Odpowiadanie na pytania
Odpowiadanie na pytania z RAG ulepsza LLM, integrując wyszukiwanie danych w czasie rzeczywistym i generowanie języka naturalnego dla precyzyjnych, kontekstowo trafnych odpowiedzi.
Odpowiadanie na pytania
Odpowiadanie na pytania z wykorzystaniem Retrieval-Augmented Generation (RAG) ulepsza modele językowe poprzez integrację zewnętrznych danych w czasie rzeczywistym, zapewniając precyzyjne i trafne odpowiedzi. Optymalizuje to wydajność w dynamicznych dziedzinach, oferując lepszą dokładność, dynamiczną treść oraz zwiększoną trafność.
Odpowiadanie na pytania z Retrieval-Augmented Generation (RAG) to innowacyjna metoda, która łączy zalety wyszukiwania informacji i generowania języka naturalnego — tworzy tekst podobny do ludzkiego na podstawie danych, wzmacniając AI, chatboty, raporty oraz personalizując doświadczenia. To hybrydowe podejście zwiększa możliwości dużych modeli językowych (LLM) poprzez uzupełnianie ich odpowiedzi o odpowiednie, aktualne informacje pobrane z zewnętrznych źródeł danych. W przeciwieństwie do tradycyjnych metod opierających się wyłącznie na modelach wytrenowanych wcześniej, RAG dynamicznie integruje dane z zewnątrz, umożliwiając systemom udzielanie dokładniejszych i kontekstowo trafnych odpowiedzi, zwłaszcza w dziedzinach wymagających najnowszych informacji lub specjalistycznej wiedzy.
RAG optymalizuje wydajność LLM, zapewniając, że odpowiedzi są generowane nie tylko z wewnętrznego zbioru danych, ale także z wykorzystaniem autorytatywnych źródeł w czasie rzeczywistym. Takie podejście jest kluczowe w zadaniach odpowiadania na pytania w dynamicznych obszarach, gdzie informacje ciągle się zmieniają.
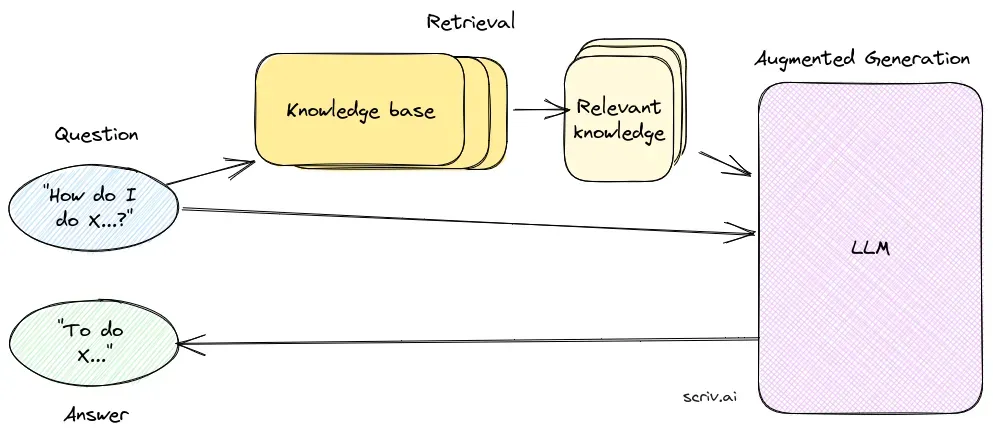
Kluczowe komponenty RAG
1. Komponent wyszukiwania
Komponent wyszukiwania odpowiada za pozyskiwanie odpowiednich informacji z rozległych zbiorów danych, zazwyczaj przechowywanych w bazie danych wektorowych. Wykorzystuje techniki wyszukiwania semantycznego do identyfikacji i ekstrakcji fragmentów tekstu lub dokumentów ściśle powiązanych z zapytaniem użytkownika.
- Baza danych wektorowych: Specjalistyczna baza, która przechowuje wektorowe reprezentacje dokumentów. Te osadzenia (embeddings) umożliwiają efektywne wyszukiwanie i pobieranie danych przez dopasowanie semantycznego znaczenia zapytania użytkownika do odpowiednich fragmentów tekstu.
- Wyszukiwanie semantyczne: Wykorzystuje osadzenia wektorowe do znajdowania dokumentów na podstawie podobieństw semantycznych, a nie tylko dopasowania słów kluczowych, poprawiając trafność i dokładność pozyskiwanych informacji.
