
mcp-rag-local Serwer MCP
Lokalny, semantyczny serwer MCP dla FlowHunt, oparty na ChromaDB i Ollama. Umożliwia agentom AI zapamiętywanie i wyszukiwanie tekstów, dokumentów i plików PDF według znaczenia, wspierając potężne procesy RAG i zarządzania wiedzą.

Co robi serwer MCP “mcp-rag-local”?
mcp-rag-local to serwer MCP zaprojektowany jako serwer pamięci, który pozwala asystentom AI zapisywać i wyszukiwać fragmenty tekstu na podstawie znaczenia semantycznego, a nie tylko słów kluczowych. Wykorzystuje on Ollama do generowania embeddingów tekstu oraz ChromaDB do przechowywania wektorowego i wyszukiwania podobieństw, umożliwiając wygodne zapisywanie („zapamiętywanie”) oraz przywoływanie odpowiednich tekstów dla danego zapytania. Umożliwia to procesy oparte na AI, takie jak zarządzanie wiedzą, przywoływanie kontekstowe oraz wyszukiwanie semantyczne. Programiści mogą korzystać z serwera do zapisywania pojedynczych tekstów, wielu tekstów, a nawet zawartości plików PDF, a następnie wyszukiwać najbardziej kontekstowo powiązane informacje, zwiększając produktywność i świadomość kontekstową w aplikacjach.
Lista promptów
- W repozytorium ani dokumentacji nie wymieniono jawnych szablonów promptów.
Lista zasobów
- W repozytorium ani README nie udokumentowano jawnych zasobów MCP.
Lista narzędzi
memorize_text
Pozwala serwerowi zapisać pojedynczy fragment tekstu do przyszłego wyszukiwania semantycznego.memorize_multiple_texts
Umożliwia zbiorcze zapisywanie kilku tekstów jednocześnie, ułatwiając hurtowe gromadzenie wiedzy.memorize_pdf_file
Odczytuje i przetwarza do 20 stron jednocześnie z pliku PDF, dzieli treść i zapamiętuje ją do wyszukiwania semantycznego.retrieve_similar_texts
Wyszukuje najbardziej odpowiednie zapisane fragmenty tekstu na podstawie zapytania użytkownika, wykorzystując podobieństwo semantyczne.
(Nazwy narzędzi wydedukowane na podstawie udokumentowanych wzorców użycia; dokładne nazwy mogą się różnić w kodzie.)
Przykładowe zastosowania tego serwera MCP
Osobista baza wiedzy
Programiści i użytkownicy mogą budować trwałą, przeszukiwalną bazę wiedzy, zapamiętując artykuły, notatki lub publikacje naukowe do kontekstowego przywoływania.Streszczanie dokumentów i PDF
Po zapamiętaniu całych dokumentów PDF użytkownik może później zadawać pytania i przywoływać odpowiednie fragmenty lub streszczenia, usprawniając badania i przeglądanie.Pamięć konwersacyjna dla chatbotów
Rozszerz możliwości asystentów AI lub chatbotów o długoterminową, kontekstową pamięć, aby zapewnić bardziej spójne i adekwatne odpowiedzi w dłuższym czasie.Wyszukiwarka semantyczna
Zaimplementuj w aplikacji wyszukiwanie semantyczne, pozwalając użytkownikom znajdować istotne informacje na podstawie znaczenia, a nie tylko słów kluczowych.Eksploracja badań i danych
Przechowuj i przeszukuj dokumenty techniczne, fragmenty kodu lub literaturę naukową, aby szybko i znaczeniowo odzyskiwać informacje podczas analizy lub rozwoju.
Jak to skonfigurować
Windsurf
- Wymagania wstępne:
- Zainstaluj uv jako menedżera pakietów Pythona.
- Upewnij się, że Docker jest zainstalowany i uruchomiony.
- Klonowanie i instalacja:
- Sklonuj repozytorium:
git clone <repository-url>cd mcp-rag-local - Zainstaluj zależności używając uv.
- Sklonuj repozytorium:
- Uruchomienie usług:
- Uruchom
docker-compose up, aby wystartować ChromaDB i Ollama. - Pobierz model embeddingów:
docker exec -it ollama ollama pull all-minilm:l6-v2
- Uruchom
- Konfiguracja serwera MCP:
- Dodaj do konfiguracji serwera MCP Windsurf (np. w
mcpServers):"mcp-rag-local": { "command": "uv", "args": [ "--directory", "path\\to\\mcp-rag-local", "run", "main.py" ], "env": { "CHROMADB_PORT": "8321", "OLLAMA_PORT": "11434" } }
- Dodaj do konfiguracji serwera MCP Windsurf (np. w
- Zapisz i zrestartuj:
- Zapisz konfigurację i zrestartuj Windsurf.
- Zweryfikuj konfigurację:
- Upewnij się, że serwer działa i jest dostępny.
