
Integracja z serwerem Pinecone MCP
Połącz FlowHunt z Pinecone, aby uzyskać zaawansowane wyszukiwanie semantyczne, zarządzanie danymi wektorowymi i aplikacje AI wspierane przez RAG.

Co robi serwer “Pinecone” MCP?
Serwer Pinecone MCP (Model Context Protocol) to wyspecjalizowane narzędzie łączące asystentów AI z bazami danych wektorowych Pinecone, umożliwiając płynny odczyt i zapis danych dla ulepszonych przepływów developerskich. Działając jako pośrednik, serwer Pinecone MCP pozwala klientom AI wykonywać zadania takie jak wyszukiwanie semantyczne, pobieranie dokumentów i zarządzanie bazą w ramach indeksu Pinecone. Obsługuje operacje takie jak zapytania o podobne rekordy, zarządzanie dokumentami oraz upsertowanie nowych embeddingów. Ta funkcjonalność jest szczególnie cenna w aplikacjach wykorzystujących Retrieval-Augmented Generation (RAG), gdyż usprawnia integrację danych kontekstowych z przepływami AI i automatyzuje złożone interakcje z danymi.
Lista promptów
Brak jawnych szablonów promptów w repozytorium.
Lista zasobów
- Indeks Pinecone: Główny zasób umożliwiający odczyt oraz zapis danych.
- Zasób dokumentu: Reprezentuje dokumenty przechowywane w indeksie Pinecone, które można odczytać lub wylistować.
- Zasób rekordu: Pojedyncze rekordy w indeksie Pinecone, które można wyszukiwać lub upsertować.
- Zasób statystyk Pinecone: Udostępnia statystyki dotyczące indeksu Pinecone, takie jak liczba rekordów, wymiary i przestrzenie nazw.
Lista narzędzi
- semantic-search: Wyszukuje rekordy w indeksie Pinecone na podstawie podobieństwa semantycznego.
- read-document: Odczytuje konkretny dokument z indeksu Pinecone.
- list-documents: Wylistowuje wszystkie dokumenty aktualnie przechowywane w indeksie Pinecone.
- pinecone-stats: Pobiera statystyki dotyczące indeksu Pinecone, w tym liczbę rekordów, ich wymiary i przestrzenie nazw.
- process-document: Przetwarza dokument na fragmenty, generuje embeddingi i upsertuje je do indeksu Pinecone.
Przykładowe zastosowania tego serwera MCP
- Zarządzanie bazą danych: Efektywny odczyt, zapis i zarządzanie danymi wektorowymi w indeksie Pinecone – wsparcie dla dużych aplikacji AI.
- Wyszukiwanie semantyczne: Umożliwia asystentom AI wyszukiwanie semantyczne w przechowywanych dokumentach, zwracając najbardziej trafne wyniki na podstawie podobieństwa wektorowego.
- Retrieval-Augmented Generation (RAG): Integracja zewnętrznej wiedzy w workflow LLM przez pobieranie odpowiedniego kontekstu z indeksu Pinecone do generowania odpowiedzi AI.
- Dzielenie i osadzanie dokumentów: Automatyczne dzielenie dokumentów na fragmenty, generowanie embeddingów i ich dodawanie do Pinecone – usprawnienie workflow wyszukiwania i pobierania dokumentów.
- Monitorowanie i statystyki indeksu: Uzyskiwanie bieżących informacji o stanie i wydajności indeksu Pinecone, co pomaga w optymalizacji i rozwiązywaniu problemów.
Jak skonfigurować
Windsurf
- Upewnij się, że masz zainstalowane Python i Node.js.
- Zlokalizuj plik konfiguracyjny Windsurf.
- Dodaj serwer Pinecone MCP za pomocą poniższego fragmentu JSON:
{ "mcpServers": { "pinecone-mcp": { "command": "mcp-pinecone", "args": [] } } } - Zapisz plik konfiguracyjny i uruchom ponownie Windsurf.
- Zweryfikuj, czy narzędzia Pinecone MCP Server są widoczne w interfejsie.
Zabezpieczenie kluczy API za pomocą zmiennych środowiskowych:
{
"mcpServers": {
"pinecone-mcp": {
"command": "mcp-pinecone",
"env": {
"PINECONE_API_KEY": "your_api_key"
},
"inputs": {
"index_name": "your_index"
}
}
}
}
Claude
- Zainstaluj serwer Pinecone MCP za pomocą Pythona (np.
pip install mcp-pinecone). - Edytuj konfigurację Claude, aby dodać serwer:
{ "mcpServers": { "pinecone-mcp": { "command": "mcp-pinecone", "args": [] } } } - Zapisz konfigurację i uruchom ponownie Claude.