2. Komponent generowania
Komponent generowania, zazwyczaj LLM taki jak GPT-3 lub BERT, syntetyzuje odpowiedź, łącząc oryginalne zapytanie użytkownika z pozyskanym kontekstem. Jest kluczowy do generowania spójnych i kontekstowo adekwatnych odpowiedzi.
- Modele językowe (LLM): Wytrenowane do generowania tekstu na podstawie podanych promptów, modele LLM w systemach RAG korzystają z pozyskanych dokumentów jako kontekstu, by zwiększać jakość i trafność generowanych odpowiedzi.
Przebieg działania systemu RAG
- Przygotowanie dokumentów: System zaczyna od załadowania obszernego korpusu dokumentów i konwertuje je do formatu odpowiedniego do analizy, często dzieląc je na mniejsze, łatwiejsze do zarządzania fragmenty.
- Wektoryzacja: Każdy fragment dokumentu jest zamieniany na reprezentację wektorową, wykorzystując osadzenia generowane przez modele językowe. Wektory te są przechowywane w bazie danych wektorowych, aby umożliwić efektywne wyszukiwanie.
- Przetwarzanie zapytania: Po otrzymaniu zapytania od użytkownika system konwertuje je na wektor i wykonuje wyszukiwanie podobieństwa w bazie wektorowej, aby zidentyfikować odpowiednie fragmenty dokumentów.
- Generowanie odpowiedzi w kontekście: Pozyskane fragmenty dokumentów są łączone z zapytaniem użytkownika i przekazywane do LLM, który generuje ostateczną, wzbogaconą kontekstowo odpowiedź.
- Wynik: System zwraca odpowiedź, która jest zarówno dokładna, jak i trafna względem zapytania, wzbogacona o odpowiedni kontekst.
Zalety RAG
- Zwiększona dokładność: Dzięki pozyskiwaniu odpowiedniego kontekstu RAG minimalizuje ryzyko generowania błędnych lub nieaktualnych odpowiedzi, co często zdarza się w samodzielnych LLM.
- Dynamiczna treść: Systemy RAG mogą integrować najnowsze informacje z aktualizowanych baz wiedzy, co czyni je idealnymi do zastosowań wymagających aktualnych danych.
- Zwiększona trafność: Proces wyszukiwania zapewnia, że generowane odpowiedzi są dostosowane do specyficznego kontekstu zapytania, poprawiając jakość i trafność odpowiedzi.
Przykłady zastosowań
- Chatboty i wirtualni asystenci: Systemy zasilane RAG ulepszają chatboty i wirtualnych asystentów, zapewniając precyzyjne i kontekstowe odpowiedzi, co poprawia interakcję i satysfakcję użytkowników.
- Wsparcie klienta: W aplikacjach obsługi klienta systemy RAG mogą pozyskiwać odpowiednie dokumenty polityk czy informacje o produktach, by udzielać precyzyjnych odpowiedzi na zapytania użytkowników.
- Tworzenie treści: Modele RAG mogą generować dokumenty i raporty, integrując pozyskane informacje, co czyni je przydatnymi w zadaniach automatycznego tworzenia treści.
- Narzędzia edukacyjne: W edukacji systemy RAG mogą zasilać asystentów naukowych, którzy udzielają wyjaśnień i podsumowań opartych na najnowszych materiałach dydaktycznych.
Implementacja techniczna
Wdrożenie systemu RAG obejmuje kilka technicznych etapów:
- Przechowywanie i wyszukiwanie wektorów: Wykorzystaj bazy danych wektorowych, takie jak Pinecone lub FAISS, do efektywnego przechowywania i wyszukiwania osadzeń dokumentów.
- Integracja modelu językowego: Zintegrowanie LLM, takich jak GPT-3 lub modele własne, przy użyciu frameworków typu HuggingFace Transformers do obsługi generowania tekstu.
- Konfiguracja pipeline’u: Skonfiguruj pipeline zarządzający przepływem od wyszukiwania dokumentów do generowania odpowiedzi, zapewniając płynną integrację wszystkich komponentów.
Wyzwania i kwestie do rozważenia
- Koszty i zarządzanie zasobami: Systemy RAG mogą być zasobożerne, wymagają optymalizacji dla skutecznego zarządzania kosztami obliczeniowymi.
