spaCy to solidna, otwartoźródłowa biblioteka stworzona do zaawansowanego przetwarzania języka naturalnego (NLP) w Pythonie. Wydana w 2015 roku przez Matthew Honnibala i Ines Montani, jest utrzymywana przez Explosion AI. spaCy cenione jest za wydajność, łatwość użycia i kompleksowe wsparcie dla NLP, dzięki czemu jest preferowanym wyborem do zastosowań produkcyjnych, w przeciwieństwie do bibliotek nastawionych na badania, takich jak NLTK. Zaimplementowany w Pythonie i Cythonie, zapewnia szybkie i efektywne przetwarzanie tekstu.
Historia i porównanie z innymi bibliotekami NLP
spaCy pojawiło się jako silna alternatywa dla innych bibliotek NLP, skupiając się na przemysłowej wydajności i dokładności. Podczas gdy NLTK oferuje elastyczne podejście algorytmiczne odpowiednie do badań i edukacji, spaCy zostało zaprojektowane z myślą o szybkim wdrażaniu w środowiskach produkcyjnych z gotowymi modelami do łatwej integracji. spaCy zapewnia przyjazne dla użytkownika API, idealne do efektywnej obsługi dużych zbiorów danych, dzięki czemu nadaje się do zastosowań komercyjnych. Porównania z innymi bibliotekami, takimi jak Spark NLP czy Stanford CoreNLP, często podkreślają szybkość i prostotę spaCy, co czyni ją optymalnym wyborem dla deweloperów potrzebujących solidnych, gotowych do produkcji rozwiązań.
Kluczowe funkcje spaCy
Tokenizacja
Dzieli tekst na słowa, znaki interpunkcyjne itd., zachowując strukturę oryginalnego tekstu — kluczowe dla zadań NLP.Rozpoznawanie części mowy (POS tagging)
Przypisuje typy wyrazów tokenom, takim jak rzeczowniki czy czasowniki, dostarczając informacji o strukturze gramatycznej tekstu.Analiza zależności (Dependency Parsing)
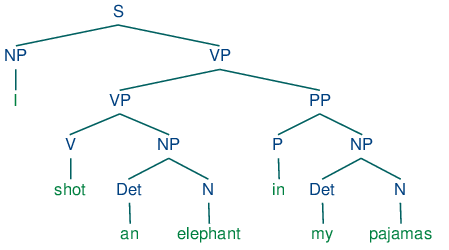
Analizuje strukturę zdania, ustalając relacje między wyrazami, identyfikując funkcje składniowe, takie jak podmiot czy dopełnienie.Rozpoznawanie nazwanych encji (NER)
Identyfikuje i kategoryzuje nazwane encje w tekście, takie jak osoby, organizacje i lokalizacje — kluczowe do ekstrakcji informacji.Klasyfikacja tekstu
Kategoryzuje dokumenty lub ich fragmenty, wspierając organizację i wyszukiwanie informacji.Podobieństwo (Similarity)
Mierzy podobieństwo między słowami, zdaniami lub dokumentami przy użyciu wektorów słów.Dopasowywanie regułowe
Wyszukuje sekwencje tokenów na podstawie ich tekstu i adnotacji językowych, na wzór wyrażeń regularnych.Uczenie wielozadaniowe z transformerami
Integruje modele oparte na transformerach, takie jak BERT, zwiększając dokładność i wydajność zadań NLP.Narzędzia wizualizacyjne
Obejmuje displaCy — narzędzie do wizualizacji składni i nazwanych encji, poprawiające interpretowalność analiz NLP.Konfigurowalne pipeline’y
Pozwalają użytkownikom dostosowywać workflow NLP przez dodawanie lub modyfikowanie komponentów w pipeline’ie przetwarzania.
Przykłady zastosowań
Data science i uczenie maszynowe
spaCy jest nieocenione w data science do wstępnego przetwarzania tekstu, ekstrakcji cech i trenowania modeli. Integracja z frameworkami jak TensorFlow i PyTorch jest kluczowa do budowy i wdrażania modeli NLP. Na przykład, spaCy może przygotować dane tekstowe przez tokenizację, normalizację i ekstrakcję cech jak nazwane encje, które można następnie wykorzystać do analizy sentymentu lub klasyfikacji tekstu.
Chatboty i asystenci AI
Możliwości spaCy w zakresie rozumienia języka naturalnego sprawiają, że świetnie sprawdza się ono w budowie chatbotów i asystentów AI. Obsługuje zadania takie jak rozpoznawanie intencji i ekstrakcja encji, kluczowe do tworzenia systemów konwersacyjnych. Przykładowo, chatbot korzystający ze spaCy może rozumieć zapytania użytkownika, identyfikując intencje i wyodrębniając istotne encje, umożliwiając generowanie adekwatnych odpowiedzi.
Ekstrakcja informacji i analiza tekstu
Powszechnie wykorzystywane do wydobywania uporządkowanych informacji z nieustrukturyzowanego tekstu, spaCy pozwala kategoryzować encje, relacje i zdarzenia. Jest to przydatne np. w analizie dokumentów czy ekstrakcji wiedzy. W analizie dokumentów prawnych spaCy potrafi automatycznie wyłuskać kluczowe informacje, takie jak strony umowy czy terminy prawne, automatyzując przegląd dokumentów i zwiększając efektywność workflowu.
Badania naukowe i zastosowania akademickie
Kompleksowe możliwości NLP spaCy czynią z niego cenne narzędzie dla badań naukowych i akademickich. Naukowcy mogą badać wzorce językowe, analizować korpusy tekstów i budować modele NLP dla określonych dziedzin. Przykładowo, spaCy może posłużyć w badaniach językoznawczych do identyfikacji wzorców użycia języka w różnych kontekstach.
