

Descrição do componente
Como o componente LLM OpenAI funciona
O que é o componente LLM OpenAI?
O componente LLM OpenAI conecta modelos ChatGPT ao seu fluxo. Embora os Generators e Agents sejam onde a mágica realmente acontece, os componentes LLM permitem controlar o modelo utilizado. Todos os componentes vêm com o ChatGPT-4 por padrão. Você pode conectar este componente se desejar trocar o modelo ou ter mais controle sobre ele.
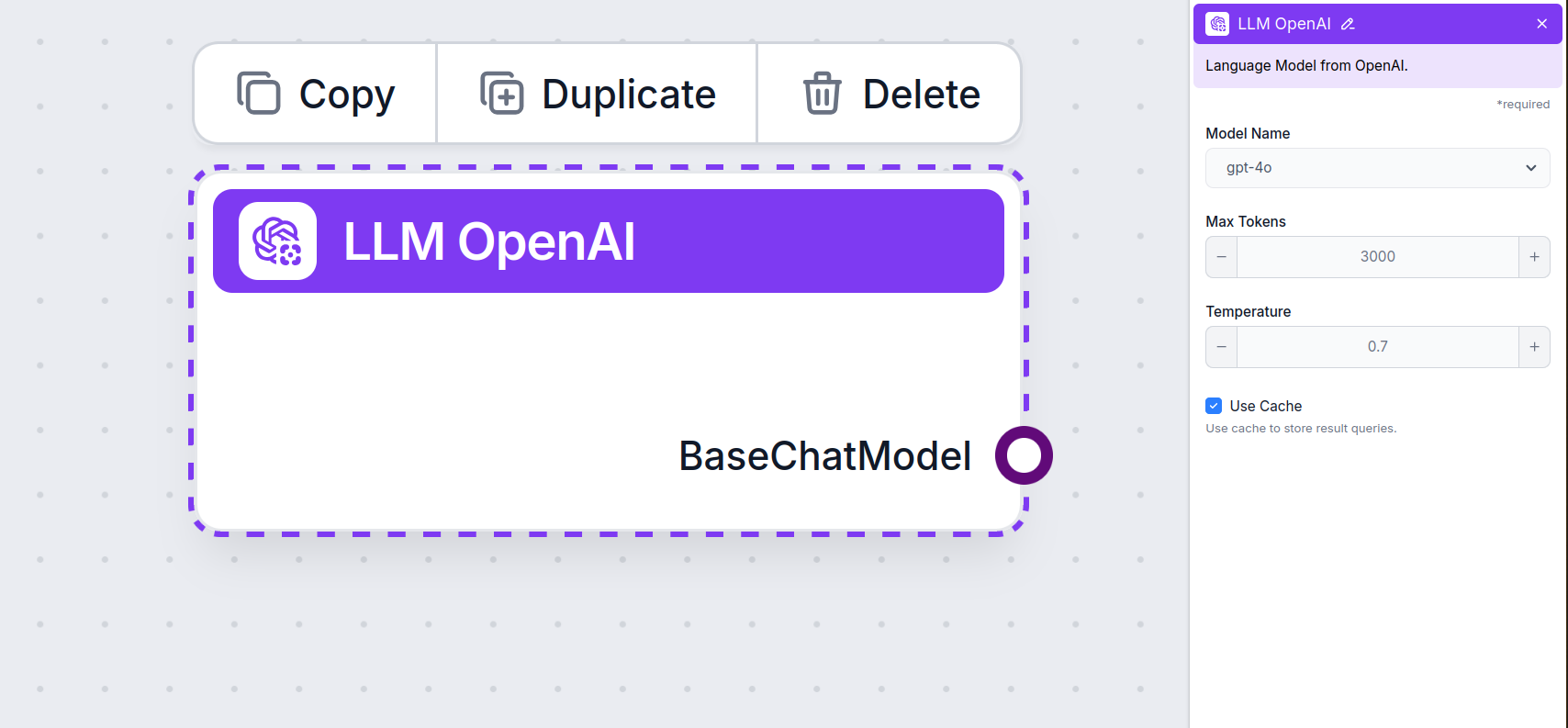
Configurações do Componente LLM OpenAI
Nome do Modelo
Este é o seletor de modelo. Aqui, você encontrará todos os modelos OpenAI suportados pelo FlowHunt. O ChatGPT oferece uma lista completa de modelos com capacidades e preços diferentes. Por exemplo, usar o GPT-3.5, menos avançado e mais antigo, custará menos do que usar o mais novo 4o, mas a qualidade e velocidade da resposta serão inferiores.
