
LLM Mistral
O LLM Mistral no FlowHunt permite integração flexível de modelos avançados de IA da Mistral para geração de texto fluida em chatbots e ferramentas de IA.
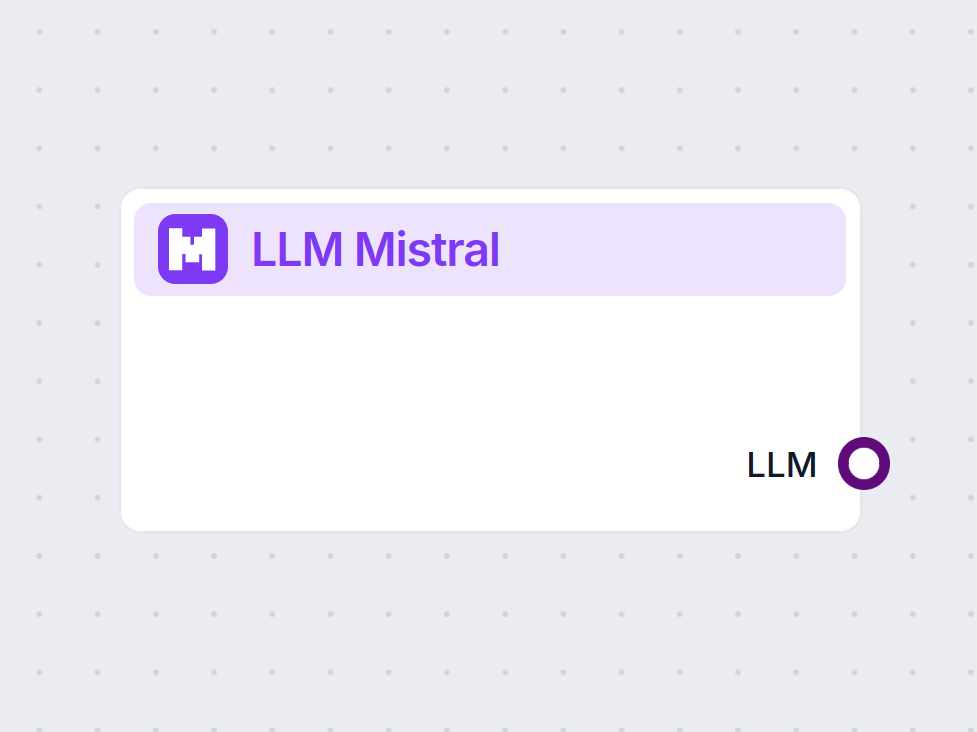
Descrição do componente
Como o componente LLM Mistral funciona
O que é o componente LLM Mistral?
O componente LLM Mistral conecta os modelos da Mistral ao seu fluxo. Enquanto os Geradores e Agentes são onde a mágica realmente acontece, os componentes LLM permitem que você controle o modelo utilizado. Todos os componentes vêm com o ChatGPT-4 como padrão. Você pode conectar este componente caso deseje trocar o modelo ou ter mais controle sobre ele.
Lembre-se de que conectar um componente LLM é opcional. Todos os componentes que usam um LLM vêm com o ChatGPT-4o como padrão. Os componentes LLM permitem trocar o modelo e controlar as configurações do modelo.
Configurações do componente LLM Mistral
Tokens Máximos
Tokens representam as unidades individuais de texto que o modelo processa e gera. O uso de tokens varia conforme o modelo, e um único token pode ser desde palavras ou subpalavras até um único caractere. Os modelos normalmente são precificados em milhões de tokens.
A configuração de tokens máximos limita o número total de tokens que podem ser processados em uma única interação ou requisição, garantindo que as respostas sejam geradas dentro de limites razoáveis. O limite padrão é de 4.000 tokens, que é o tamanho ideal para resumir documentos e várias fontes para gerar uma resposta.
Temperatura
A temperatura controla a variabilidade das respostas, variando de 0 a 1.
Uma temperatura de 0,1 fará com que as respostas sejam muito objetivas, mas potencialmente repetitivas e deficientes.
