarzania języka naturalnego, który łączy interakcję człowiek-komputer. Poznaj jego kluczowe aspekty, sposób działania i zastosowania już dziś!") (NLP) dla języka programowania Python. NLTK, początkowo rozwijany przez Stevena Birda i Edwarda Lopera, jest darmowym, otwartoźródłowym projektem szeroko stosowanym zarówno w środowisku akademickim, jak i przemysłowym do analizy tekstu i przetwarzania języka. Szczególnie ceniony za łatwość użycia i bogaty zbiór zasobów, w tym ponad 50 korpusów i zasobów leksykalnych. NLTK obsługuje różne zadania NLP, takie jak tokenizacja, stemming, tagowanie, parsowanie i rozumowanie semantyczne, co czyni go wszechstronnym narzędziem dla lingwistów, inżynierów, edukatorów i naukowców.
Kluczowe funkcje i możliwości
Tokenizacja
Tokenizacja to proces dzielenia tekstu na mniejsze jednostki, takie jak słowa lub zdania. W NLTK tokenizację można przeprowadzać za pomocą funkcji takich jak word_tokenize i sent_tokenize, które są niezbędne do przygotowania danych tekstowych do dalszej analizy. Narzędzie oferuje łatwe w użyciu interfejsy do tych zadań, umożliwiając efektywne przetwarzanie tekstu.
Przykład:
from nltk.tokenize import word_tokenize, sent_tokenize
text = "NLTK is a great tool. It is widely used in NLP."
word_tokens = word_tokenize(text)
sentence_tokens = sent_tokenize(text)
Usuwanie słów stop
Słowa stop to często występujące wyrazy, które są zwykle usuwane z tekstu, aby zredukować szum i skupić się na istotnej treści. NLTK udostępnia listę słów stop dla różnych języków, co pomaga w zadaniach takich jak analiza częstotliwości czy analiza sentymentu. Funkcja ta jest kluczowa dla poprawy dokładności analizy tekstu poprzez odfiltrowanie nieistotnych słów.
Przykład:
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtered_words = [word for word in word_tokens if word.lower() not in stop_words]
Stemming
Stemming polega na sprowadzaniu słów do ich rdzennej formy, najczęściej poprzez usuwanie przedrostków lub przyrostków. NLTK oferuje kilka algorytmów stemmingu, takich jak Porter Stemmer, który jest powszechnie stosowany do upraszczania słów na potrzeby analizy. Stemming jest szczególnie przydatny w aplikacjach, gdzie dokładna forma słowa jest mniej ważna niż jego korzeń.
Przykład:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stems = [stemmer.stem(word) for word in word_tokens]
Lematyzacja
Lematyzacja jest podobna do stemmingu, ale skutkuje powstaniem słów poprawnych językowo, często z wykorzystaniem słownika do określenia formy podstawowej słowa. WordNetLemmatizer w NLTK to popularne narzędzie do tego celu, umożliwiające bardziej precyzyjną normalizację tekstu.
Przykład:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmas = [lemmatizer.lemmatize(word) for word in word_tokens]
Tagowanie części mowy (POS)
Tagowanie części mowy przypisuje każdemu słowu w tekście jego kategorię gramatyczną, taką jak rzeczownik, czasownik, przymiotnik itp., co jest kluczowe dla zrozumienia składni zdania. Funkcja pos_tag w NLTK ułatwia ten proces, umożliwiając bardziej szczegółową analizę lingwistyczną.
Przykład:
import nltk
pos_tags = nltk.pos_tag(word_tokens)
Rozpoznawanie nazwanych jednostek (NER)
Rozpoznawanie nazwanych jednostek identyfikuje i kategoryzuje kluczowe jednostki w tekście, takie jak nazwy osób, organizacji czy lokalizacji. NLTK udostępnia funkcje do NER: kluczowego narzędzia AI w NLP do identyfikacji i klasyfikowania jednostek w tekście, co wzbogaca analizę danych."), umożliwiając zaawansowaną analizę tekstu i wydobywanie wartościowych informacji z dokumentów.
