
Serwer Databricks MCP
Połącz swoich agentów AI z Databricks, aby zautomatyzować SQL, monitorować zadania i zarządzać przepływami pracy za pomocą Databricks MCP Server w FlowHunt.

Co robi serwer “Databricks” MCP?
Serwer Databricks MCP (Model Context Protocol) to wyspecjalizowane narzędzie, które łączy asystentów AI z platformą Databricks, umożliwiając płynną interakcję z zasobami Databricks za pośrednictwem interfejsów opartych na języku naturalnym. Serwer ten działa jako most pomiędzy dużymi modelami językowymi (LLM) a API Databricks, pozwalając LLM na wykonywanie zapytań SQL, listowanie zadań, pobieranie statusów zadań oraz uzyskiwanie szczegółowych informacji o zadaniach. Udostępniając te możliwości za pomocą protokołu MCP, serwer Databricks MCP umożliwia programistom i agentom AI automatyzację przepływów danych, zarządzanie zadaniami Databricks oraz usprawnienie operacji bazodanowych, podnosząc wydajność w środowiskach rozwoju opartych na danych.
Lista promptów
W repozytorium nie opisano szablonów promptów.
Lista zasobów
W repozytorium nie umieszczono jawnych zasobów.
Lista narzędzi
- run_sql_query(sql: str)
Wykonywanie zapytań SQL na hurtowni SQL Databricks. - list_jobs()
Lista wszystkich zadań Databricks w workspace. - get_job_status(job_id: int)
Pobranie statusu konkretnego zadania Databricks na podstawie jego ID. - get_job_details(job_id: int)
Uzyskanie szczegółowych informacji o wybranym zadaniu Databricks.
Przykładowe zastosowania tego serwera MCP
- Automatyzacja zapytań do bazy danych
Umożliwienie LLM-om i użytkownikom uruchamiania zapytań SQL na hurtowniach Databricks bezpośrednio z konwersacyjnych interfejsów, usprawniając przepływy analizy danych. - Zarządzanie zadaniami
Listowanie i monitorowanie zadań Databricks, pomagając użytkownikom śledzić bieżące lub zaplanowane zadania w swoim workspace. - Śledzenie statusu zadań
Szybkie pobieranie statusu konkretnych zadań Databricks, umożliwiając efektywny monitoring i rozwiązywanie problemów. - Szczegółowa inspekcja zadań
Dostęp do dogłębnych informacji o zadaniach Databricks, ułatwiając debugowanie i optymalizację pipeline’ów ETL lub zadań wsadowych.
Jak skonfigurować
Windsurf
- Upewnij się, że Python 3.7+ jest zainstalowany, a dane uwierzytelniające do Databricks są dostępne.
- Sklonuj repozytorium i zainstaluj wymagania poleceniem
pip install -r requirements.txt. - Utwórz plik
.envz danymi uwierzytelniającymi Databricks. - Dodaj Databricks MCP Server do swojej konfiguracji Windsurf:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Zapisz konfigurację i zrestartuj Windsurf. Zweryfikuj konfigurację, uruchamiając testowe zapytanie.
Przykład zabezpieczenia kluczy API:
{
"mcpServers": {
"databricks": {
"command": "python",
"args": ["main.py"],
"env": {
"DATABRICKS_HOST": "${DATABRICKS_HOST}",
"DATABRICKS_TOKEN": "${DATABRICKS_TOKEN}",
"DATABRICKS_HTTP_PATH": "${DATABRICKS_HTTP_PATH}"
}
}
}
}
Claude
- Zainstaluj Pythona 3.7+ i sklonuj repozytorium.
- Skonfiguruj plik
.envz danymi uwierzytelniającymi Databricks. - Skonfiguruj interfejs MCP Claude’a:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Zrestartuj Claude i zweryfikuj połączenie.
Cursor
- Sklonuj repozytorium i skonfiguruj środowisko Pythona.
- Zainstaluj zależności i utwórz plik
.envz danymi uwierzytelniającymi. - Dodaj serwer do konfiguracji Cursor:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Zapisz konfigurację i przetestuj połączenie.
Cline
- Przygotuj Pythona i dane uwierzytelniające jak wyżej.