Uma temperatura alta de 1 permite máxima criatividade nas respostas, mas cria o risco de respostas irrelevantes ou até mesmo alucinatórias.
Por exemplo, a temperatura recomendada para um bot de atendimento ao cliente é entre 0,2 e 0,5. Esse nível mantém as respostas relevantes e dentro do roteiro, permitindo uma variação natural.
Modelo
Aqui é onde você escolhe o modelo. Aqui, você encontrará todos os modelos suportados da Mistral. Atualmente, suportamos os seguintes modelos:
- Mistral 7B – Um modelo de linguagem com 7,3 bilhões de parâmetros utilizando a arquitetura transformers, lançado sob a licença Apache 2.0. Apesar de ser um projeto menor, frequentemente supera o modelo Llama 2 da Meta. Veja como ele se saiu em nossos testes.
- Mistral 8x7B (Mixtral) – Este modelo utiliza uma arquitetura de mistura esparsa de especialistas, composta por oito grupos distintos de “especialistas”, totalizando 46,7 bilhões de parâmetros. Cada token utiliza até 12,9 bilhões de parâmetros, oferecendo desempenho que iguala ou supera o LLaMA 2 70B e o GPT-3.5 na maioria dos benchmarks. Veja exemplos de saída.
- Mistral Large – Um modelo de linguagem de alto desempenho com 123 bilhões de parâmetros e comprimento de contexto de 128.000 tokens. É fluente em vários idiomas, incluindo linguagens de programação, e demonstra desempenho competitivo com modelos como o LLaMA 3.1 405B, especialmente em tarefas relacionadas à programação. Saiba mais aqui.