Modelos OpenAI disponíveis no FlowHunt:
- GPT-4o – O modelo mais recente e popular da OpenAI. Um modelo multimodal capaz de processar texto, imagens, áudio e fazer buscas na web. Saiba mais aqui.
- GPT-4o Mini – Uma versão menor e econômica do GPT-4o, oferecendo desempenho superior ao GPT-3.5 Turbo, com uma janela de contexto de 128K e redução de custos acima de 60%. Veja como lida com tarefas.
- o1 Mini – Uma versão enxuta do modelo o1, projetada para tarefas de raciocínio complexo, oferecendo equilíbrio entre desempenho e eficiência. Veja como se saiu em nossos testes.
- o1 Preview – Um modelo avançado com capacidades aprimoradas de raciocínio, destacando-se em resolução de problemas complexos, especialmente em codificação e raciocínio científico, disponível em formato de prévia. Veja como pensa e executa tarefas.
- gpt-4-vision-preview – Modelo de prévia que aceita entradas de texto e imagem, suportando recursos como modo JSON e chamadas de função paralela, ampliando as capacidades de interação multimodal. Descubra mais aqui.
- GPT-3.5 Turbo – Uma versão legada do GPT, excelente para tarefas simples sem gastar muito. Veja nossos testes de Agente de IA para compará-lo com modelos mais novos.
Ao escolher o modelo certo para a tarefa, considere a qualidade e velocidade que o trabalho exige. Modelos mais antigos são ótimos para economizar em tarefas em massa simples e chats. Se você estiver gerando conteúdo ou pesquisando na web, sugerimos optar por um modelo mais novo e refinado.
Máximo de Tokens
Tokens representam as unidades individuais de texto que o modelo processa e gera. O uso de tokens varia entre modelos, e um único token pode ser uma palavra, subpalavra ou um único caractere. Os modelos geralmente são tarifados por milhões de tokens.
A configuração de máximo de tokens limita o total de tokens que pode ser processado em uma única interação ou solicitação, garantindo que as respostas sejam geradas dentro de limites razoáveis. O limite padrão é de 4.000 tokens, tamanho ideal para resumir documentos e várias fontes para gerar uma resposta.
Temperatura
A temperatura controla a variabilidade das respostas, variando de 0 a 1.
Uma temperatura de 0,1 fará com que as respostas sejam muito objetivas, porém possivelmente repetitivas e deficientes.
Uma temperatura alta de 1 permite máxima criatividade nas respostas, mas cria o risco de respostas irrelevantes ou até alucinatórias.
Por exemplo, a temperatura recomendada para um bot de atendimento ao cliente é entre 0,2 e 0,5. Esse nível deve manter as respostas relevantes e dentro do roteiro, permitindo ao mesmo tempo um grau natural de variação nas respostas.
Como Adicionar o LLM OpenAI ao seu Fluxo
Você notará que todos os componentes LLM possuem apenas um conector de saída. A entrada não passa pelo componente, pois ele apenas representa o modelo, enquanto a geração real acontece nos Agentes de IA e Generators.