Claude
- Wykonaj kroki 1–3 powyżej (wymagania wstępne, klonowanie/instalacja, uruchomienie usług).
- Dodaj poniższe do konfiguracji MCP Claude:
"mcpServers": { "mcp-rag-local": { "command": "uv", "args": [ "--directory", "path\\to\\mcp-rag-local", "run", "main.py" ], "env": { "CHROMADB_PORT": "8321", "OLLAMA_PORT": "11434" } } } - Zapisz i zrestartuj Claude.
- Zweryfikuj, czy serwer jest widoczny i działa.
Cursor
- Zrealizuj kroki 1–3 (jak wyżej).
- Dodaj do konfiguracji Cursor:
"mcpServers": { "mcp-rag-local": { "command": "uv", "args": [ "--directory", "path\\to\\mcp-rag-local", "run", "main.py" ], "env": { "CHROMADB_PORT": "8321", "OLLAMA_PORT": "11434" } } } - Zapisz i zrestartuj Cursor.
- Sprawdź, czy serwer MCP działa.
Cline
- Powtórz kroki 1–3 (wymagania wstępne, klonowanie/instalacja, uruchomienie usług).
- W konfiguracji Cline dodaj:
"mcpServers": { "mcp-rag-local": { "command": "uv", "args": [ "--directory", "path\\to\\mcp-rag-local", "run", "main.py" ], "env": { "CHROMADB_PORT": "8321", "OLLAMA_PORT": "11434" } } } - Zapisz, zrestartuj Cline i sprawdź konfigurację.
Zabezpieczanie kluczy API
- Używaj zmiennych środowiskowych w sekcji
envswojej konfiguracji. - Przykład:
"env": { "CHROMADB_PORT": "8321", "OLLAMA_PORT": "11434", "MY_API_KEY": "${MY_API_KEY}" } - Upewnij się, że poufne klucze nie są wpisywane na stałe, lecz pobierane ze środowiska.
Jak używać tego MCP w flow
Korzystanie z MCP w FlowHunt
Aby zintegrować serwery MCP z przepływem pracy w FlowHunt, zacznij od dodania komponentu MCP do flow i połącz go ze swoim agentem AI:
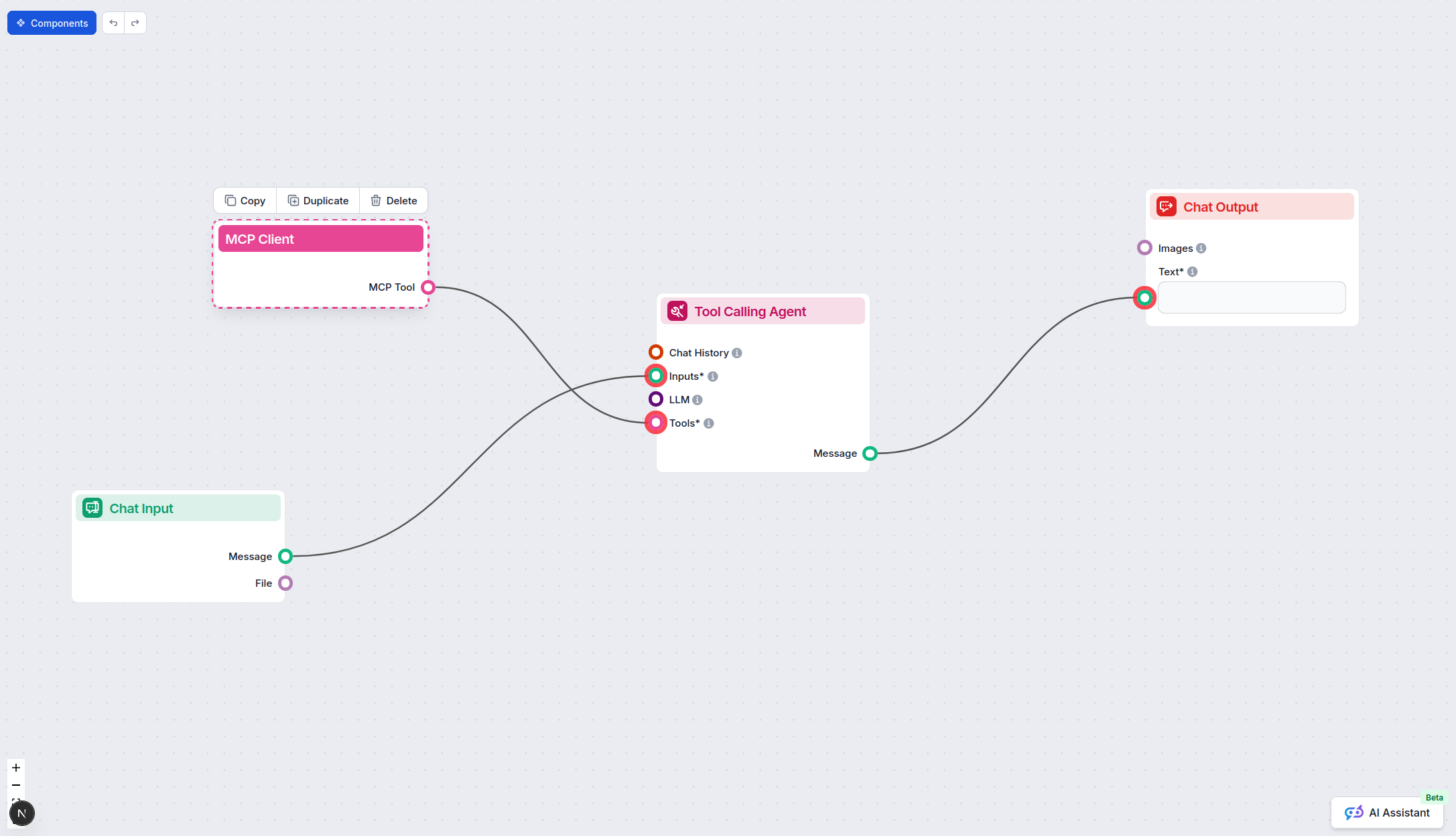
Kliknij komponent MCP, aby otworzyć panel konfiguracji. W sekcji konfiguracji systemowego MCP wprowadź dane swojego serwera MCP w tym formacie JSON:
{
"mcp-rag-local": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Po skonfigurowaniu agent AI może korzystać z tego MCP jako narzędzia ze wszystkimi jego funkcjami i możliwościami. Pamiętaj, by “mcp-rag-local” zamienić na faktyczną nazwę swojego serwera MCP i podać własny adres URL serwera MCP.
Przegląd
| Sekcja | Dostępność | Szczegóły/Uwagi |
|---|---|---|
| Przegląd | ✅ | |
| Lista promptów | ⛔ | Brak udokumentowanych promptów/szablonów |
| Lista zasobów | ⛔ | Brak udokumentowanych zasobów |