Como adicionar o LLM Mistral ao seu fluxo
Você perceberá que todos os componentes LLM possuem apenas uma saída. A entrada não passa pelo componente, pois ele apenas representa o modelo, enquanto a geração de fato ocorre nos Agentes de IA e Geradores.
O conector LLM é sempre roxo. O conector de entrada LLM está presente em qualquer componente que utiliza IA para gerar texto ou processar dados. Você pode ver as opções clicando no conector:
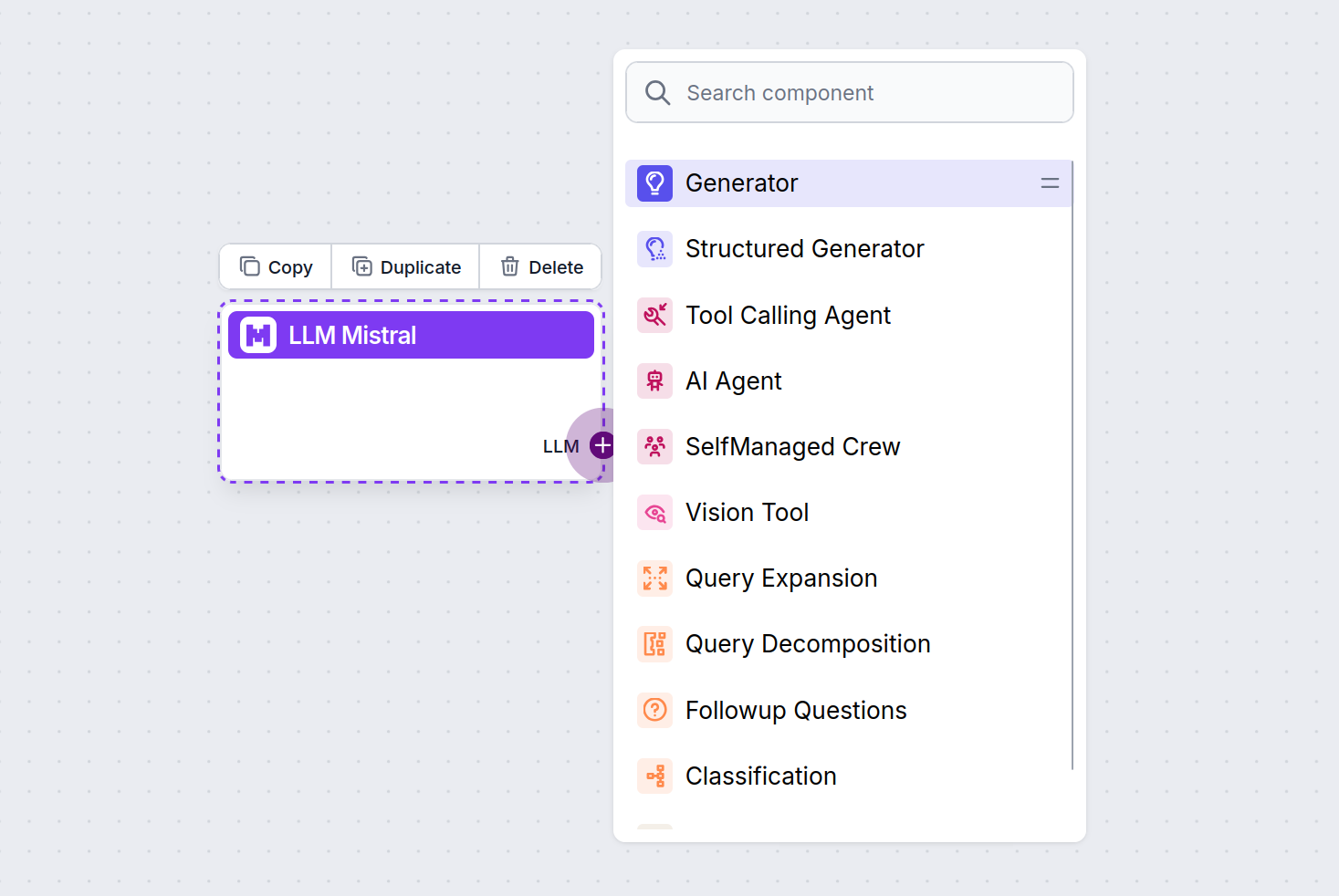
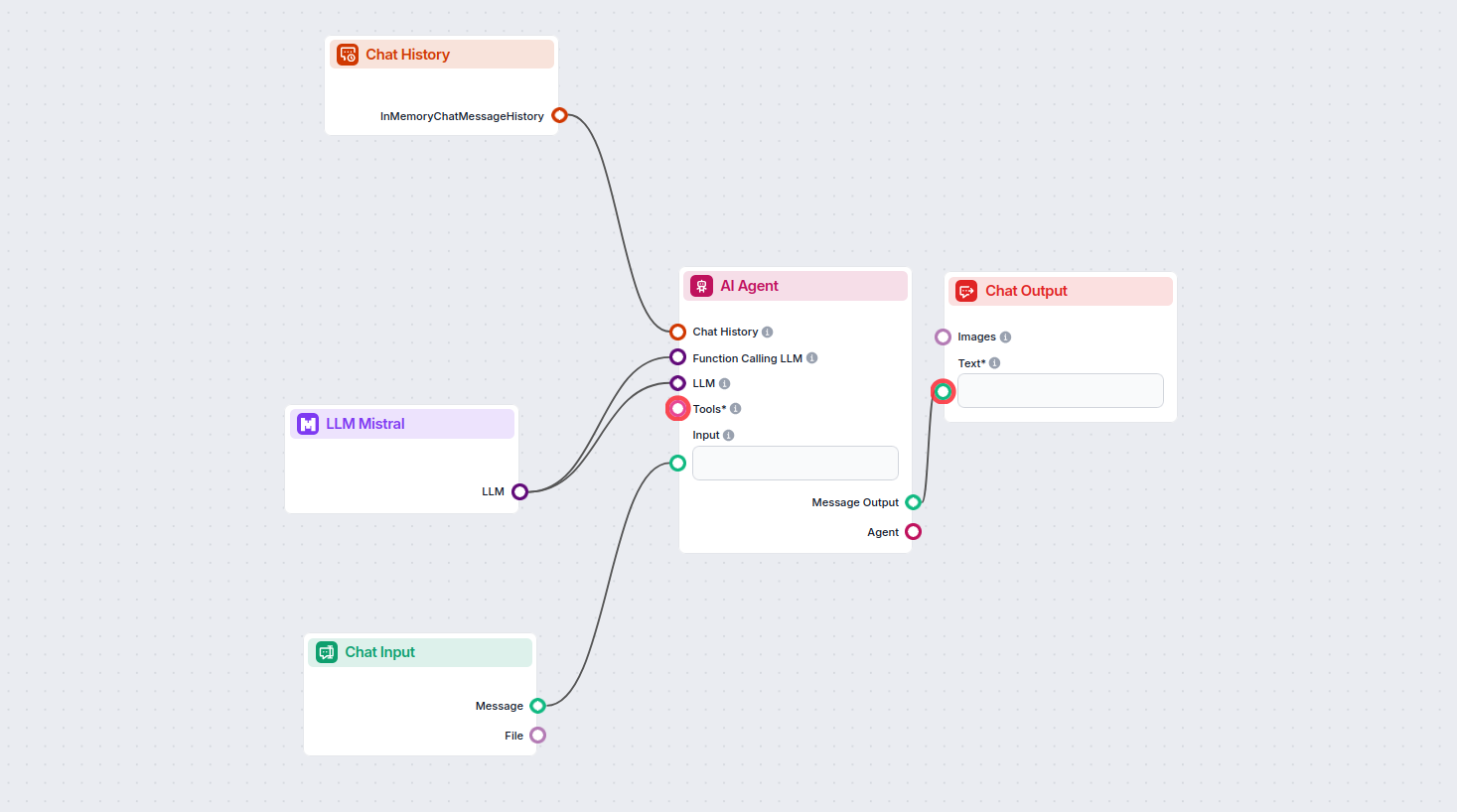
Isso permite criar todos os tipos de ferramentas. Vamos ver o componente em ação. Aqui está um fluxo simples de chatbot Agente de IA que utiliza o modelo Mistral 7B para gerar respostas. Você pode pensar nele como um chatbot básico da Mistral.
Este fluxo simples de Chatbot inclui:
- Entrada do chat: Representa a mensagem que o usuário envia no chat.
- Histórico do chat: Garante que o chatbot possa lembrar e considerar respostas anteriores.
- Saída do chat: Representa a resposta final do chatbot.
- Agente de IA: Um agente de IA autônomo que gera respostas.
- LLM Mistral: A conexão com os modelos de geração de texto da Mistral.
Perguntas frequentes