Przykład:
from nltk import ne_chunk
entities = ne_chunk(pos_tags)
Rozkład częstotliwości
Rozkład częstotliwości służy do określania najczęściej występujących słów lub fraz w tekście. Funkcja FreqDist w NLTK pomaga wizualizować i analizować częstotliwość słów, co jest podstawą takich zadań jak ekstrakcja słów kluczowych czy modelowanie tematów.
Przykład:
from nltk import FreqDist
freq_dist = FreqDist(word_tokens)
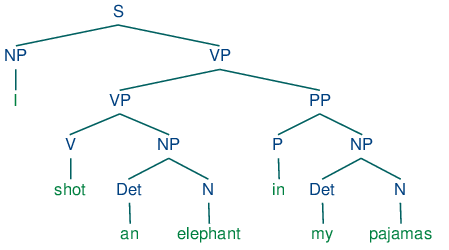
Parsowanie i generowanie drzew składniowych
Parsowanie polega na analizie struktury gramatycznej zdań. NLTK potrafi generować drzewa składniowe odzwierciedlające strukturę syntaktyczną, co umożliwia głębszą analizę lingwistyczną. Jest to niezbędne w aplikacjach takich jak tłumaczenie maszynowe czy parsowanie składniowe.
Przykład:
from nltk import CFG
from nltk.parse.generate import generate
grammar = CFG.fromstring("""
S -> NP VP
NP -> 'NLTK'
VP -> 'is' 'a' 'tool'
""")
parser = nltk.ChartParser(grammar)
Korpusy tekstowe
NLTK zawiera dostęp do różnorodnych korpusów tekstowych, które są niezbędne do trenowania i oceny modeli NLP. Zasoby te można łatwo wykorzystać w różnych zadaniach przetwarzania, dostarczając bogaty materiał do badań lingwistycznych i rozwoju aplikacji.
Przykład:
from nltk.corpus import gutenberg
sample_text = gutenberg.raw('austen-emma.txt')
Zastosowania i przykłady użycia
Badania naukowe
NLTK jest szeroko stosowany w badaniach naukowych do nauczania i eksperymentowania z koncepcjami przetwarzania języka naturalnego. Jego rozbudowana dokumentacja i zasoby sprawiają, że jest chętnie wybierany przez nauczycieli i studentów. Rozwój napędzany przez społeczność zapewnia, że narzędzie pozostaje na bieżąco z najnowszymi osiągnięciami NLP.
Przetwarzanie i analiza tekstu
Do zadań takich jak analiza sentymentu, modelowanie tematów czy ekstrakcja informacji NLTK udostępnia szeroki zestaw narzędzi, które można zintegrować z większymi systemami do przetwarzania tekstu. Możliwości te czynią z NLTK cenne narzędzie dla firm chcących wykorzystywać dane tekstowe do pozyskiwania wniosków.
Integracja z uczeniem maszynowym
NLTK można łączyć z bibliotekami uczenia maszynowego, takimi jak scikit-learn i TensorFlow, aby budować bardziej zaawansowane systemy rozumiejące i przetwarzające język ludzki. Integracja ta pozwala na tworzenie zaawansowanych aplikacji NLP, takich jak chatboty i systemy oparte na AI.
Lingwistyka komputerowa
Naukowcy z dziedziny lingwistyki komputerowej wykorzystują NLTK do badania i modelowania zjawisk językowych, korzystając z jego bogatego zestawu narzędzi do analizy i interpretacji danych językowych. Wsparcie dla wielu języków sprawia, że NLTK jest wszechstronnym narzędziem do badań międzyjęzykowych.
Instalacja i konfiguracja
NLTK można zainstalować za pomocą pip, a dodatkowe zbiory danych pobrać za pomocą funkcji nltk.download(). Narzędzie obsługuje różne platformy, w tym Windows, macOS i Linux, i wymaga Pythona w wersji 3.7 lub nowszej. Zaleca się instalację NLTK w środowisku wirtualnym, aby efektywnie zarządzać zależnościami.