- Potwierdź, że serwer działa i jest dostępny jako narzędzie.
Cursor
- Upewnij się, że Python i mcp-pinecone są zainstalowane.
- Przejdź do pliku konfiguracyjnego Cursor.
- Wstaw poniższy wpis serwera MCP:
{ "mcpServers": { "pinecone-mcp": { "command": "mcp-pinecone", "args": [] } } } - Zapisz zmiany i uruchom ponownie Cursor.
- Sprawdź listę narzędzi pod kątem operacji Pinecone.
Cline
- Zweryfikuj instalację Python i mcp-pinecone.
- Otwórz plik konfiguracyjny Cline.
- Dodaj serwer Pinecone MCP za pomocą:
{ "mcpServers": { "pinecone-mcp": { "command": "mcp-pinecone", "args": [] } } } - Zapisz i uruchom ponownie Cline.
- Upewnij się, że masz dostęp do narzędzi Pinecone.
Uwaga: Zawsze zabezpieczaj klucze API oraz wartości poufne jako zmienne środowiskowe, tak jak pokazano powyżej.
Jak używać tego MCP w przepływach
Używanie MCP w FlowHunt
Aby zintegrować serwery MCP z przepływem FlowHunt, zacznij od dodania komponentu MCP do swojego przepływu i połącz go ze swoim agentem AI:
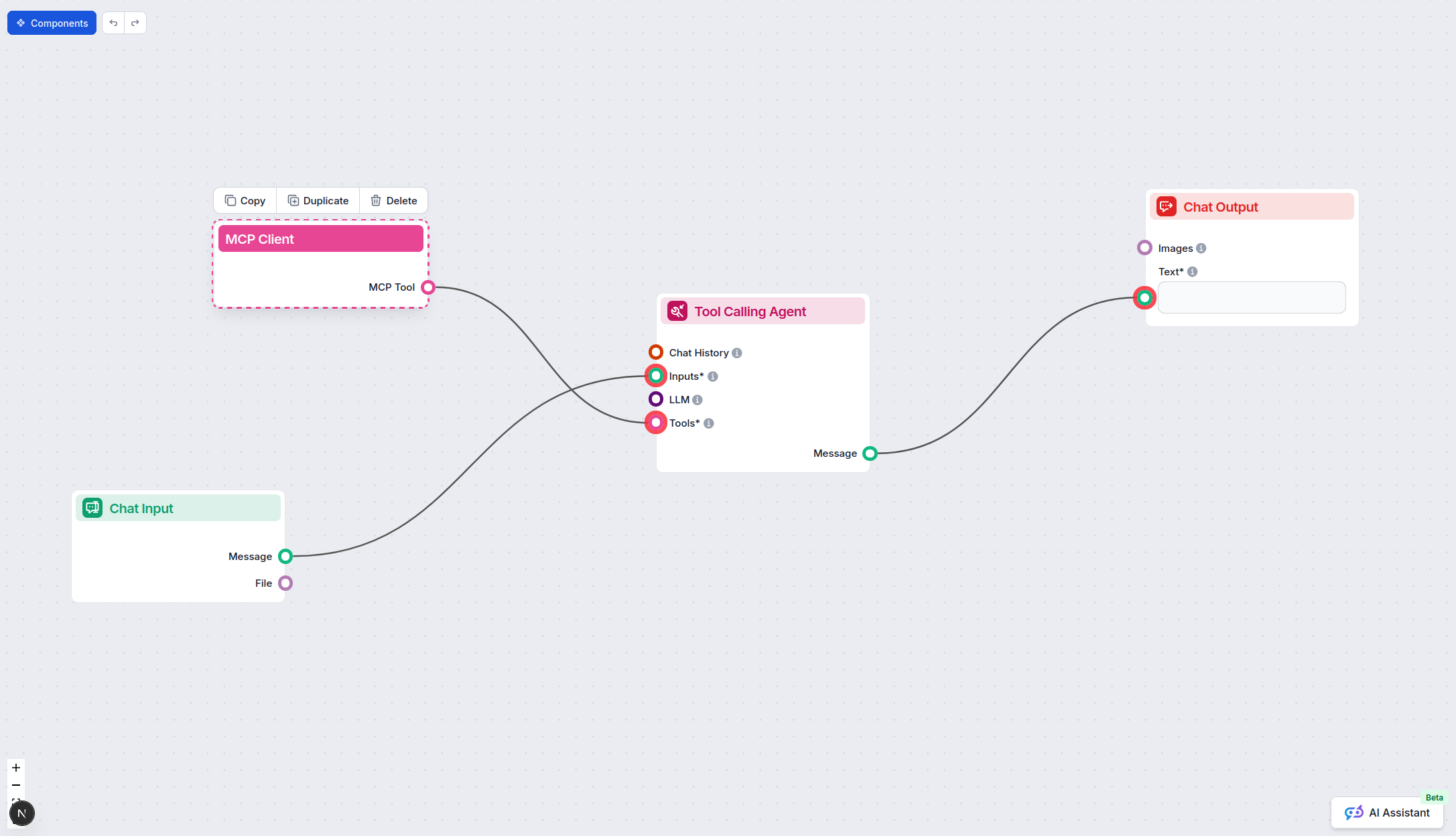
Kliknij komponent MCP, aby otworzyć panel konfiguracyjny. W sekcji konfiguracji systemu MCP wstaw dane swojego serwera MCP w tym formacie JSON:
{
"pinecone-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Po zapisaniu konfiguracji agent AI będzie mógł korzystać z MCP jako narzędzia z dostępem do wszystkich jego funkcji i możliwości. Pamiętaj, aby zamienić “pinecone-mcp” na faktyczną nazwę swojego serwera MCP oraz podać własny adres URL serwera MCP.