O conector LLM é sempre roxo. O conector de entrada LLM é encontrado em qualquer componente que usa IA para gerar texto ou processar dados. Você pode ver as opções clicando no conector:
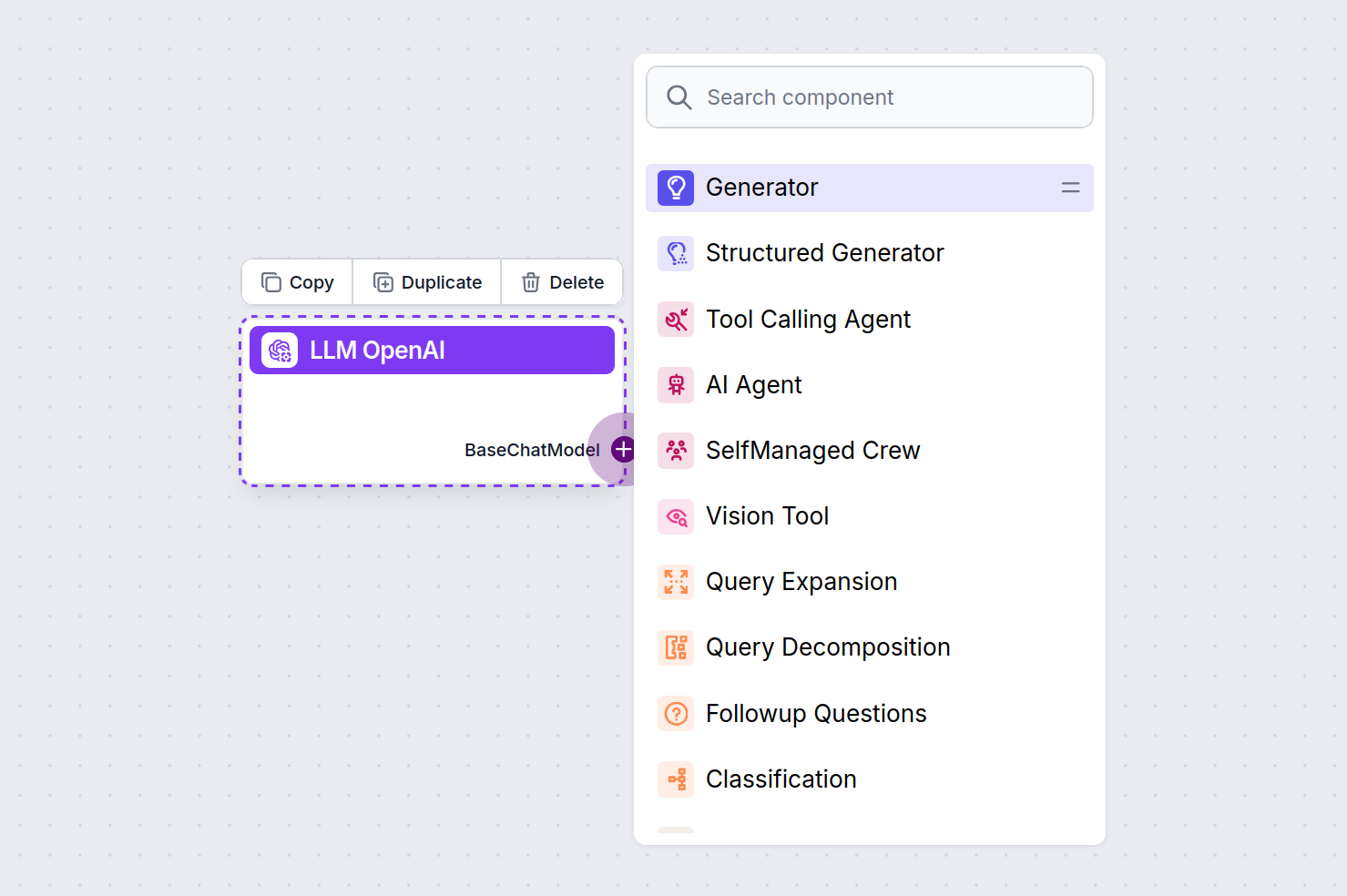
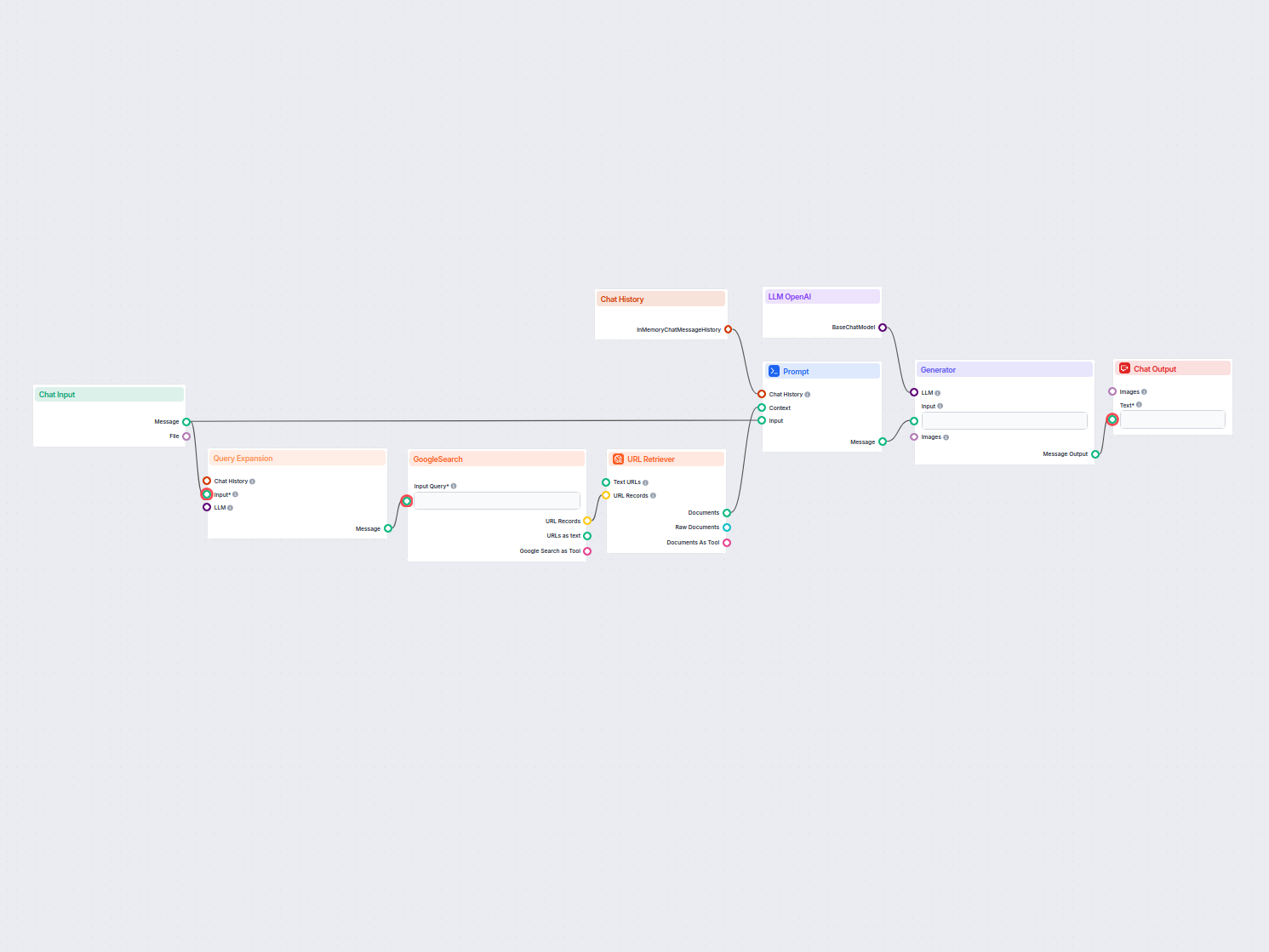
Isso permite criar todos os tipos de ferramentas. Vamos ver o componente em ação. Aqui está um fluxo simples de chatbot movido por Agente usando o o1 Preview para gerar respostas. Você pode pensar nele como um chatbot básico do ChatGPT.
Este fluxo simples de Chatbot inclui:
- Entrada de chat: Representa a mensagem que o usuário envia no chat.
- Histórico de chat: Garante que o chatbot possa lembrar e considerar respostas anteriores.
- Saída de chat: Representa a resposta final do chatbot.
- Agente de IA: Um agente de IA autônomo que gera respostas.
- LLM OpenAI: A conexão com os modelos de geração de texto da OpenAI.