Polecenie instalacyjne:
pip install nltk
Publikacje naukowe
NLTK: The Natural Language Toolkit (Opublikowano: 2002-05-17)
Ten podstawowy artykuł autorstwa Edwarda Lopera i Stevena Birda przedstawia NLTK jako kompleksowy zestaw otwartoźródłowych modułów, samouczków i zbiorów zadań przeznaczonych do lingwistyki komputerowej. NLTK obejmuje szerokie spektrum zadań przetwarzania języka naturalnego, zarówno symbolicznych, jak i statystycznych, oraz zapewnia interfejs do korpusów z anotacjami. Narzędzie zostało zaprojektowane tak, aby wspierać naukę poprzez praktykę, pozwalając użytkownikom manipulować zaawansowanymi modelami i uczyć się programowania strukturalnego. Czytaj więcejText Normalization for Low-Resource Languages of Africa (Opublikowano: 2021-03-29)
Badanie to analizuje zastosowanie NLTK w normalizacji tekstu i trenowaniu modeli językowych dla afrykańskich języków o ograniczonych zasobach. Autorzy wskazują na wyzwania w uczeniu maszynowym związane z danymi o wątpliwej jakości i ograniczonej dostępności. Wykorzystując NLTK, opracowali normalizator tekstu na bazie frameworka Pynini, demonstrując skuteczność narzędzia w obsłudze wielu języków afrykańskich i pokazując wszechstronność NLTK w różnych środowiskach językowych. Czytaj więcejNatural Language Processing, Sentiment Analysis and Clinical Analytics (Opublikowano: 2019-02-02)
Artykuł omawia połączenie NLP, analizy sentymentu i analityki klinicznej, podkreślając znaczenie NLTK. Pokazuje, jak rozwój big data umożliwił pracownikom służby zdrowia wydobywanie sentymentu i emocji z danych z mediów społecznościowych. NLTK jest wyróżnione jako kluczowe narzędzie implementujące różne teorie NLP, wspierające wydobywanie i analizę wartościowych informacji z tekstu i tym samym usprawniające procesy decyzyjne w klinice. Czytaj więcej
Najczęściej zadawane pytania
- Czym jest NLTK?
NLTK (Natural Language Toolkit) to kompleksowy zestaw bibliotek i programów Pythona do symbolicznego i statystycznego przetwarzania języka naturalnego (NLP). Oferuje narzędzia do tokenizacji, stemmingu, lematyzacji, tagowania części mowy, parsowania i wiele więcej, dzięki czemu jest szeroko wykorzystywany zarówno w środowisku akademickim, jak i przemysłowym.
- Co można zrobić za pomocą NLTK?
NLTK umożliwia wykonywanie szerokiego zakresu zadań NLP, w tym tokenizację, usuwanie słów stop, stemming, lematyzację, tagowanie części mowy, rozpoznawanie nazwanych jednostek, analizę rozkładu częstotliwości, parsowanie oraz pracę z korpusami tekstowymi.
- Kto używa NLTK?
NLTK jest używany przez naukowców, inżynierów, edukatorów i studentów w środowisku akademickim i przemyśle do budowania aplikacji NLP, eksperymentowania z koncepcjami przetwarzania języka oraz nauczania lingwistyki komputerowej.
- Jak zainstalować NLTK?
NLTK można zainstalować za pomocą pip, używając komendy 'pip install nltk'. Dodatkowe zbiory danych i zasoby można pobrać w Pythonie przy użyciu 'nltk.download()'.
- Czy NLTK można integrować z bibliotekami uczenia maszynowego?
Tak, NLTK można integrować z bibliotekami uczenia maszynowego, takimi jak scikit-learn i TensorFlow, aby budować zaawansowane aplikacje NLP, takie jak chatboty i inteligentne systemy analizy danych.
Wypróbuj NLTK z FlowHunt
Odkryj, jak NLTK może wzbogacić Twoje projekty NLP. Buduj inteligentne chatboty i narzędzia AI z intuicyjną platformą FlowHunt.