- Dokładność faktograficzna: Zapewnienie, by pozyskane informacje były precyzyjne i aktualne, jest kluczowe, by zapobiec generowaniu wprowadzających w błąd odpowiedzi.
- Złożoność wdrożenia: Początkowa konfiguracja systemów RAG może być złożona, obejmując wiele komponentów wymagających uważnej integracji i optymalizacji.
Badania nad odpowiadaniem na pytania z Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) to metoda, która wzmacnia systemy odpowiadania na pytania przez połączenie mechanizmów wyszukiwania z modelami generatywnymi. Najnowsze badania obejmują skuteczność i optymalizację RAG w różnych kontekstach.
- In Defense of RAG in the Era of Long-Context Language Models: W artykule argumentuje się za utrzymaniem znaczenia RAG pomimo pojawienia się modeli językowych z długim kontekstem, które integrują dłuższe sekwencje tekstu w przetwarzaniu. Autorzy proponują mechanizm Order-Preserve Retrieval-Augmented Generation (OP-RAG), który optymalizuje wydajność RAG w zadaniach odpowiadania na pytania z długim kontekstem. Pokazują w eksperymentach, że OP-RAG może osiągnąć wysoką jakość odpowiedzi przy użyciu mniejszej liczby tokenów niż modele długokontekstowe. Czytaj więcej.
- CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems: Badanie to wprowadza ClapNQ, zestaw danych benchmarkowych do oceny systemów RAG generujących spójne, długie odpowiedzi. Zbiór koncentruje się na odpowiedziach osadzonych w konkretnych fragmentach tekstu, bez halucynacji, i zachęca modele RAG do formułowania zwięzłych, spójnych odpowiedzi. Autorzy prezentują eksperymenty bazowe, które wskazują potencjalne obszary rozwoju dla systemów RAG. Czytaj więcej.
- Optimizing Retrieval-Augmented Generation with Elasticsearch for Enhanced Question-Answering Systems: Badanie integruje Elasticsearch z frameworkiem RAG, aby zwiększyć efektywność i dokładność systemów odpowiadania na pytania. Na przykładzie Stanford Question Answering Dataset (SQuAD) w wersji 2.0, praca porównuje różne metody wyszukiwania i podkreśla przewagę schematu ES-RAG pod względem wydajności i trafności odpowiedzi, przewyższając inne metody o 0,51 punktu procentowego. Autorzy sugerują dalszą eksplorację interakcji między Elasticsearch a modelami językowymi w celu poprawy jakości odpowiedzi systemu. Czytaj więcej.
Najczęściej zadawane pytania
- Czym jest Retrieval-Augmented Generation (RAG) w odpowiadaniu na pytania?
RAG to metoda łącząca wyszukiwanie informacji i generowanie języka naturalnego, aby dostarczać precyzyjne, aktualne odpowiedzi poprzez integrację zewnętrznych źródeł danych z dużymi modelami językowymi.
- Jakie są główne komponenty systemu RAG?
System RAG składa się z komponentu wyszukiwania, który pozyskuje odpowiednie informacje z baz danych wektorowych za pomocą wyszukiwania semantycznego, oraz komponentu generowania, zwykle LLM, który syntetyzuje odpowiedzi na podstawie zapytania użytkownika i znalezionego kontekstu.
- Jakie są zalety stosowania RAG do odpowiadania na pytania?
RAG zwiększa dokładność dzięki pozyskiwaniu kontekstowo trafnych informacji, wspiera dynamiczną aktualizację treści z zewnętrznych baz wiedzy oraz poprawia trafność i jakość generowanych odpowiedzi.
- Jakie są typowe zastosowania odpowiadania na pytania opartego na RAG?
Typowe zastosowania obejmują chatboty AI, wsparcie klienta, automatyczne tworzenie treści oraz narzędzia edukacyjne wymagające precyzyjnych, świadomych kontekstu i aktualnych odpowiedzi.
- Jakie wyzwania należy wziąć pod uwagę wdrażając RAG?
Systemy RAG mogą być zasobożerne, wymagają starannej integracji dla optymalnej wydajności i muszą zapewniać wiarygodność pozyskanych informacji, by uniknąć błędnych lub nieaktualnych odpowiedzi.
Rozpocznij budowę AI do odpowiadania na pytania
Dowiedz się, jak Retrieval-Augmented Generation może wzmocnić Twojego chatbota i rozwiązania wsparcia dzięki odpowiedziom w czasie rzeczywistym i wysokiej dokładności.
Dowiedz się więcej