Przegląd
| Sekcja | Dostępność | Szczegóły/Uwagi |
|---|---|---|
| Przegląd | ✅ | Opisuje integrację Pinecone MCP z bazą danych wektorowych |
| Lista promptów | ⛔ | Brak jawnych szablonów promptów |
| Lista zasobów | ✅ | Indeks Pinecone, dokumenty, rekordy, statystyki |
| Lista narzędzi | ✅ | semantic-search, read-document, list-documents, pinecone-stats, process-document |
| Zabezpieczenie kluczy API | ✅ | Przykład z użyciem zmiennych środowiskowych w konfiguracji |
| Wsparcie dla sampling (mniej ważne) | ⛔ | Brak wzmianek lub dowodów |
Nasza opinia
Serwer Pinecone MCP jest dobrze udokumentowany, udostępnia jasne zasoby i narzędzia, a także zawiera solidne instrukcje dotyczące integracji i bezpieczeństwa kluczy API. Brakuje jednak jawnych szablonów promptów i dokumentacji dotyczącej sampling lub wsparcia roots. Ogólnie to praktyczny i wartościowy serwer dla workflow RAG i Pinecone, choć mógłby być uzupełniony o więcej przykładów workflow i zaawansowane funkcje.
Ocena: 8/10
Wynik MCP
| Posiada LICENCJĘ | ✅ (MIT) |
|---|---|
| Ma przynajmniej jedno narzędzie | ✅ |
| Liczba forków | 25 |
| Liczba gwiazdek | 124 |
Najczęściej zadawane pytania
- Czym jest serwer Pinecone MCP?
Serwer Pinecone MCP łączy asystentów AI z bazami danych wektorowych Pinecone, umożliwiając wyszukiwanie semantyczne, zarządzanie dokumentami oraz workflow osadzania w aplikacjach AI takich jak FlowHunt.
- Jakie narzędzia udostępnia serwer Pinecone MCP?
Udostępnia narzędzia do wyszukiwania semantycznego, odczytu i listowania dokumentów, pobierania statystyk indeksów oraz przetwarzania dokumentów do osadzania i upsertowania do indeksu Pinecone.
- Jak serwer Pinecone MCP wspiera Retrieval-Augmented Generation (RAG)?
Serwer pozwala agentom AI pobierać odpowiedni kontekst z Pinecone, umożliwiając LLM generowanie odpowiedzi opartych na zewnętrznych źródłach wiedzy.
- Jak bezpiecznie połączyć się z indeksem Pinecone?
Przechowuj klucz API Pinecone oraz nazwę indeksu jako zmienne środowiskowe w pliku konfiguracyjnym, zgodnie z instrukcją integracji, aby zachować bezpieczeństwo danych uwierzytelniających.
- Jakie są typowe zastosowania serwera Pinecone MCP?
Typowe zastosowania obejmują wyszukiwanie semantyczne w dużych zbiorach dokumentów, pipeline'y RAG, automatyczne dzielenie i osadzanie dokumentów oraz monitorowanie statystyk indeksów Pinecone.
Zwiększ możliwości swoich przepływów AI dzięki Pinecone
Włącz wyszukiwanie semantyczne i Retrieval-Augmented Generation w FlowHunt, łącząc swoich agentów AI z bazami danych wektorowych Pinecone.
Dowiedz się więcej