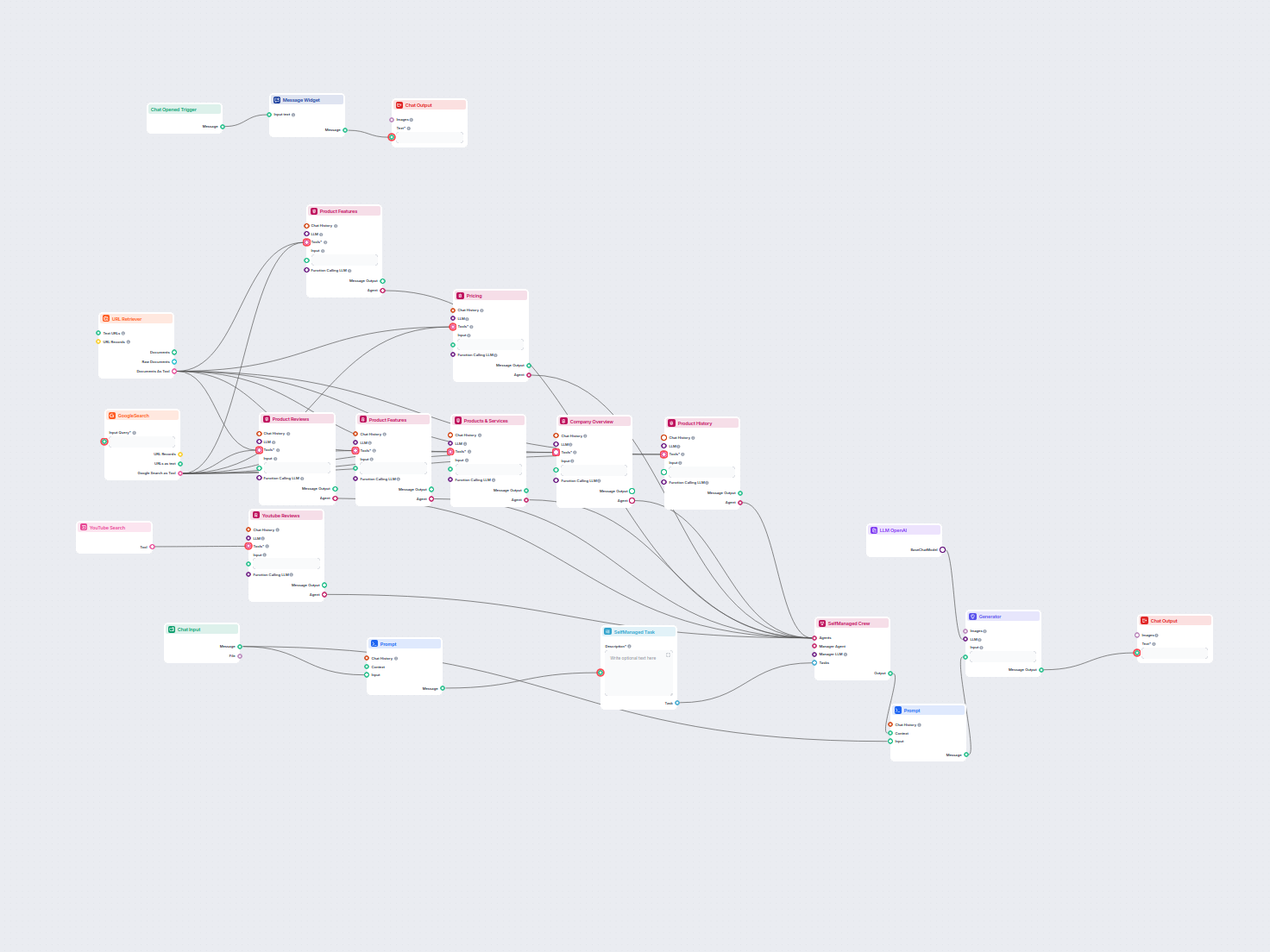
Exemplos de modelos de fluxo usando o componente LLM OpenAI
Para ajudá-lo a começar rapidamente, preparamos vários modelos de fluxo de exemplo que demonstram como usar o componente LLM OpenAI de forma eficaz. Esses modelos apresentam diferentes casos de uso e melhores práticas, tornando mais fácil para você entender e implementar o componente em seus próprios projetos.









Perguntas frequentes
- O que são LLMs?
Modelos de linguagem de grande porte são tipos de IA treinados para processar, compreender e gerar texto semelhante ao humano. Um exemplo comum é o ChatGPT, capaz de fornecer respostas elaboradas para quase qualquer pergunta.
- Posso conectar um LLM diretamente à Saída do Chat?
Não, o componente LLM é apenas uma representação do modelo de IA. Ele altera o modelo que o Generator utilizará. O LLM padrão no Generator é o ChatGPT-4o.
- Quais LLMs estão disponíveis nos Flows?
No momento, apenas o componente OpenAI está disponível. Planejamos adicionar mais no futuro.
- Preciso adicionar um LLM ao meu fluxo?
Não, os Flows são um recurso versátil com muitos casos de uso sem a necessidade de um LLM. Você adiciona um LLM se quiser criar um chatbot conversacional que gere respostas de texto livremente.
- O componente LLM OpenAI gera a resposta?
Na verdade, não. O componente apenas representa o modelo e cria regras para ele seguir. É o componente generator que faz a conexão com a entrada e executa a consulta pelo LLM para criar a saída.
Pronto para criar sua própria IA?
Chatbots inteligentes e ferramentas de IA em um só lugar. Conecte blocos intuitivos para transformar suas ideias em Flows automatizados.
Saiba mais