- Sklonuj repozytorium, zainstaluj wymagania i skonfiguruj
.env. - Dodaj wpis serwera MCP do konfiguracji Cline:
{ "mcpServers": { "databricks": { "command": "python", "args": ["main.py"] } } } - Zapisz, zrestartuj Cline i sprawdź, czy serwer MCP działa poprawnie.
Uwaga: Zawsze zabezpieczaj swoje klucze API i sekrety, używając zmiennych środowiskowych, jak pokazano w powyższych przykładach konfiguracji.
Jak używać tego MCP w przepływach
Użycie MCP w FlowHunt
Aby zintegrować serwery MCP ze swoim przepływem w FlowHunt, zacznij od dodania komponentu MCP do przepływu i podłączenia go do swojego agenta AI:
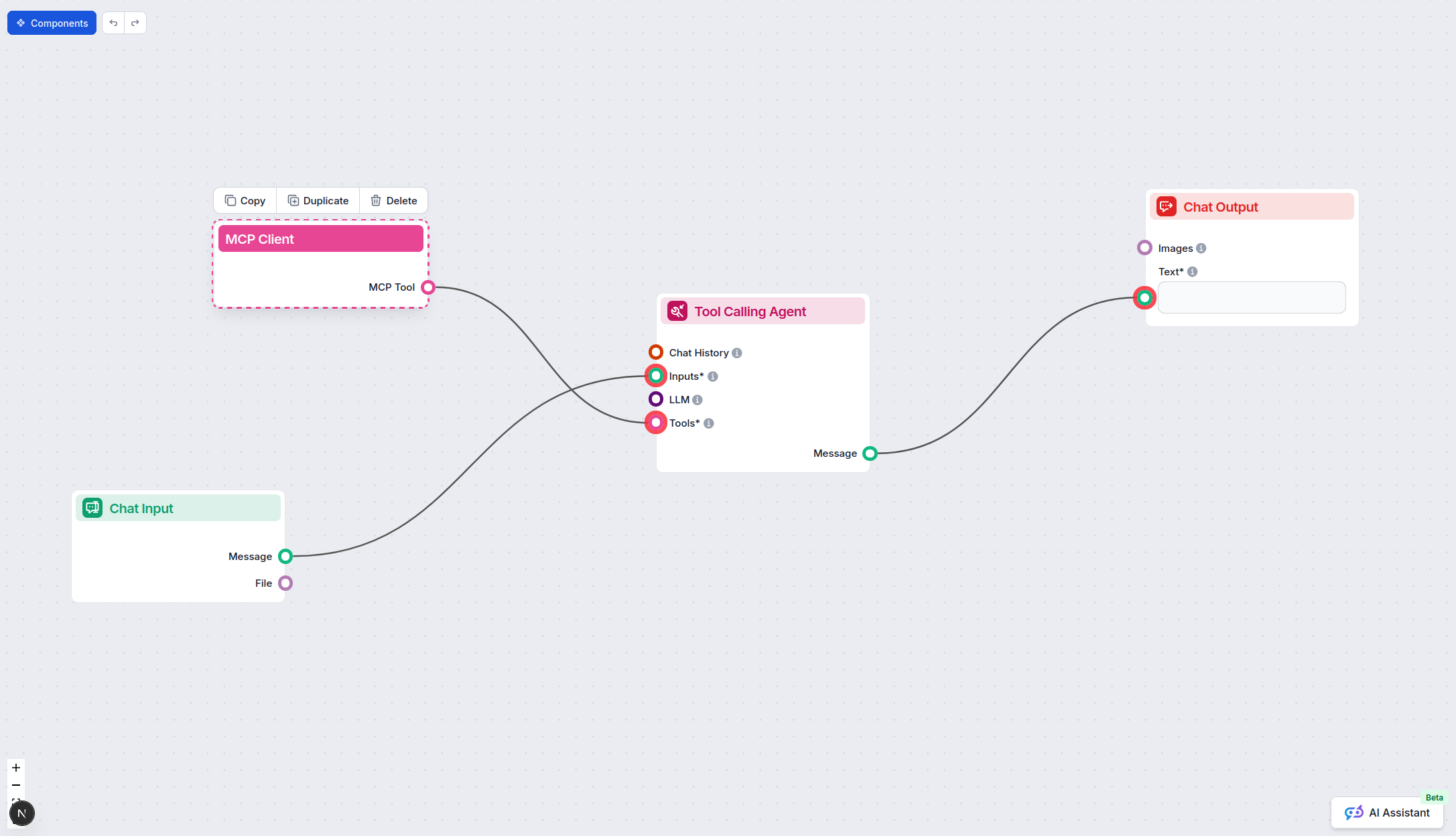
Kliknij na komponent MCP, aby otworzyć panel konfiguracji. W sekcji systemowej konfiguracji MCP wprowadź dane swojego serwera MCP w poniższym formacie JSON:
{
"databricks": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Po zapisaniu konfiguracji agent AI może używać tego MCP jako narzędzia, mając dostęp do wszystkich jego funkcji i możliwości. Pamiętaj, aby zamienić “databricks” na faktyczną nazwę swojego serwera MCP oraz podać własny adres URL.