| Lista narzędzi | ✅ | memorize_text, memorize_multiple_texts, itd. |
| Zabezpieczanie kluczy API | ✅ | przez env w configu, pokazano przykład |
| Wsparcie dla sampling (mało istotne) | ⛔ | Nie wspomniano |
Nasza opinia
Ten MCP jest prosty i skupiony na pamięci semantycznej, ale nie posiada zaawansowanych funkcji, takich jak szablony promptów, jawne zasoby czy wsparcie sampling/roots. Narzędzia i konfiguracja są przejrzyste. Najlepszy do prostych lokalnych procesów RAG/wiedzy.
Ocena MCP
| Ma LICENCJĘ | ✅ (MIT) |
|---|---|
| Ma przynajmniej jedno narzędzie | ✅ |
| Liczba forków | 1 |
| Liczba gwiazdek | 5 |
Najczęściej zadawane pytania
- Czym jest serwer mcp-rag-local MCP?
To lokalny serwer MCP, który daje agentom AI możliwość zapisywania i wyszukiwania tekstów, dokumentów i plików PDF na podstawie znaczenia semantycznego. Oparty na Ollama i ChromaDB, umożliwia zarządzanie wiedzą, pamięć kontekstową oraz wyszukiwanie semantyczne w Twoich aplikacjach.
- Jakie narzędzia oferuje mcp-rag-local?
Oferuje narzędzia do zapisywania pojedynczych lub wielu fragmentów tekstu, przetwarzania plików PDF oraz wyszukiwania podobnych tekstów za pomocą wyszukiwania semantycznego. Umożliwia to np. budowę osobistych baz wiedzy, streszczanie dokumentów czy pamięć konwersacyjną dla chatbotów.
- Jak skonfigurować mcp-rag-local?
Zainstaluj uv i Dockera, sklonuj repozytorium, uruchom Ollama i ChromaDB oraz skonfiguruj serwer MCP w pliku konfiguracyjnym klienta ze wskazanymi portami. Zmienna środowiskowe służą do bezpiecznej konfiguracji.
- Jakie są główne zastosowania?
Przykłady zastosowań to budowa semantycznej bazy wiedzy, streszczenia dokumentów/PDF, wzbogacanie pamięci chatbota, wyszukiwanie semantyczne oraz eksploracja danych naukowych.
- Jak zabezpieczyć klucze API lub porty?
Zawsze używaj zmiennych środowiskowych w sekcji env swojej konfiguracji, aby nie umieszczać wrażliwych danych na stałe, zapewniając bezpieczeństwo i zgodność z dobrymi praktykami.
Wypróbuj mcp-rag-local z FlowHunt
Wzmocnij swoje procesy AI dzięki pamięci semantycznej i lokalnemu wyszukiwaniu dokumentów z mcp-rag-local. Skonfiguruj w kilka minut i zmień sposób, w jaki Twoi agenci przywołują i analizują wiedzę.
Dowiedz się więcej