Przykłady użycia spaCy w praktyce
Rozpoznawanie nazwanych encji
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp("Apple is looking at buying U.K. startup for $1 billion") for ent in doc.ents: print(ent.text, ent.label_) # Output: Apple ORG, U.K. GPE, $1 billion MONEYAnaliza zależności
for token in doc: print(token.text, token.dep_, token.head.text) # Output: Apple nsubj looking, is aux looking, looking ROOT looking, ...Klasyfikacja tekstu
spaCy można rozszerzyć o własne modele klasyfikacji tekstu, by kategoryzować tekst według zdefiniowanych etykiet.
Pakowanie i wdrażanie modeli
spaCy oferuje solidne narzędzia do pakowania i wdrażania modeli NLP, zapewniając gotowość do produkcji i łatwą integrację z istniejącymi systemami. Obejmuje to zarządzanie wersjami modeli, zależnościami i automatyzację workflowu.
Badania nad SpaCy i powiązane tematy
SpaCy to szeroko stosowana otwartoźródłowa biblioteka Pythona do zaawansowanego przetwarzania języka naturalnego (NLP). Jest dostosowana do zastosowań produkcyjnych i obsługuje różnorodne zadania NLP, takie jak tokenizacja, rozpoznawanie części mowy i rozpoznawanie nazwanych encji. Najnowsze publikacje naukowe podkreślają jej zastosowania, udoskonalenia i porównania z innymi narzędziami NLP, rozszerzając wiedzę o jej możliwościach i wdrożeniach.
Wybrane publikacje naukowe
| Tytuł | Autorzy | Data publikacji | Streszczenie | Link |
|---|---|---|---|---|
| Multi hash embeddings in spaCy | Lester James Miranda, Ákos Kádár, Adriane Boyd, Sofie Van Landeghem, Anders Søgaard, Matthew Honnibal | 2022-12-19 | Omawia implementację multi hash embeddings w spaCy w celu zmniejszenia zapotrzebowania na pamięć dla osadzeń słów. Ocena tej metody na zbiorach NER potwierdza wybory projektowe i ujawnia nieoczekiwane wyniki. | Czytaj więcej |
| Resume Evaluation through Latent Dirichlet Allocation and Natural Language Processing for Effective Candidate Selection | Vidhita Jagwani, Smit Meghani, Krishna Pai, Sudhir Dhage | 2023-07-28 | Przedstawia metodę oceny CV z użyciem LDA i detekcji encji spaCy, osiągając 82% dokładności i opisując wydajność NER spaCy. | Czytaj więcej |
| LatinCy: Synthetic Trained Pipelines for Latin NLP | Patrick J. Burns | 2023-05-07 | Prezentuje LatinCy — zgodne ze spaCy pipeline’y NLP dla łaciny, wykazujące wysoką dokładność w rozpoznawaniu części mowy i lematyzacji, pokazując elastyczność spaCy. | Czytaj więcej |
| Launching into clinical space with medspaCy: a new clinical text processing toolkit in Python | Hannah Eyre, Alec B Chapman, et al. | 2021-06-14 | Wprowadza medspaCy — narzędzie do przetwarzania tekstów klinicznych oparte na spaCy, integrujące podejścia regułowe i uczenie maszynowe do zastosowań klinicznych NLP. | Czytaj więcej |
Najczęściej zadawane pytania
- Czym jest spaCy?
spaCy to otwartoźródłowa biblioteka Pythona do zaawansowanego przetwarzania języka naturalnego (NLP), zaprojektowana z myślą o szybkości, wydajności i zastosowaniach produkcyjnych. Obsługuje zadania takie jak tokenizacja, rozpoznawanie części mowy, analiza zależności i rozpoznawanie nazwanych encji.
- Czym spaCy różni się od NLTK?
spaCy jest zoptymalizowane pod kątem środowisk produkcyjnych, oferując wstępnie wytrenowane modele i szybkie, przyjazne dla użytkownika API, co czyni je idealnym do obsługi dużych zbiorów danych i zastosowań komercyjnych. NLTK natomiast jest bardziej ukierunkowane na badania i oferuje elastyczne podejścia algorytmiczne odpowiednie do edukacji i eksperymentów.
- Jakie są kluczowe funkcje spaCy?
Do kluczowych funkcji należą tokenizacja, rozpoznawanie części mowy, analiza zależności, rozpoznawanie nazwanych encji, klasyfikacja tekstu, pomiar podobieństwa, dopasowywanie regułowe, integracja z transformerami, narzędzia wizualizacyjne oraz konfigurowalne pipeline'y NLP.
- Jakie są typowe zastosowania spaCy?
spaCy jest szeroko stosowane w data science do wstępnego przetwarzania tekstu i ekstrakcji cech, do budowy chatbotów i asystentów AI, do ekstrakcji informacji z dokumentów oraz w badaniach naukowych do analizy wzorców językowych.
- Czy spaCy można zintegrować z frameworkami deep learning?
Tak, spaCy można zintegrować z frameworkami takimi jak TensorFlow i PyTorch, co pozwala na płynny rozwój i wdrażanie zaawansowanych modeli NLP.
- Czy spaCy nadaje się do specjalistycznych dziedzin, takich jak medycyna lub prawo?
Tak, elastyczne API i możliwość rozbudowy spaCy pozwalają dostosować je do specjalistycznych zastosowań, takich jak przetwarzanie tekstów klinicznych (np. medspaCy) czy analiza dokumentów prawnych.
Odkryj AI ze spaCy
Dowiedz się, jak spaCy może zasilić Twoje projekty NLP — od chatbotów po ekstrakcję informacji i zastosowania badawcze.
Dowiedz się więcej