Podsumowanie
| Sekcja | Dostępność | Szczegóły/Uwagi |
|---|---|---|
| Przegląd | ✅ | |
| Lista promptów | ⛔ | Brak szablonów promptów w repozytorium |
| Lista zasobów | ⛔ | Nie zdefiniowano jawnych zasobów |
| Lista narzędzi | ✅ | 4 narzędzia: run_sql_query, list_jobs, get_job_status, get_job_details |
| Zabezpieczanie kluczy API | ✅ | Poprzez zmienne środowiskowe w .env i JSON konfiguracyjnym |
| Wsparcie dla sampling (mniej istotne w ocenie) | ⛔ | Nie wspomniano |
| Wsparcie dla roots | ⛔ | Nie wspomniano |
Biorąc pod uwagę dostępność kluczowych funkcji (narzędzi, wskazówek dotyczących konfiguracji i bezpieczeństwa, ale brak zasobów i szablonów promptów), serwer Databricks MCP jest skuteczny do integracji z API Databricks, choć brakuje mu niektórych zaawansowanych prymitywów MCP. Oceniam ten serwer MCP na 6/10 pod względem kompletności i użyteczności w ekosystemie MCP.
MCP Score
| Posiada LICENSE | ⛔ (nie znaleziono) |
|---|---|
| Ma co najmniej jedno narzędzie | ✅ |
| Liczba forki | 13 |
| Liczba gwiazdek | 33 |
Najczęściej zadawane pytania
- Czym jest serwer Databricks MCP?
Serwer Databricks MCP to most pomiędzy asystentami AI a Databricks, udostępniający możliwości Databricks, takie jak wykonywanie zapytań SQL i zarządzanie zadaniami, poprzez protokół MCP dla zautomatyzowanych przepływów pracy.
- Jakie operacje obsługuje ten serwer MCP?
Obsługuje wykonywanie zapytań SQL, listowanie wszystkich zadań, pobieranie statusów zadań oraz uzyskiwanie szczegółowych informacji o określonych zadaniach Databricks.
- Jak bezpiecznie przechowywać dane uwierzytelniające Databricks?
Zawsze używaj zmiennych środowiskowych, np. umieszczając je w pliku `.env` lub konfigurując je w ustawieniach serwera MCP, zamiast wpisywać poufne dane na stałe w kodzie.
- Czy mogę używać tego serwera w przepływach FlowHunt?
Tak, wystarczy dodać komponent MCP do swojego przepływu, skonfigurować go z danymi serwera Databricks MCP, a Twoi agenci AI będą mieli dostęp do wszystkich obsługiwanych funkcji Databricks.
- Jaka jest ogólna ocena użyteczności tego serwera MCP?
Na podstawie dostępnych narzędzi, wskazówek dotyczących konfiguracji i bezpieczeństwa, ale przy braku zasobów i szablonów promptów, ten serwer MCP oceniam na 6/10 pod względem kompletności w ekosystemie MCP.
Zwiększ wydajność swoich przepływów pracy w Databricks
Automatyzuj zapytania SQL, monitoruj zadania i zarządzaj zasobami Databricks bezpośrednio z konwersacyjnych interfejsów AI. Zintegruj Databricks MCP Server ze swoimi przepływami w FlowHunt, by osiągnąć nowy poziom produktywności.
Dowiedz się więcej