- O que é o componente LLM Mistral no FlowHunt?
O componente LLM Mistral permite conectar modelos de IA da Mistral aos seus projetos no FlowHunt, possibilitando geração avançada de texto para seus chatbots e agentes de IA. Ele permite trocar modelos, controlar configurações e integrar modelos como Mistral 7B, Mixtral (8x7B) e Mistral Large.
- Quais modelos Mistral são suportados pelo FlowHunt?
O FlowHunt suporta Mistral 7B, Mixtral (8x7B) e Mistral Large, cada um oferecendo diferentes níveis de desempenho e parâmetros para diversas necessidades de geração de texto.
- Quais configurações posso personalizar com o componente LLM Mistral?
Você pode ajustar configurações como tokens máximos e temperatura, além de selecionar entre os modelos Mistral suportados para controlar o tamanho das respostas, criatividade e comportamento do modelo em seus fluxos.
- É obrigatório conectar o componente LLM Mistral em todo projeto?
Não, conectar um componente LLM é opcional. Por padrão, os componentes do FlowHunt usam o ChatGPT-4o. Use o componente LLM Mistral quando quiser mais controle ou utilizar um modelo Mistral específico.
Experimente o LLM Mistral do FlowHunt hoje
Comece a criar chatbots e ferramentas de IA mais inteligentes integrando os poderosos modelos de linguagem da Mistral à plataforma no-code do FlowHunt.
Saiba mais

